name node1 JournalNode1: 192.168.81.132 -> hadoop1
name node2 JournalNode2: 192.168.81.130 -> hadoop2
data1 node JournalNode3: 192.168.81.129 -> hadoop3
data2 node: 192.168.81.131 -> hadoop4
一、创建账号
1.所有节点创建用户 useradd hadoop passwd hadoop
2.所有节点创建目录 mkdir -p /home/hadoop/source mkdir -p /home/hadoop/tools
3.Slave节点创建目录 mkdir -p /hadoop/hdfs mkdir -p /hadoop/tmp mkdir -p /hadoop/log chmod -R 777 /hadoop
二、修改主机名
所有节点修改
1.vim /etc/sysconfig/network ,修改 HOSTNAME=hadoopx
2.vim /etc/hosts
192.168.81.132 hadoop1
192.168.81.130 hadoop2
192.168.81.129 hadoop3
192.168.81.131 hadoop4
3.执行 hostname hadoopx
4.重新登录,即可
三、免密码登录
注意:非root用户免密码登录,需要执行 chmod 700 ~/.ssh chmod 600 ~/.ssh/authorized_keys 如果不修改权限,非root用户无法免密码登录
四、安装JDK
五、配置环境变量
1. /etc/profile
export HADOOP_HOME=/home/hadoop/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPARED_HOME=${HADOOP_HOME}
export HADOOP_COMMON_HOME=${HADOOP_HOME}
export HADOOP_HDFS_HOME=${HADOOP_HOME}
export YARN_HOME=${HADOOP_HOME}
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HDFS_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export YARN_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
2. hadoop-env.sh 在末尾添加 export JAVA_HOME=/usr/java/jdk1.6.0_27
六、Hadoop 2.3安装
1.core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop1:9000</value>
</property>
</configuration>
2.添加slaves节点 hadoop3 hadoop4
3.配置hdfs-site.xml
<configuration>
<property> <name>dfs.replication</name> <value>2</value> </property>
<property> <name>dfs.nameservices</name> <value>cluster1</value> </property>
<property> <name>dfs.ha.namenodes.cluster1</name> <value>hadoop1,hadoop2</value> </property>
<property> <name>dfs.namenode.rpc-address.cluster1.hadoop1</name> <value>hadoop1:9000</value> </property>
<property> <name>dfs.namenode.rpc-address.cluster1.hadoop2</name> <value>hadoop2:9000</value> </property>
<property> <name>dfs.namenode.http-address.cluster1.hadoop1</name> <value>hadoop1:50070</value> </property>
<property> <name>dfs.namenode.http-address.cluster1.hadoop2</name> <value>hadoop2:50070</value> </property>
<property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://hadoop1:8485;hadoop2:8485;hadoop3:8485/cluster1</value> </property>
<property> <name>dfs.client.failover.proxy.provider.cluster1</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property>
<property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property>
