Storm的官方网址:http://storm.apache.org/index.html
1:什么是Storm?
Storm是一个开源的分布式实时计算系统,可以简单、可靠的处理大量的数据流。被称作“实时的hadoop”。Storm有很多使用场景:如实时分析,在线机器学习,持续计算, 分布式RPC,ETL等等。Storm支持水平扩展,具有高容错性,保证每个消息都会得到处理,而且处理速度很快(在一个小集群中,每个结点每秒可以处理 数以百万计的消息)。Storm的部署和运维都很便捷,而且更为重要的是可以使用任意编程语言来开发应用。
2:Storm的特点:
(1)编程模型简单 在大数据处理方面相信大家对hadoop已经耳熟能详,基于Google Map/Reduce来实现的Hadoop为开发者提供了map、reduce原语,使并行批处理程序变得非常地简单和优美。 同样,Storm也为大数据 的实时计算提供了一些简单优美的原语,这大大降低了开发并行实时处理的任务的复杂性,帮助你快速、高效的开发应用。 (2)可扩展 在Storm集群中真正运行topology的主要有三个实体:工作进程、线程和任务。Storm集群中的每台机器上都可以运行多个工作进程,每个 工作进程又可创建多个线程,每个线程可以执行多个任务,任务是真正进行数据处理的实体,我们开发的spout、bolt就是作为一个或者多个任务的方式执 行的。 因此,计算任务在多个线程、进程和服务器之间并行进行,支持灵活的水平扩展。 (3)高可靠性 Storm可以保证spout发出的每条消息都能被“完全处理”,这也是直接区别于其他实时系统的地方,如S4。 spout发出的消息后续可能会触发产生成千上万条消息,可以形象的理解为一棵消息树,其中spout发出的消息为树根,Storm会跟踪 这棵消息树的处理情况,只有当这棵消息树中的所有消息都被处理了,Storm才会认为spout发出的这个消息已经被“完全处理”。如果这棵消息树中的任 何一个消息处理失败了,或者整棵消息树在限定的时间内没有“完全处理”,那么spout发出的消息就会重发。 (4)高容错性 如果在消息处理过程中出了一些异常,Storm会重新安排这个出问题的处理单元。Storm保证一个处理单元永远运行(除非你显式杀掉这个处理单元)。 当然,如果处理单元中存储了中间状态,那么当处理单元重新被Storm启动的时候,需要应用自己处理中间状态的恢复。 (5)Storm集群和Hadoop集群表面上看很类似。Hadoop上运行的是MapReduce jobs,而在Storm上运行的是拓扑(topology); Hadoop擅长于分布式离线批处理,而Storm设计为支持分布式实时计算; Hadoop新的spark组件提供了在hadoop平台上运行storm的可能性
3:Storm的基本概念:
在深入理解Storm之前,需要了解一些概念:
Topologies : 拓扑,也俗称一个任务,拓扑
Spouts : 拓扑的消息源,Spout消息源
Bolts : 拓扑的处理逻辑单元,Bolt消息处理者
tuple:消息元组
Streams : 流
Stream groupings :流的分组策略,数据的分发方式
Tasks : 任务处理单元,执行具体逻辑的任务
Executor :工作线程,执行Task的线程
Workers :工作进程
Configuration : topology的配置,配置
4:Storm与Hadoop的对比:
