一、从LR到决策树
0.思考一些一个分类问题:是否去相亲,LR解决的问题可能是这样的
在下面各个特征下给定w1,w2,w3,w4等参数值,将wx+b送到sigmoid函数中去,拿到一个概率p,我们在使用这个函数的时候会有一个损失函数loss function,对于这个代价函数通过GD梯度下降完成优化,拿到最好的w
2.是否去相亲,有时候人更直观的方式是这样的。

3.决策模型是模拟人类决策过程的思想的模型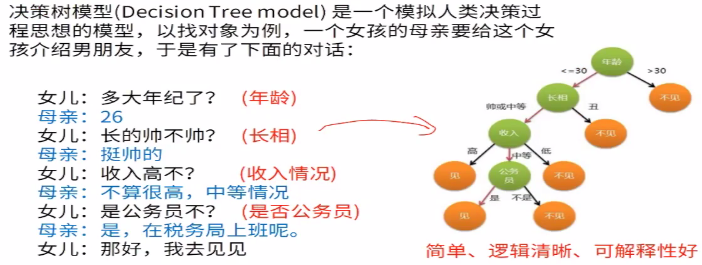
3.总体流程与核心问题
(1)决策树是基于“树”结构进行决策
每个“内部结点”对应于某个属性上的“测试”,内部结点对应于上图的绿色节点,针对某个条件做的判断,第一个绿色节点对年龄做了判断,第二个绿色节点对长相做了判断,第三个绿色节点对收入做了判断,最下面的绿色节点对公务员做了判断,每个分支对应于一种预测的结果,
每个分支节点对应于该测试的一种可能结果(即该属性的某个取值)
每个“叶节点”,对应于一个预测结果
(2)学习过程:
通过对训练样本的分析来确定“划分属性”(内部节点对应的属性)
(3)预测过程:将测试示例从根节点开始,沿着划分属性所构成的“判定测试序列”下行,直到叶节点
(4)总体流程:
“分而治之”(divide-and-conquer)
自根至叶的递归过程
在每个中间节点寻找一个“划分”(split or test)属性

(5)三种停止条件:
当前结点包含的样本全属于同一类别,无需划分
当前属性集为空,或者所有样本在所有属性上取值相同,无法划分
当前节点包含的样本集合为空,不能划分。
4.熵、信息增益、信息增益率
(1)熵:信息熵(entropy)是度量样本集合的“纯度”最常用的一种指标,假定当前样本集合D中第K类样本所占的比例为pk,则D的信息熵定义为:k是标签的种类个数,

Ent(D)的值越小,则D的纯度越高,纯度最低,不确定度最高,Ent(D)越大,不纯度越高,在每个类别的比例一样的时候,取到的值是最大的 ,这个时候最不肯定,完全不知道自己摸出来的球是什么样的颜色。信息增益直接以信息熵为基础,计算当前划分对信息熵所造成的变化。计算信息熵时约定:若p=0,则plog2p=0,Ent(D)的最小值为0,最大值为log2|y|
为什么需要机器学习模型?机器学习模型是为了干什么?是为了做预估,提前预估出结果,如果模型做的足够好,就会把不确定度降得足够低。
5.最佳划分属性选择:信息增益
(1)信息增益(information gain):ID3中使用。ID3对有特别多取值的属性有特别强的偏好,分叉分的越多,桶里面的元素越少,越肯定,所以特别喜欢去挑分叉特别多的属性,

第v个分支的权重,样本越多越重要。
比如电商购物中有很多衣服的颜色,这些衣服的颜色分别是红、黄、蓝三色,机器学习模型是为了将不纯度降低,希望越来越纯。买衣服的小姐姐有的买了有的没有买,可以根据这个计算信息熵不确定性。可以根据颜色将衣服分为三份,每份都有一些样本,因为按照这个区进行区分了,所以肯定度有可能会变高。前面的Ent(D)是划分以前的信息熵,后面的是新分成的三份,每份中的不确定性,但是样本数减少了,所以要给这些进行一个加权,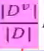 Dv是基于这种颜色来买衣服的人数,D是总共买衣服的人数
Dv是基于这种颜色来买衣服的人数,D是总共买衣服的人数
(2)信息增益示例:
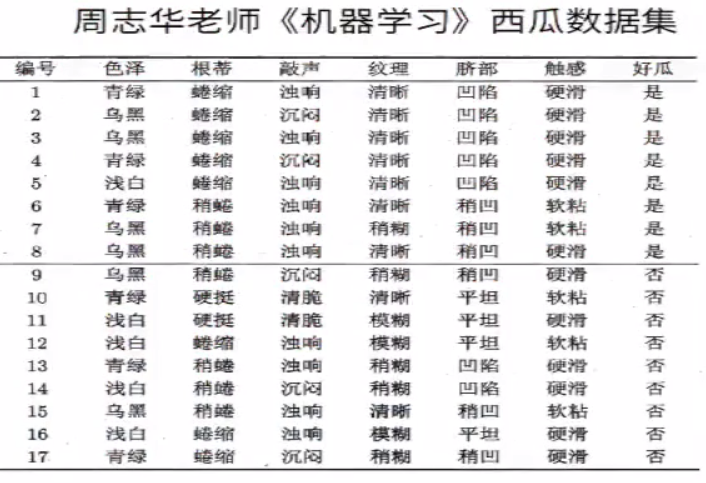
该数据集包含17个训练样例,结果有两个类别,|y|=2,其中正例占P1=8/17,反例占9/17。所以根节点的信息熵为:

