攻击机器学习探测器:最先进的审查
机器学习(ML)是检测恶意软件的好方法。它在技术社区和科学界广泛使用,但有两种不同的观点:性能VS鲁棒性。技术界试图提高ML性能,以便大规模地提高可用性,同时科学界通过意味着攻击ML探测器引擎的容易程度来关注鲁棒性。今天我想集中关注第二个观点,指出如何 攻击ML探测器引擎。
我们可以从三个主要集合中分类机器学习攻击开始:
- 基于直接梯度的攻击。攻击者需要知道ML模型。攻击者需要知道模型结构和模型权重,以便直接查询机器学习模型,并找出逃避它的最佳方法。
- 分数模型攻击。此攻击集基于得分系统。攻击者不知道机器学习模型或自己的权重,但他可以直接访问检测器引擎,以便他可以探测机器学习模型。该模型将返回一个分数,并根据这样的分数,攻击者将能够通过强制特定和精心设计的输入来猜测如何最小化它。
- 二进制黑盒攻击。 攻击者不知道机器学习模型和应用的权重,他也不知道评分系统,但他可以无限制地访问机器学习模型。
基于直接梯度的攻击
基于直接梯度的攻击可以以至少两种方式实现。第一种也是最常用的方法是对原始样本应用小的更改以减少给定的分数。必须将更改限制为特定域,例如:有效的Windows PE文件或有效的PDF文件,等等。变化必须很小,并且应该生成它们以便最小化由权重导出的评分函数(对于基于直接梯度的攻击已知)。第二种方法是将目标模型(受到攻击的模式)连接到生成对抗网络(GAN)中的生成器模型。与前一组不同,GAN生成器学习如何生成由给定种子导出的完整新样本,该种子能够最小化评分函数。
I.Goodfellow等人。在他们的工作中“解释和利用敌对例子”(这里)表明,如果在给定样本X上最小化所得权重的目标很少,那么在ML规避中是否有效。另一项伟大的工作是由K.Grosse等人撰写的。标题:“针对恶意软件分类的深度神经网络的逆向扰动”(这里)。作者通过在特征向量上应用不可察觉的扰动,攻击了基于DREBIN Android恶意软件数据集的深度学习Android恶意软件模型。
他们有非常有趣的结果,从逃避率的50%到84%。I.Goodfellow等人。他们的作品名为“Generative Adversial Nets”(这里)开发了一个能够迭代一系列对抗轮的GAN,以生成从目标模型中归类为“火腿”的样本,但实际上并非如此。下图显示了通过同时更新判别分布(D,蓝色,虚线)来训练生成对抗网,以便区分来自生成分布(黑色,虚线)px的样本与生成分布pg的样本( G)(绿色,实线)。
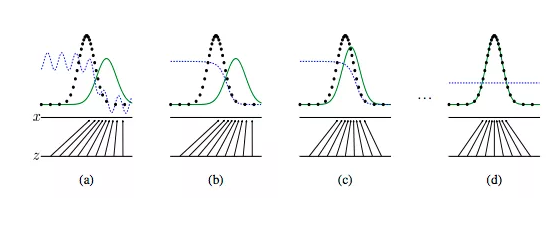
图片来自: “Generative Adversial Nets”
分数模型攻击
该攻击集上的攻击者姿势被视为“myope”。攻击者并不确切知道ML模型是如何工作的,并且他不知道ML算法中的权重如何变化,但他有机会测试他的样本并获得分数,以便他能够测量其效果。输入扰动。