(1)Topology 与 Mapreduce : 一个关键的区别是: 一个MapReduce job最终会结束, 而一个topology永远会运行(除非你手动kill掉) (2)Nimbus 与 ResourManager: 在Storm的集群里面有两种节点: 控制节点(master node)和工作节点(worker node)。控制节点上面运行一个叫Nimbus后台程序,它的作用类似Hadoop里面的JobTracker。Nimbus负责在集群里面分发代码,分配计算任务给机器, 并且监控状态。 (3)Supervisor (worker进程)与NodeManager(YarnChild): 每一个工作节点上面运行一个叫做Supervisor的节点。Supervisor会监听分配给它那台机器的工作,根据需要启动/关闭工作进程。每一个工作进程执行一个topology的一个子集;一个运行的topology由运行在很多机器上的很多工作进程组成。
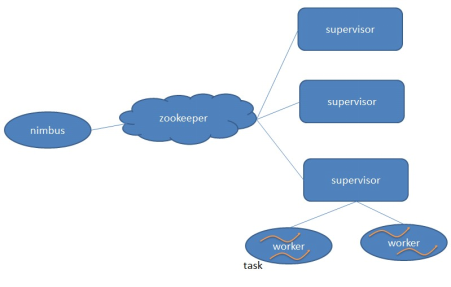
5:Storm 体系架构:
(1)Nimbus和Supervisor之间的所有协调工作都是通过Zookeeper集群完成。: (2)Nimbus进程和Supervisor进程都是快速失败(fail-fast)和无状态的。所有的状态要么在zookeeper里面, 要么在本地磁盘上。 (3)这也就意味着你可以用kill -9来杀死Nimbus和Supervisor进程, 然后再重启它们,就好像什么都没有发生过。这个设计使得Storm异常的稳定。
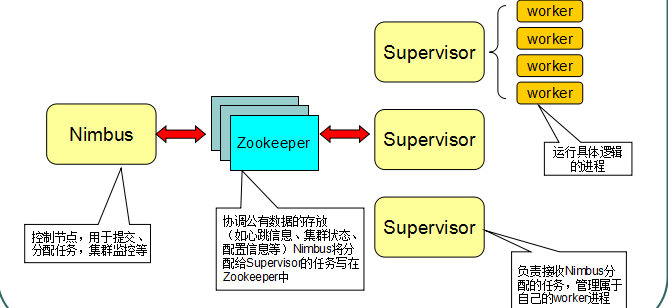
5.1:Storm中的Nimbus和Supervisor:
Storm节点作用解释如下所示:
1:在Storm的集群里面有两种节点:控制节点和工作节点。控制节点上面运行一个叫Nimbus进程,Nimbus负责在集群里面分发代码,分配计算任务,并且监控状态。
2:每一个工作节点上面运行一个叫做Supervisor进程。Supervisor负责监听从Nimbus分配给它执行的任务,据此启动或停止执行任务的工作进程
3:Nimbus和Supervisor之间的所有协调工作都是通过Zookeeper集群完成。
5.2:Storm中的Topologies:
一个topology是spouts和bolts组成的图, 通过stream groupings将图中的spouts和bolts连接起来,如下图:
一个实时计算应用程序的逻辑在storm里面被封装到topology对象里面, 我把它叫做计算拓补. Storm里面的topology相当于Hadoop里面的一个MapReduce Job, 它们的关键区别是:一个MapReduce Job最终总是会结束的, 然而一个storm的topoloy会一直运行 — 除非你显式的杀死它。 一个Topology是Spouts和Bolts组成的图状结构, 而链接Spouts和Bolts的则是Stream groupings。
Storm里面各个对象的示意图: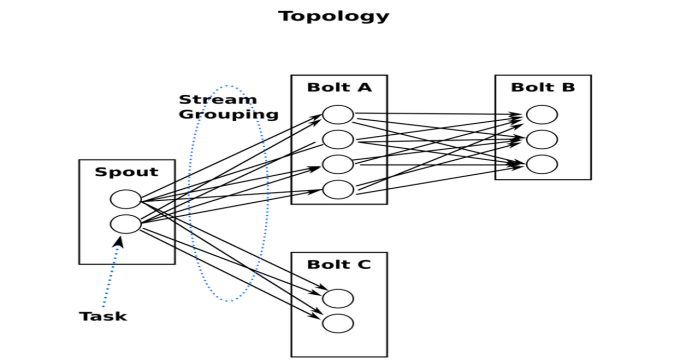
5.3:Storm中的Stream
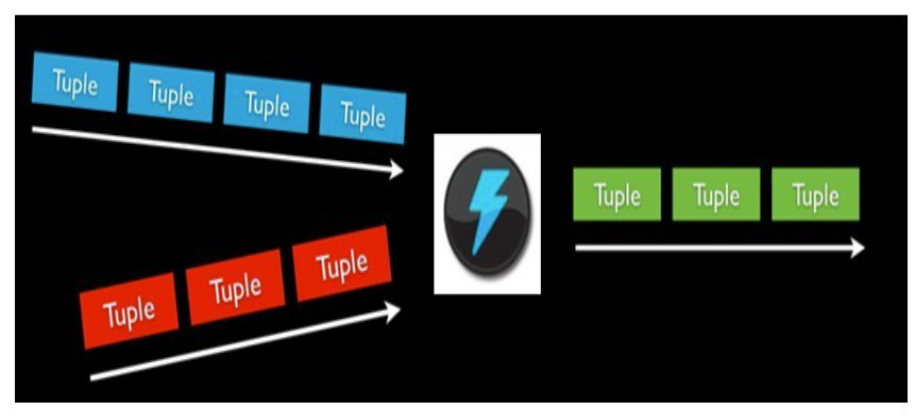
消息流stream是storm里的关键抽象; 一个消息流是一个没有边界的tuple序列, 而这些tuple序列会以一种分布式的方式并行地创建和处理; 通过对stream中tuple序列中每个字段命名来定义stream; 在默认的情况下,tuple的字段类型可以是:integer,long,short, byte,string,double,float,boolean和byte array; 可以自定义类型(只要实现相应的序列化器)。
5.4:Storm中的Spouts
1:消息源spout是Storm里面一个topology里面的消息生产者;
一般来说消息源会从一个外部源读取数据并且向topology里面发出消息:tuple;
Spouts可以是可靠的也可以是不可靠的:如果这个tuple没有被storm成功处理,可靠的消息源spouts可以重新发射一个tuple, 但是不可靠的消息源spouts一旦发出一个tuple就不能重发了;
2:消息源可以发射多条消息流stream:
使用OutputFieldsDeclarer.declareStream来定义多个stream,
然后使用SpoutOutputCollector来发射指定的stream。
3:Spout方法调用顺序:
1、declareOutputFields()(调用一次)
2、open() (调用一次)
3、activate() (调用一次)
4、nextTuple() (循环调用 )
5、deactivate() (手动调用)
5.4:Storm中的Bolts
1:所有的消息处理逻辑被封装在bolts里面; Bolts可以做很多事情:过滤,聚合,查询数据库等等。 Bolts可以简单的做消息流的传递,也可以通过多级Bolts的组合来完成复杂的消息流处理;比如求TopN、聚合操作等(如果要把这个过程做得更具有扩展性那么可能需要更多的步骤)。 Bolts可以发射多条消息流: 使用OutputFieldsDeclarer.declareStream定义stream; 使用OutputCollector.emit来选择要发射的stream; Bolts的主要方法是execute,: 它以一个tuple作为输入,使用OutputCollector来发射tuple; 通过调用OutputCollector的ack方法,以通知这个tuple的发射者spout; Bolts一般的流程: 处理一个输入tuple, 发射0个或者多个tuple, 然后调用ack通知storm自己已经处理过这个tuple了;
storm提供了一个IBasicBolt会自动调用ack。
2:Bolt方法调用顺序:
1、declareOutputFields() (调用一次)
2、prepare() (调用一次)
3、execute() (循环执行)
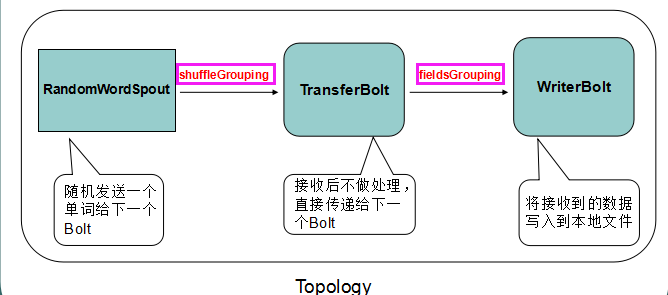
5.5:Storm中的Stream groupings(消息分发策略)
定义一个topology的关键一步是定义每个bolt接收什么样的流作为输入;
stream grouping就是用来定义一个stream应该如何分配数据给bolts;
Storm里面有7种类型的stream grouping:
1、Shuffle Grouping——随机分组, 随机派发stream里面的tuple,保证每个bolt接收到的tuple数目大致相同;
2、Fields Grouping——按字段分组, 比如按userid来分组, 具有同样userid的tuple会被分到相同的Bolts里的一个task, 而不同的userid则会被分配到不同的bolts里的task;
