零、Python语言基础复习
一、环境部署
1.python包管理:
(1)安装:pip install xxx,conda install xxx
(2)卸载:pip uninstall xxx, conda uninstall xxx
(3)升级:pip install -upgrade xxx, conda update xxx
2.IDE
1)Jupyter notebook:
(1)Anaconda自带,无需单独安装
(2)记录思考过程,实时查看运行进程
(3)基于web的在线编辑器(本地)
(4).ipynb文件分享
(5)可交互式
(6)记录历史运行结果
(7)支持Markdown,Latex
2)IPython
(1)Anaconda自带,无需单独安装
(2)Python的交互式命令行Shell
二、NumPy数据结构以及向量化
1.Numpy :Numerical Python
(1)高性能科学计算和数据分析(pandas)的基础包,提供多维数组对象
(2)ndarray,多维数组(矩阵),具有矢量运算能力,快速、节省空间
(3)矩阵运算,无需循环,可完成类似Matlab中的矢量运算
(4)线性代数、随机数生成
(5)import numpy as np
2.Scipy
(1)在NumPy库的基础上增加了众多数学、科学以及工程常用的库函数
(2)现行代数、微分方程求解、信号处理、图像处理、系数矩阵等
(3)import scipy as sp
3.NumPy数据结构
(1)ndarray,N维数组对象(矩阵)
所有元素类型必须相同
ndim属性 维度的个数
shape属性,各维度的大小
dtype属性,数据类型
(2)创建ndarray
np.array(collection),collection为序列性对象(list),嵌套序列(list of list)
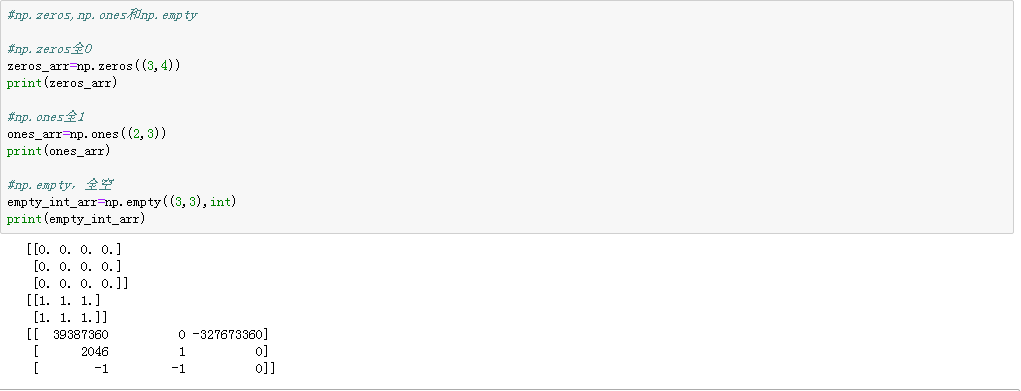
np.zeros,np.ones,no.empty指定大小全为0或者全为1的数组
注意:第一个参数是元组,用来指定大小,如(3,4)
empty不是总是返回全0,有时候返回的是未初始的随机值
4.代码学习
(1)生成两行三列的随机数,并打印出数据的类型
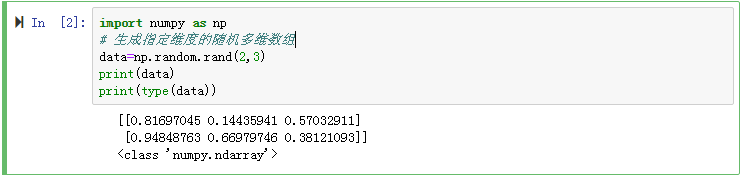
(2)分别打印出刚才创建的维度的个数,维度大小以及数据类型

(3)全0,全1以及全空
5.索引与切片
(1)一维数组的索引与Python的列表索引功能相似
(2)多维数组的索引
arr[r1:r2,c1:c2]
arr[1,1]等价于arr[1][1]
[:]代表某个维度的数据
arr[1:,1:]代表访问数组中第1行到第2行以及第1列到第2列的数据
(3)条件索引
布尔值多维数组arr[condition]condition可以是多个条件的组合。
注意,多个条件组合要使用& | 而不是and or
(4)维数转换transpose
转换数组转置要指定维度编号(0,1,2,3.....)
(5)np.where
矢量版本的三元表达式 x if condition else y 如果条件满足就是x否则就是y
np.where(conditoin,x,y) 满足条件就是x,不满足条件就是y
(6)常用的统计方法
np.mean,np,sum
np.max,np.min
np.std(标准差),np.argmin(方差)
np.cumsum(),np.cumprod()
注意要是多维的话,要指定统计的维度
np.all和np.any:all是满足全部条件;any至少有一个元素满足
np.unique:找到唯一元素并返回排序结果
三、向量化
1.向量化
(1)获得执行速度更快、更加紧凑的代码策略
(2)基本思路:"一次"在一个复杂的对象上进行操作,或者向其应用某个函数,而不是通过在对象的单个元素上循环来进行
(3)在python级别上,函数式编程工具map,filter和reduce提供了向量化的手段
(4)在numpy级别上,在ndarray对象的循环由经过高度优化的代码复杂,大部分代码用C编写,远快于python
(5)矢量间的运算,相同大小的数组间运算应用在元素上
(6)矢量和标量运算,"广播"-广播到各个元素
2.通常函数(ufunc)
(1)元素级运算
(2)常用的通用函数
ceil,向上最接近的整数
floor,向下最接近的整数
rint,四舍五入
isnan,判断元素是否为NaN(Not a Number)
multiply,元素相乘
divide,元素相除
三、数据分析建模理论基础
1.任务分类:(1)分类;(2)回归;(3)聚类;(4)时序分析
2.分类与回归:
(1)应用:信用卡申请人风险评估、预测公司业务增长量、预测房价等
(2)原理:将数据映射到预先定义的群组或者类。算法要求基于数据属性值来定义类别,把具有某些特征的数据项映射到给定的某个类别上。
(3)回归:用属性的历史数据来预测未来的趋势。算法首先假设一些已知类型的函数可以拟合目标函数、然后利用某种误差分析来确定一个与目标函数拟合程度最好的函数
(4)区别:分类模型采用离散预测值,回归模型采用连续的预测值
3.聚类:(1)应用: