怎么想到写索引的呢 在牛客网刷题的时候看到一个题目是这样的
mysql数据库,game_order表表结构如下,下面哪些sql能使用到索引()? 多选
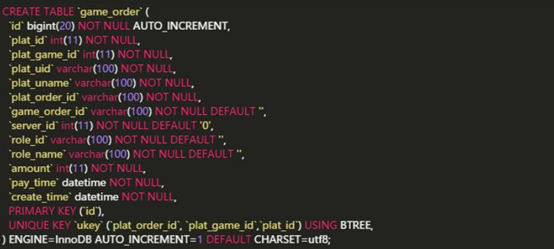
A.select * from game_order where plat_game_id=5 and plat_id=134
B.select * from game_order where plat_id=134 and plat_game_id=5 and plat_order_id=’100
C.select * from game_order where plat_order_id=’100’
D.select * from game_order where plat_game_id=5 and plat_order_id=’100’ and plat_id=134
E. select * from game_order where plat_game_id=5 and plat_order_id=’100’
我选的是 A B C D E 看到这就知道选的不对!
这里涉及到了复合索引 最左优先原则 意思就是组合索引的中第一个字段必须在查询语句中用到 只要组合中索引第一个字段出现在where中,不管其他字段有没有出现都会使用启用索引优化查询
所以A是不对 正确答案是BCDE
根据最左匹配原则可以知道B-Tree建立索引的过程,比如假设有一个3列索引(col1,col2,col3),那么MySQL只会会建立三个索引(col1),(col1,col2),(col1,col2,col3)。
说到这里再来谈谈面试中会问的到所以面试题
Q:什么是索引?
A:索引是一种数据结构,能够快速检索数据库中的数据;
Q:索引有哪些结构?
A:有hash索引 B+Tree 索引 常用的是Innode引擎 默认是B+Tree的
Q:OK那再说说B+Tree和Hash 有什么优缺点吗
A:Hash索引底层是哈希表,哈希表是一种以key-value存储数据的结构,所以多个数据在存储关系上是完全没有任何顺序关系的,所以,对于区间查询是无法直接通过索引查询的,就需要全表扫描。所以,哈希索引只适用于等值查询的场景。而B+ 树是一种多路平衡查询树,所以他的节点是天然有序的(左子节点小于父节点、父节点小于右子节点),所以对于范围查询的时候不需要做全表扫描
哈希索引适合等值查询,但是无法进行范围查询
哈希索引没办法利用索引完成排序
哈希索引不支持多列联合索引的最左匹配规则
如果有大量重复键值的情况下,哈希索引的效率会很低,因为存在哈希碰撞问题
Q:那你知道B+ Tree的叶子节点都可以存哪些东西吗? 他们之间有什么区别
A:InnoDB的B+ Tree可能存储的是整行数据,也有可能是主键的值
在 InnoDB 里,索引B+ Tree的叶子节点存储了整行数据的是主键索引,也被称之为聚簇索引。而索引B+ Tree的叶子节点存储了主键的值的是非主键索引,也被称之为非聚簇索引
聚簇索引 查询更快
Q:为什么聚簇索引查询更快呢
A:因为主键索引树的叶子节点直接就是我们要查询的整行数据了。而非主键索引的叶子节点是主键的值,查到主键的值以后,还需要再通过主键的值再进行一次查询
Q: 非主键索引一定会查询多次吗?
A:可以使用覆盖索引来减少查询次数
覆盖索引(covering index)指一个查询语句的执行只用从索引中就能够取得,不必从数据表中读取。也可以称之为实现了索引覆盖。
当一条查询语句符合覆盖索引条件时,MySQL只需要通过索引就可以返回查询所需要的数据,这样避免了查到索引后再返回表操作,减少I/O提高效率。
索引设计的原则
1)适合索引的列是出现在where子句中的列,或者连接子句中指定的列;
2)基数较小的类,索引效果较差,没有必要在此列建立索引;
3)使用短索引,如果对长字符串列进行索引,应该指定一个前缀长度,这样能够节省大量索引空间;
4)不要过度索引。索引需要额外的磁盘空间,并降低写操作的性能。在修改表内容的时候,索引会进行更新甚至重构,索引列越多,这个时间就会越长。所以只保持需要的索引有利
为什么主键通常建议使用自增id
聚簇索引的数据的物理存放顺序与索引顺序是一致的,即:只要索引是相邻的,那么对应的数据一定也是相邻地存放在磁盘上的。如果主键不是自增id,那么可以想 象,它会干些什么,不断地调整数据的物理地址、分页,当然也有其他一些措施来减少这些操作,但却无法彻底避免。但,如果是自增的,那就简单了,它只需要一 页一页地写,索引结构相对紧凑,磁盘碎片少,效率也高
mysql中聚簇索引的设定
聚簇索引默认是主键,如果表中没有定义主键,InnoDB 会选择一个唯一的非空索引代替。如果没有这样的索引,InnoDB 会隐式定义一个主键来作为聚簇索引。InnoDB 只聚集在同一个页面中的记录。包含相邻健值的页面可能相距甚远。