3、All Grouping——广播发送,对于每一个tuple,所有的bolts都会收到;
4、Global Grouping——全局分组, 这个tuple被分配到storm中的一个bolt的其中一个task。再具体一点就是分配给id值最低的那个task;
5、Non Grouping——不分组,这个分组的意思是说stream不关心到底谁会收到它的tuple。目前这种分组和Shuffle grouping是一样的效果, 有一点不同的是storm会把这个bolt放到这个bolt的订阅者同一个线程里面去执行;
6、Direct Grouping——直接分组, 这是一种比较特别的分组方法,用这种分组意味着消息的发送者指定由消息接收者的哪个task处理这个消息。 只有被声明为Direct Stream的消息流可以声明这种分组方法。而且这种消息tuple必须使用emitDirect方法来发射。
消息处理者可以通过TopologyContext来获取处理它的消息的task的id (OutputCollector.emit方法也会返回task的id);
7、Local or shuffle grouping——如果目标bolt有一个或者多个task在同一个工作进程中,tuple将会被随机发生给这些tasks。否则,和普通的Shuffle Grouping行为一致。
5.6:Storm中的Workers
1:一个topology可能会在一个或者多个worker(工作进程)里面执行;
每个worker是一个物理JVM并且执行整个topology的一部分;
比如,对于并行度是300的topology来说,如果我们使用50个工作进程来执行,那么每个工作进程会处理其中的6个tasks;
Storm会尽量均匀的工作分配给所有的worker;
2:Supervisor会监听分配给它那台机器的工作,根据需要启动/关闭工作进程,这个工作进程就是worker
3:每一个worker都会占用工作节点的一个端口,这个端口可以在storm.yarm中配置。
4:一个topology可能会在一个或者多个工作进程里面执行,每个工作进程执行整个topology的一部分,所以一个运行的topology由运行在很多机器上的很多工作进程组成。
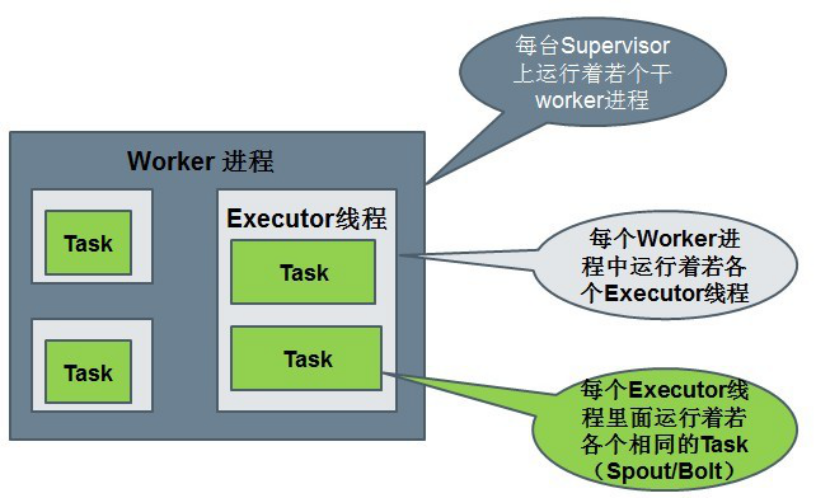
5.7:Storm中的Tasks
每一个spout和bolt会被当作很多task在整个集群里执行
每一个executor对应到一个线程,在这个线程上运行多个task
stream grouping则是定义怎么从一堆task发射tuple到另外一堆task
可以调用TopologyBuilder类的setSpout和setBolt来设置并行度(也就是有多少个task)
5.8:配置Configuration
storm里面有一堆参数可以配置来调整nimbus, supervisor以及正在运行的topology的行为, 一些配置是系统级别的, 一些配置是topology级别的。所有有默认值的配置的默认配置是配置在default.xml里面的。你可以通过定义个storm.xml在你的classpath来覆盖这些默认配置。并且你也可以在代码里面设置一些topology相关的配置信息 – 使用StormSubmitter。当然,这些配置的优先级是: default.xml < storm.xml < TOPOLOGY-SPECIFIC配置。
6:离线计算是什么?流式计算是什么?
