统计量
统计量是统计理论中用来对数据进行分析、检验的变量。宏观量是大量微观量的统计平均值,具有统计平均的意义,对于单个微观粒子,宏观量是没有意义的.
相对于微观量的统计平均性质的宏观量也叫统计量。需要指出的是,描写宏观世界的物理量例如速度、动能等实际上也可以说是宏观量,但宏观量并不都具有统计平均的性质,因而宏观量并不都是统计量。
样本均值
样本均值(sample mean)又叫样本均数。即为样本的均值。
均值是表示一组数据集中趋势的量数,是指在一组数据中所有数据之和再除以这组数据的个数。它是反映数据集中趋势的一项指标。
样本均值则是在总体中的样本数据的均值。
样本:
样本(sample),是指从总体中抽出的一部分个体。样本中所包含个体数目称样本容量或含量,用符号N或n表示。
均值:
均值是表示一组数据集中趋势的量数,是指在一组数据中所有数据之和再除以这组数据的个数。它是反映数据集中趋势的一项指标。
解答平均数应用题的关键在于确定“总数量”以及和总数量对应的总份数。在统计工作中,平均数(均值)和标准差是描述数据资料集中趋势和离散程度的两个最重要的测度值。
样本方差
样本方差的公式为  其中
其中 ![]() 为样本均值。
为样本均值。
样本变异系数
样本K阶矩
样本来自总体,携带了总体的部分信息。进行统计分析和推断时,要使用样本携带的信息推断总体的概率性质,但样本带来的信息往往是分散凌乱的,需要集中整理加工后才便于利用。
初步整理可以用分组、作图、列表等方法,但进一步深入统计提取样本信息就要根据问题的需要构造样本函数——统计量。
设 ![]() 为来自总体的样本,若样本的
为来自总体的样本,若样本的 ![]() 元函数
元函数 ![]() 是一个连续却不含总体未知参数的函数,则称其为统计量。
是一个连续却不含总体未知参数的函数,则称其为统计量。
有一类常用的统计量是样本的数字特征,他们是模拟总体数字特征构造的,称为样本矩(这里只列出样本k阶原点钜、样本k阶中心钜):
样本偏度
样本偏度(sample skewness)一种基本统计量.样本三阶中心矩除以样本二阶中心矩的3/2次幂的商,记为Sk。
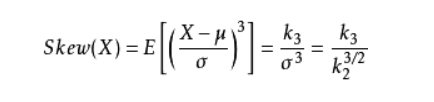
偏度定义中包括正态分布(偏度=0),右偏分布(也叫正偏分布,其偏度>0),左偏分布(也叫负偏分布,其偏度<0)。
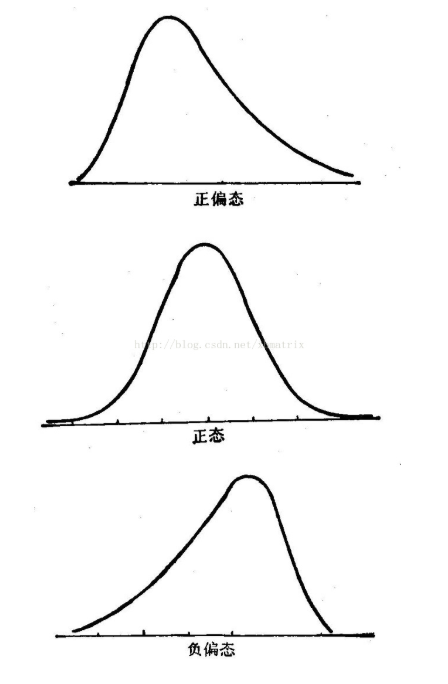
样本峰度
抽样分布
卡方分布
卡方分布 (χ2分布)是概率论与统计学中常用的一种概率分布。
k 个独立的标准正态分布变量的平方和服从自由度为k 的卡方分布。卡方分布常用于假设检验和置信区间的计算。
数学定义:
若k 个随机变量Z1、……、Zk 相互独立,且数学期望为0、方差为 1(即服从标准正态分布),则随机变量X 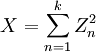 被称为服从自由度为 k 的卡方分布
被称为服从自由度为 k 的卡方分布
记作: 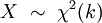
具体点击查看:卡方分布
T分布
在概率论和统计学中,t-分布(t-distribution)用于根据小样本来估计呈正态分布且方差未知的总体的均值。
如果总体方差已知(例如在样本数量足够多时),则应该用正态分布来估计总体均值。
t分布曲线形态与n(确切地说与自由度df)大小有关。与标准正态分布曲线相比,自由度df越小,t分布曲线愈平坦,曲线中间愈低,曲线双侧尾部翘得愈高;
自由度df愈大,t分布曲线愈接近正态分布曲线,当自由度df=∞时,t分布曲线为标准正态分布曲线。
 , 其中,Gam(x)为伽马函数。
, 其中,Gam(x)为伽马函数。F分布
F分布是1924年英国统计学家R.A.Fisher提出,并以其姓氏的第一个字母命名的。
它是一种非对称分布,有两个自由度,且位置不可互换。F分布有着广泛的应用,如在方差分析、回归方程的显著性检验中都有着重要的地位。
具体见:F分布
样本方差的分布

样本比例的抽样分布

中心极限定理
心极限定理是概率论中最著名的结果之一,它提出,大量的独立随机变量之和具有近似于正态的分布。
两个样本平均值之差的分布
设 ![]() 是来自正态分布
是来自正态分布 ![]() 的一个样本,
的一个样本,![]() 是来自正态分布
是来自正态分布 ![]() 的一个样本,且
的一个样本,且 ![]() 与
与 ![]() 相互独立,则:
相互独立,则:
![]() ,其中
,其中 ![]() 是第一自由度(分子自由度)为 n1−1,第二自由度(分母自由度)为 n2−1 的 F分布。
是第一自由度(分子自由度)为 n1−1,第二自由度(分母自由度)为 n2−1 的 F分布。