<property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> </property>
<property> <name>dfs.journalnode.edits.dir</name> <value>/hadoop/tmp/journal</value> </property>
<property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property>
</configuration>
4.配置yarn-site.xml
4.配置yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property> <name>yarn.resourcemanager.address</name> <value>192.168.81.132:18040</value> </property>
<property> <name>yarn.resourcemanager.scheduler.address</name> <value>192.168.81.132:18030</value> </property>
<property> <name>yarn.resourcemanager.webapp.address</name> <value>192.168.81.132:18088</value> </property>
<property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>192.168.81.132:18025</value> </property>
<property> <name>yarn.resourcemanager.admin.address</name> <value>192.168.81.132:18141</value> </property>
<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>
<property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> </configuration>
mapred-site.xml <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>192.168.81.132:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>192.168.81.132:19888</value> </property> </configuration>
5.配置httpfs-site.xml 略
mapred-site.xml <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>192.168.81.132:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>192.168.81.132:19888</value> </property> </configuration>
5.配置httpfs-site.xml 略
七、配置DataNode
1.复制hadoop-2.3至各Data节点
2.复制环境变量/etc/profile,生效
八、启动并验证
1.启动JournalNode集群
在hadoop1,hadoop2,hadoop3
执行 hadoop-daemon.sh start journalnode
jps 是否有journalnode进程
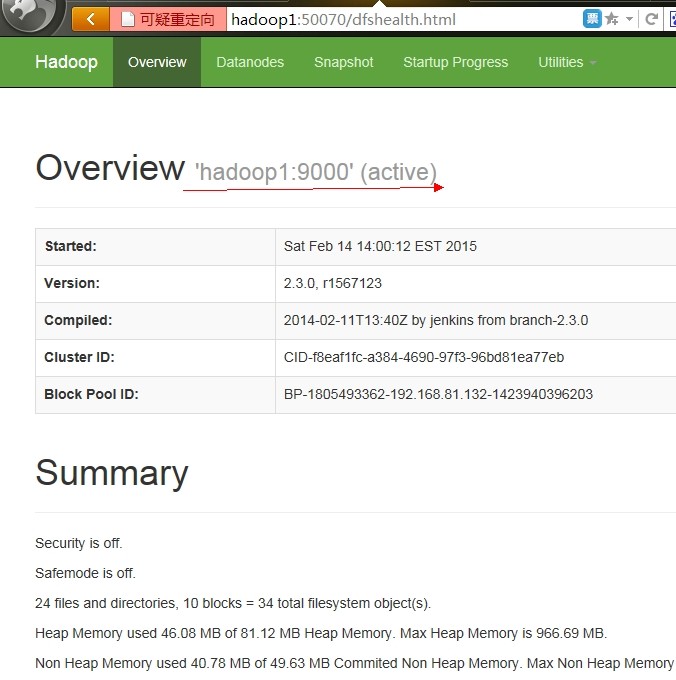
2.格式化并启动主NameNode hadoop1
hdfs namenode -format
hadoop-daemon.sh start namenode
jps 是否有namenode进程
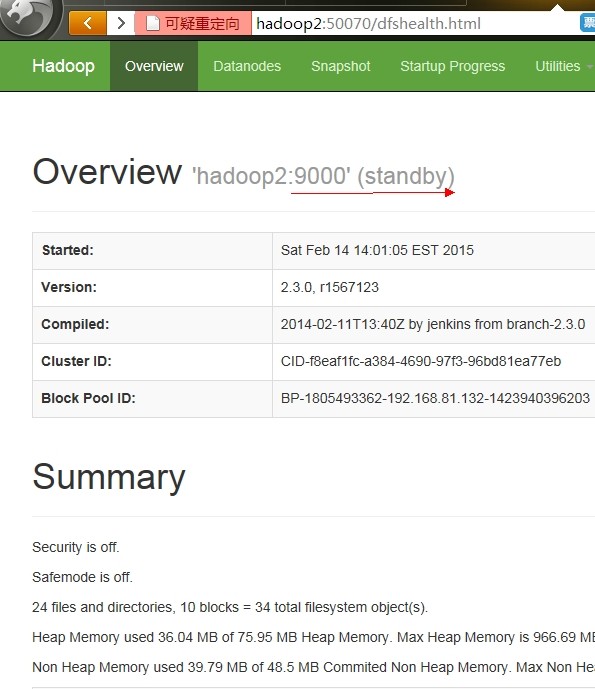
3.格式化并启动从NameNode hadoop2
hdfs namenode -bootstrapStandby
hadoop-daemon.sh start namenode
jps 是否有namenode进程
4.设置主NameNode
hdfs haadmin -transitionToActive hadoop1
启动数据节点 hadoop-daemons.sh start datanode (注意:需要删除之前数据)
5.主从切换
hdfs haadmin -failover -forceactive hadoop1 hadoop2 (将hadoop2转为Active节点)
如果向上传数据,还需要修改core-site.xml中的fs.default.name的值,改为hdfs://hadoop2:9000 才行
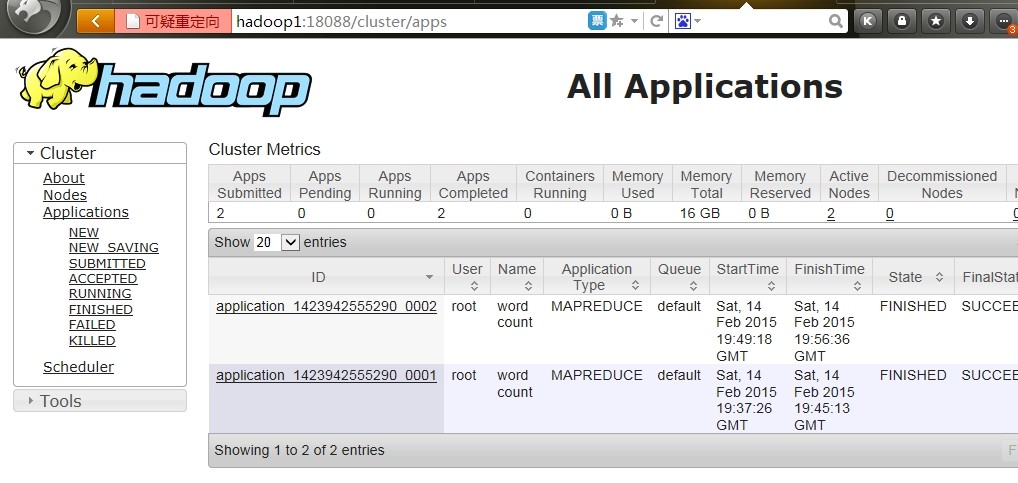
6.启动start-yarn.sh,测试JOB运行
hadoop jar hadoop-mapreduce-examples-2.3.0.jar wordcount hdfs://192.168.81.132:9000/input hdfs://192.168.81.132:9000/output7
7.主要的几个文件 core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml
8.web访问