1:离线计算是什么? 离线计算:批量获取数据、批量传输数据、周期性批量计算数据、数据展示 代表技术:Sqoop批量导入数据、HDFS批量存储数据、MapReduce批量计算数据、Hive批量计算数据、azkaban任务调度 1,hivesql 2、调度平台 3、Hadoop集群运维 4、数据清洗(脚本语言) 5、元数据管理 6、数据稽查 7、数据仓库模型架构 2:流式计算是什么 流式计算:数据实时产生、数据实时传输、数据实时计算、实时展示 代表技术:Flume实时获取数据、Kafka/metaq实时数据存储、Storm/JStorm实时数据计算、Redis实时结果缓存、持久化存储(mysql)。 一句话总结:将源源不断产生的数据实时收集并实时计算,尽可能快的得到计算结果 3:离线计算与实时计算的区别 最大的区别:实时收集、实时计算、实时展示 4:Storm是什么? Flume实时采集,低延迟 Kafka消息队列,低延迟 Storm实时计算,低延迟 Redis实时存储,低延迟 Storm用来实时处理数据,特点:低延迟、高可用、分布式、可扩展、数据不丢失。提供简单容易理解的接口,便于开发。 海量数据?数据类型很多,产生数据的终端很多,处理数据能力增强 5:Storm与Hadoop的区别 Storm用于实时计算,Hadoop用于离线计算。 Storm处理的数据保存在内存中,源源不断;Hadoop处理的数据保存在文件系统中,一批一批。 Storm的数据通过网络传输进来;Hadoop的数据保存在磁盘中。 Storm与Hadoop的编程模型相似
6:Storm应用场景及行业案例
Storm用来实时计算源源不断产生的数据,如同流水线生产。
运用场景:
日志分析
从海量日志中分析出特定的数据,并将分析的结果存入外部存储器用来辅佐决策。
管道系统
将一个数据从一个系统传输到另外一个系统,比如将数据库同步到Hadoop
消息转化器
将接受到的消息按照某种格式进行转化,存储到另外一个系统如消息中间件
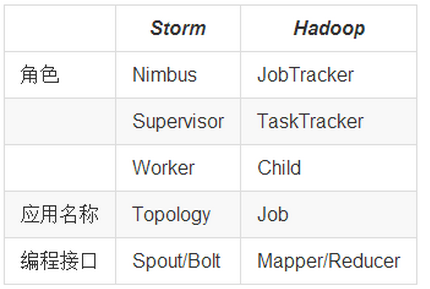
Job:任务名称 JobTracker:项目经理 TaskTracker:开发组长、产品经理 Child:负责开发的人员 Mapper/Reduce:开发人员中的两种角色,一种是服务器开发、一种是客户端开发 Topology:任务名称 Nimbus:项目经理 Supervisor:开组长、产品经理 Worker:开人员 Spout/Bolt:开人员中的两种角色,一种是服务器开发、一种是客户端开发
7、Storm核心组件:
Nimbus:负责资源分配和任务调度。Nimbus任务分配,对任务监控。 Supervisor:负责接受nimbus分配的任务,启动和停止属于自己管理的worker进程。---通过配置文件设置当前supervisor上启动多少个worker。Supervisor当前物理机器上的管理者,接受Nimbus分配的任务,启动自己的Worker,Worker数量是根据端口号来的。 Worker:运行具体处理组件逻辑的进程。Worker运行的任务类型只有两种,一种是Spout任务,一种是Bolt任务。Worker执行具体任务的组件,任务类型有两种,分别是Spout任务,bolt任务,一个worker中可能同时存在多个spout任务和多个bolt任务。 Task:worker中每一个spout/bolt的线程称为一个task. 在storm0.8之后,task不再与物理线程对应,不同spout/bolt的task可能会共享一个物理线程,该线程称为executor。Task是Spout任务,bolt任务,每个Task属于某个组件并发度中的一个。一个Task本质是一个线程。
默认情况下,executor=thread=task
并发度:一个类型的任务,被几个线程同时执行。
8、Storm编程模型:

Topology:Storm中运行的一个实时应用程序的名称。(拓扑)
Spout:在一个topology中获取源数据流的组件。
通常情况下spout会从外部数据源中读取数据,然后转换为topology内部的源数据。spout获取外部数据源。
Bolt:接受数据然后执行处理的组件,用户可以在其中执行自己想要的操作。bolt业务逻辑处理节点,可以存在多个,将结果数据保存到redis上面,bolt是并发执行的,多个线程在同时做意见事情。
Tuple:一次消息传递的基本单元,理解为一组消息就是一个Tuple。tuple消息发送的最小单元,是一个tuple对象,对象有一个list。
Stream:表示数据的流向。streamGroup数据分组策略。
一个storm程序可以获取多个数据源。
一个topology的数据是自己独有的,和其他的topology没有关系。
9:Storm架构和编程模型总结:
1、编程模型 DataSource:外部数据源 Spout:接受外部数据源的组件,将外部数据源转化成Storm内部的数据,以Tuple为基本的传输单元下发给Bolt Bolt:接受Spout发送的数据,或上游的bolt的发送的数据。根据业务逻辑进行处理。发送给下一个Bolt或者是存储到某种介质上。介质可以是Redis可以是mysql,或者其他。 Tuple:Storm内部中数据传输的基本单元,里面封装了一个List对象,用来保存数据。 StreamGrouping:数据分组策略 7种:shuffleGrouping(Random函数),Non Grouping(Random函数),FieldGrouping(Hash取模)、Local or ShuffleGrouping 本地或随机,优先本地。 2、并发度 用户指定的一个任务,可以被多个线程执行,并发度的数量等于线程的数量。一个任务的多个线程,会被运行在多个Worker(JVM)上,有一种类似于平均算法的负载均衡策略。尽可能减少网络IO,和Hadoop中的MapReduce中的本地计算的道理一样。 3、架构 Nimbus:任务分配 Supervisor:接受任务,并启动worker。worker的数量根据端口号来的。 Worker:执行任务的具体组件(其实就是一个JVM),可以执行两种类型的任务,Spout任务或者bolt任务。 Task:Task=线程=executor。 一个Task属于一个Spout或者Bolt并发任务。 Zookeeper:保存任务分配的信息、心跳信息、元数据信息。 4、Worker与topology 一个worker只属于一个topology,每个worker中运行的task只能属于这个topology。 反之,一个topology包含多个worker,其实就是这个topology运行在多个worker上。 一个topology要求的worker数量如果不被满足,集群在任务分配时,根据现有的worker先运行topology。如果当前集群中worker数量为0,那么最新提交的topology将只会被标识active,不会运行,只有当集群有了空闲资源之后,才会被运行。
5、为什么需要消息完整处理这种机制
storm有一种机制可以保证从spout发出的每个tuple都会被完全处理。
在一些特定的业务是,丢失一条消息是非常可怕的,也是业务不允许的。
6、理解消息被完整处理
一个消息(tuple)从spout发送出来,可能会导致成百上千的消息基于此消息被创建
“单词统计”的例子:
storm任务从数据源每次读取一个完整的英文句子;将这个句子分解为独立的单词,最后,实时的输出每个单词以及它出现过的次数。
每个从spout发送出来的消息(每个英文句子)都会触发很多的消息被创建,那些从句子中分隔出来的单词就是被创建出来的新消息。
这些消息构成一个树状结构,我们称之为“tuple tree”。
7、在什么条件下,Storm才会认为一个从spout发送出来的消息被完整处理呢?
tuple tree不再生长
树中的任何消息被标识为“已处理”
8、使用Storm提供的可靠处理特性:
无论何时在tuple tree中创建了一个新的节点,我们需要明确的通知Storm;
当处理完一个单独的消息时,我们需要告诉Storm 这棵tuple tree的变化状态。
通过上面的两步,storm就可以检测到一个tuple tree何时被完全处理了,并且会调用相关的ack或fail方法。
锚定(anchoring)
9:Storm常用操作命令(有许多简单且有用的命令可以用来管理拓扑,它们可以提交、杀死、禁用、再平衡拓扑。):
一:提交任务命令格式:storm jar 【jar路径】 【拓扑包名.拓扑类名】 【拓扑名称】;
例如:bin/storm jar examples/storm-starter/storm-starter-topologies-0.9.6.jar storm.starter.WordCountTopology wordcount
二:杀死任务命令格式:storm kill 【拓扑名称】 -w 10(执行kill命令时可以通过-w [等待秒数]指定拓扑停用以后的等待时间)
例如:storm kill topology-name -w 10
三:停用任务命令格式:storm deactivte 【拓扑名称】
例如:storm deactivte topology-name
四:我们能够挂起或停用运行中的拓扑。当停用拓扑时,所有已分发的元组都会得到处理,但是spouts的nextTuple方法不会被调用。销毁一个拓扑,可以使用kill命令。它会以一种安全的方式销毁一个拓扑,首先停用拓扑,在等待拓扑消息的时间段内允许拓扑完成当前的数据流。
启用任务命令格式:storm activate【拓扑名称】:storm activate topology-name
重新部署任务命令格式:storm rebalance 【拓扑名称】:storm rebalance topology-name
再平衡使你重分配集群任务。这是个很强大的命令。比如,你向一个运行中的集群增加了节点。再平衡命令将会停用拓扑,然后在相应超时时间之后重分配工人,并重启拓扑。
10:流式计算一般架构图(重要)

解释说明:
1、Flume:其中flume用来获取数据。
2、Kafka:用来临时保存数据。
3、Strom:用来计算数据。
4、Redis:是个内存数据库,用来保存数据。
待续......