W. Xu,Y。Qi和D. Evans在他们的作品中标题为:“自动规避分类器”(这里)实现了一个“适应度函数”,它给出了每个生成变体的适应度分数。具有正健康分数的变体是回避的。健康分数保持目标模型背后的逻辑,该模型被分类为当前样本的良性但保留恶意行为。一旦样本获得高适应度分数,就将种子用于更通用的遗传算法,该算法开始操纵种子以制造不同的物种。为了确保这些突变根据原始种子保留了所需的恶意行为,作者使用了一个神谕。在那种情况下,他们使用了布谷鸟沙箱。
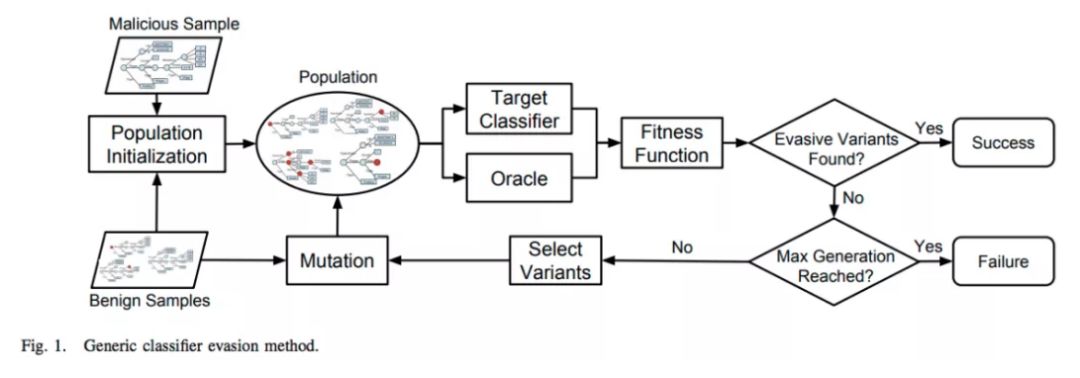
图片来自:“ 自动规避分类器”
执行一周后,遗传算法从500个大约恶意种子中发现了近15k的规避变异,在PDFrate分类器上获得了100%的逃避率。
二进制黑盒攻击
二进制黑盒攻击是最普遍的一种,因为攻击者对所使用的模型一无所知,而反恶意软件引擎只是说:真或假(它是恶意软件或它不是恶意软件)。2017年,W.Hu和Y.Tan在“为恶意软件分类生成对抗性恶意软件示例”中描述了一项伟大的工作(这里)。作者开发了MalGAN一个Adversial Malware生成器,能够生成有效的PE恶意软件,以逃避静态黑盒PE恶意软件引擎。MalGAN背后的想法很简单。首先,攻击者通过提供特定和已知样本(恶意软件和良好PE)来映射黑盒输出。
在映射阶段之后,攻击者构建一个表现为黑盒模型的模型。这是一个受过训练的简单模型,可以作为目标模型。然后将构建的模型用作梯度计算GAN中的目标模型以产生规避恶意软件。作者报告绕过目标模型100%有效。HS Anderson等人。在“逃避机器学习恶意软件检测”(这里)采用了强化学习方法。 下图显示了恶意软件规避强化学习问题的马尔可夫决策过程公式
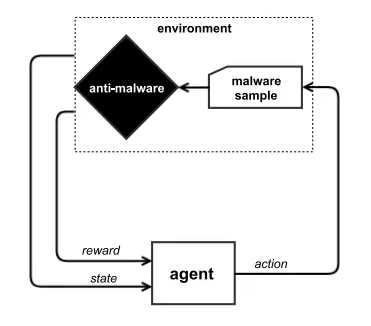
图片来自:逃避机器学习恶意软件检测
代理是根据环境状态操纵样本的函数。奖励和状态都被用作代理的输入,以便对下一个动作做出决定。代理人通过奖励来学习,这取决于达到的状态。例如,如果达到的状态接近期望的状态,则奖励可以更高,反之亦然。作者使用Q-Learning技术来低估对于在中长期内具有重要意义的行为所给出的负面回报。
“在我们的框架中,动作空间A包含对PE文件的一组修改,这些修改(a)不破坏PE文件格式,(b)不改变恶意软件样本的预期功能。奖励函数由反恶意软件引擎测量,如果被修改的恶意软件样本被判断为良性,则转换为奖励:0,如果被认为是恶意的则为1。然后奖励和状态被反馈给代理人。“
最后的考虑因素
机器学习,但更一般地说是人工智能,对检测网络攻击很有用,但不幸的是 - 正如在这篇文章中广泛证明的那样 - 本身就不够。攻击者将使用相同的技术,如对抗机器学习来逃避机器学习探测器。从现在开始,网络安全分析师仍将在网络安全科学与技术领域发挥重要作用,承诺在没有人为干预的情况下确保网络安全保护的技术不会起作用。