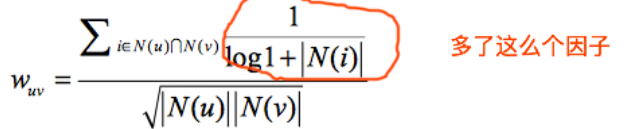使用xmind整理了一下基于用户的协同过滤算法的整体流程

计算两个用户之间的相似度
主要利用行为的相似度计算兴趣的相似度。
给定用户u和用户v两个用户,N(u)表示用户u曾经有过正反馈的物品集合,N(v)表示用户v曾经有过正反馈的物品集合,有三种方法来计算相似度。
余弦相似度

皮尔逊相似度
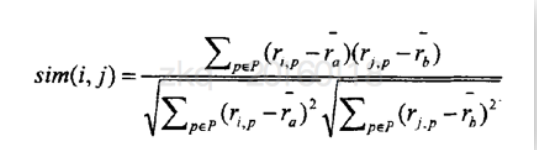
Jaccard公式

经过查阅相关资料,利用皮尔逊相似度来计算用户间的相似度学校过比较理想。
皮尔逊相似度:要理解皮尔逊相似度首先要理解协方差,协方差是反映两个随机变量相关程度的指标,如果一个变量随着另一个变量同时变大或变小,那么两个变量的协方差就是正值,反之相反。公式如下:
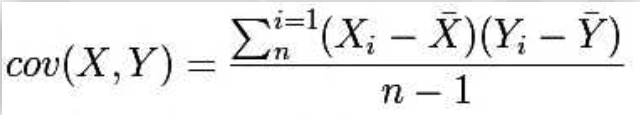
皮尔逊相关系数如下:
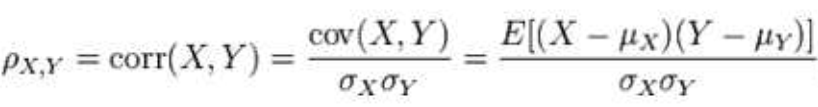
为了更好地度量两个随机变量的相关程度,引入了皮尔逊相关系数,其在协方差基础上除以了两个随机变量的标准差,容易得出,皮尔逊相关系数是介于-1到1之间的值,当两个变量的线性关系增强时,相关系数趋于-1或1;当一个变量增大时,另一个变量也跟着增大,说明它们之间是正相关的,相关系数大于0,;若一个变量增大,另一个变量
减小,说明它们之间是负相关的,相关系数小于0;相关系数等于0说明它们之间不存在线性相关关系。
计算方法举例
比如有如下用户-商品矩阵

例如用户A对物品{a,b,d}有过行为,用户B对物品{a,c}有过行为,利用余弦相似度公式计算用户A和用户B的兴趣相似度为
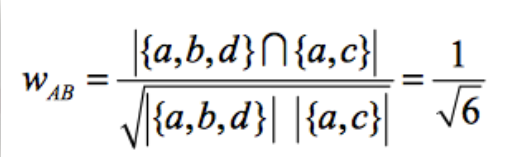
但是,如果要对每对用户都计算余弦相似度,那在用户非常多的情况下非常耗时,因为它的时间复杂度是O(N^2),所以需要建立一张倒排表,这样可以排除无任何联系的用户之间相似度的计算,再根据倒排表计算共同评分过的物品矩阵
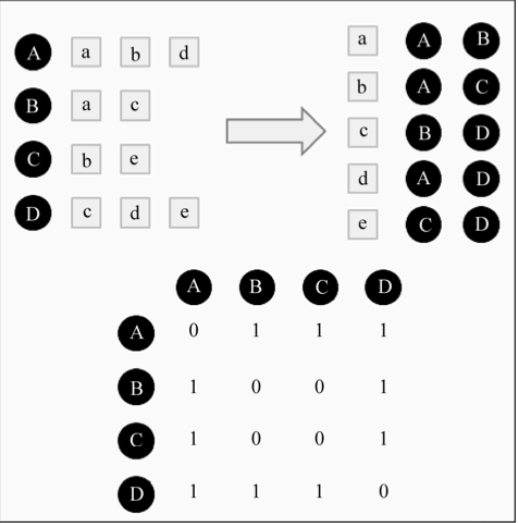
矩阵中每一个数值都是余弦相似度中的分子部分,分子除以分母可以得到最终用户兴趣相似度。
例如,计算用户A和B的用户相似度。用户A和B在矩阵中交集为1,A总共评过分的物品为3,B总共评过分的物品为2,根据余弦相似度算法,得出相似度为根号6分之1
筛选出K个与目标用户最相似用户
得到的用户之间相似度后,算法会给用户推荐与他兴趣最相似的K个用户喜欢的物品。
下面这个公式度量了用户u对物品i的感兴趣程度
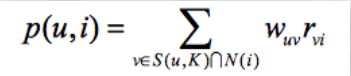
其中S(u,K)包含和用户u兴趣最接近的K个用户,N(i)是对物品i有过行为的用户集合,Wuv是用户u和用户v的相似度,rvi为1
举例来说,对用户A进行推荐,选取K=3,用户A对物品c、e没有过行为,所以可以把这两个商品推荐给用户A。
A对商品c、e的兴趣是
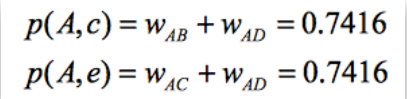
存在的问题
对于一些热门书籍,不能很好的说明用户的兴趣度相似,两用户对于冷门物品采取过同样的行为才更有说服力,所以对于相似度算法加以改进