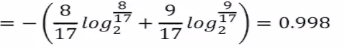
信息熵为0.998,说明不确定度比较高,不纯度比较高。
以属性“色泽”为例,其对应的3个数据子集分别为D1(色泽=青绿),D2(色泽=乌黑),D3(色泽=浅白)
子集D1包含编号为{1,4,6,10,13,17}的6个样例,其中正例占p1=3/6,反例占p2=3/6,D2,D3同理,3个节点的信息熵为:

属性“色泽” 的信息增益为:

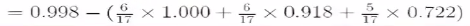 =0.109,信息熵降低了0.109,后面一部分是划分之后的不纯度,基于颜色划分之后,计算得到的加权的不确定度。不确定度降低了0.109。
=0.109,信息熵降低了0.109,后面一部分是划分之后的不纯度,基于颜色划分之后,计算得到的加权的不确定度。不确定度降低了0.109。

决策树朝着不确定度下降最多的方向去增长。
6.最佳划分属性的选择:信息增益率
(1)信息增益率(gain ratio):C4.5中使用
(2)信息增益的问题:对可取值数目较多的属性有所偏好。
例如:考虑将“编号”作为一个属性
(3)信息增益率:
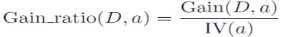
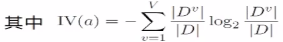
属性a的可能取值数目越多(即V越大),则IV(a)的值通常就越大
启发式:先从候选属性中找出信息增益高于平均水平的,再从其中选择增益率最该的。
7.基尼指数:
(1)基尼指数:CART中使用,是一个二叉树,划分的指标是基尼系数。两次摸出来都是黑球和两次摸出来都是白球的概率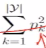 ,用
,用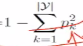 ,最后的出来的是不纯度,我们要找到在划分属性之后,找到基尼系数最小的属性。
,最后的出来的是不纯度,我们要找到在划分属性之后,找到基尼系数最小的属性。


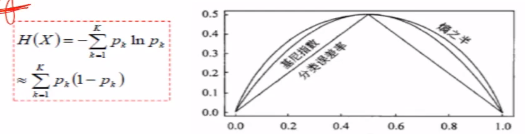
8.基尼指数vs熵vs分类错误率
(1)基尼指数、熵、分类错误率三者之间的关系:
将f(x)=-lnx在x=1处一阶泰勒展开,忽略高阶无穷小,得到f(x)=1-x
9.二分类视角看CART
(1)每一个产生分支的过程就是一个二分类的过程
(2)这个过程叫做“决策树桩”:decision stump
(3)一棵CART是由许多决策树桩拼接起来的。
(4)decision stump是只有一层的决策树
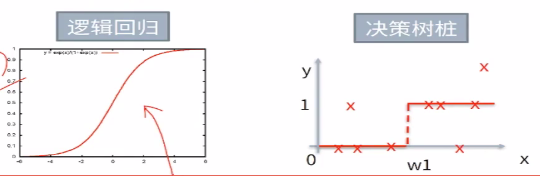
10.三种不同的决策树
(1)ID3:取值多的属性,更容易使数据更纯,其信息增益更大
(2)C4.5:采用信息增益率替代信息增益
(3)CART:以基尼系数替代熵,最小化不纯度,而不是最大化信息增益
11.连续值使用信息增益计算
(1)把连续值年龄变成了很多二分的离散属性,对这么多的二值属性 用同样的方式去选择,把不同的属性去做选择。
(2)并行做计算。
二、回归树
1.构建回归树。假设有这样的一棵回归树(不管是决策树还是回归树,都是拿起一把刀,对垂直于坐标轴方向砍几刀,把整个空间砍成一堆的小矩形 ),回归树背后的含义:
对空间进行划分,整个平面被划分为3个部分。

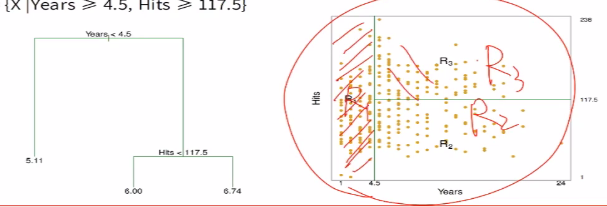
回归树的构建:
假设一个回归树问题,预测结果y属于R,特征向量为X=[x1,x2,x3,......xp]属于R,回归树的两个步骤是:
(1).把整个特征空间X切分成J个没有重叠的区域R1,R2,R3...Rj
(2)其中区域Rj中每个样本我们都给一样的预测结果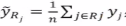 ,其中n是Rj中的样本总数。
,其中n是Rj中的样本总数。
(3)仔细观察上面(1)的过程,实际上我们希望能找到如下的RSS最小划分方式R1,R2,R3.....Rj
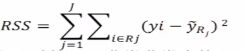
但是这个最小化和探索的过程,计算量是非常大的,我们采用探索式的递归二分来尝试剞劂这个问题。
(4)递归二分
自顶向下:从所有样本开始,不断从当前位置,把样本切分到2个分支里
所谓的自顶向下是从当前位子一刀砍下去,只能把当前已经生成的区域,再砍成两个区域
贪婪:每一次划分,只考虑当前最优,而不回过头考虑之前的划分
(5)选择切分的维度(特征)xj以及切分点s使得划分后的树RS结果最小

2.回归树剪枝
(1)如果让回归树充分“生长”,同样会出现过拟合的风险
(2)解决办法:添加正则化项衡量
(3)考虑剪枝后得到的子树{Ta},其中a是正则项系数,当我固定一个a后,最佳的Ta就是使得下式值子值最小的子树。

a通过交叉验证去选择
3.最优化回归树
三、从决策树到随机森林
1.采样与booststrap
2.bagging与随机森林
Bootstraping:名字来自成语“pull up by your own boostraps”,意识是依靠你自己的资源,称为自助法,是一种又放回的抽样方法,是非参数统计中一种重要的估计统计量方差而进行区间估计的统计方法。核心思想和基本步骤如下:
(1)采样重抽样技术从原始样本中抽取一定数量(自己给定)的样本,此过程允许重复抽样。
(2)根据抽出的样本计算给定的统计量T
(3)重复上述N次(一般大于1000),得到N个统计量T
(4)计算上述N各统计量T的样本方差,得到统计量的方差
Bootstrap是现代统计学较为流行的一种统计方法,在小样本时效果好。通过方差的估计可以狗叫置信区间,其运用范围得到进一步延伸。
3.Bagging是bootstrap aggregating的缩写,使用了上述的bootstraping思想。Bagging降低了过拟合的风险,提高了泛化的能力。从总的样本中,每次抽取出一部分样本,去构建学习器,然后把这些学习器拿过来做投票或者求平均。
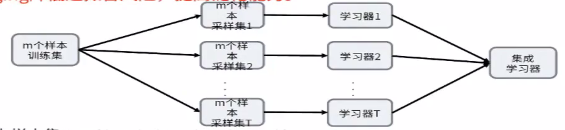
(1)输入样本集D={(x1,y1),(x2,y2),.....(xm,ym)}
对于t=1,2,3,4......T:
a)对训练集进行第T次随机采样,共采集m次,得到包含m个样本的采样集Dm
b)用采样集Dm训练训练第m个基本学习器Gm(x)
(2)分类场景,则T个学习器投出最多票数的类别为最终类别。回归场景,T个学习器得到的回归结果进行算术平均得到的值为最终的模型输出
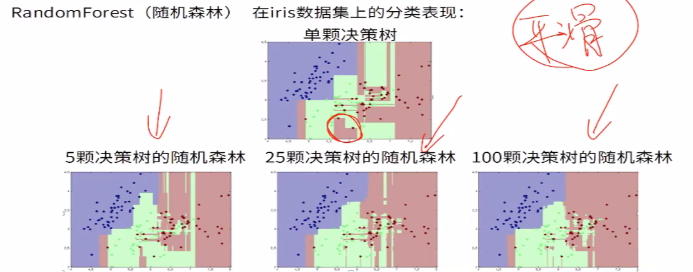
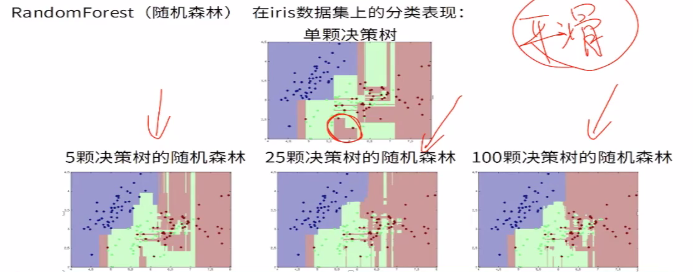
4.RandomForest(随机森林)是一种基于树模型的Bagging的优化版本。核心思想依旧是bagging,但是具体的做了一些独特的改进。
RF使用了CART决策树作为基学习器,具体的过程如下:
输入样本集D={(x1,y1),(x2,y2),......(xm,ym)}
(1)对于t=1,2,3.....T:
a)对训练集进行第t次随机采样,共采集m次,得到包含m个样本的采样集Dm
b)用采样集Dm训练第m个决策树模型Gm(x),在训练决策树模型的节点的时候,在节点上所有的样本特征中选择一部分样本特征,在这些随机选择的部分样本特征中选择一个最优的特征来做决策树的左右子树划分
(2)分类场景,则T个基模型(决策树)投出最多票数的类别为最终类别。回归场景,T个基模型(回归树)得到的回归结果进行算术平均得到的值为最终的模型输出。