
1. 修改列名的三种常见方法
- columns属性
# ①暴力
df.columns = ['a', 'b', 'c', 'd', 'e']
# ②修改
df.columns = df.columns.str.strip('$')
# ③修改
df.columns = df.columns.map(lambda x:x[1:])
- rename方法、columns参数
# ④暴力(好处:也可只修改特定的列)
df.rename(columns=('$a': 'a', '$b': 'b', '$c': 'c', '$d': 'd', '$e': 'e'}, inplace=True)
# ⑤修改
df.rename(columns=lambda x:x.replace('$',''), inplace=True)
2. 筛选特定值(删除),范围内的值
df[(True-df['appPlatform'].isin([2]))]
# 过滤掉某个范围的值
df[df['creativeID']<=10000]
3. 日期格式数据转换
数据格式: 1990/9/26 这种 , 结合前面time那篇有如下处理转为时间戳
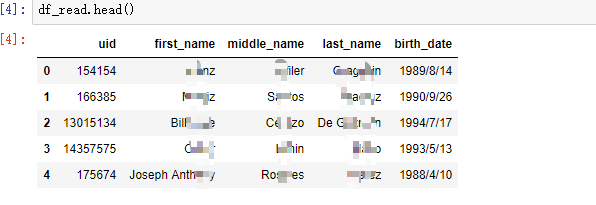
df_read['birth_date'] = df_read['birth_date'].astype(str)
df_read = df_read[~df_read['birth_date'].isin(['0003-11-21'])] # 选取不是 0003-11-21 这个的异常数据
# df1=df1[df1['A'].isin([xxx])] 选取是的值
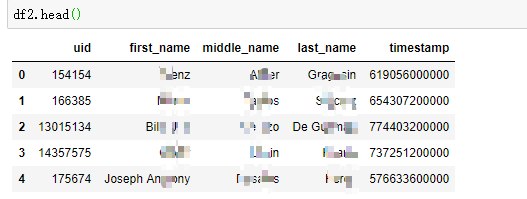
df_read['timestamp'] = df_read['birth_date'].map(lambda x:arrow.get(x, "YYYY/M/D").timestamp*1000)df_read['timestamp'] = df_read['birth_date'].map(lambda x:arrow.get(x, "YYYY/M/D").timestamp*1000)
df2=df_read.drop(["birth_date"],axis=1)
参考: https://www.cnblogs.com/hhh5460/tag/pandas/
4. 写入csv
df2.to_csv('nfis_data.csv',index=False) # 不写索引
dt.to_csv(‘C:/Users/think/Desktop/Result.csv‘,sep=‘?‘)#使用?分隔需要保存的数据,如果不写,默认是,
dt.to_csv(‘C:/Users/think/Desktop/Result1.csv‘,na_rep=‘NA‘) #确实值保存为NA,如果不写,默认是空
dt.to_csv(‘C:/Users/think/Desktop/Result1.csv‘,float_format=‘%.2f‘) #保留两位小数
dt.to_csv(‘C:/Users/think/Desktop/Result.csv‘,columns=[‘name‘]) #保存索引列和name列
dt.to_csv(‘C:/Users/think/Desktop/Result.csv‘,header=0) #不保存列名
dt.to_csv(‘C:/Users/think/Desktop/Result1.csv‘,index=0) #不保存行索引
df = data.drop_duplicates() # 去重
5. python csv 模块
# 读
csvFile = open("foo.csv", "r")
reader = csv.reader(csvFile)
next(reader)
for i, tt in enumerate(reader):
print(i, tt)
# 写
columns = ["uid", "application_id", "pic_url", "ic_no", "name", "gender", "birthday"]
with open('foo_02.csv', 'w', newline='') as outcsv:
writer = csv.writer(outcsv, delimiter=',', quotechar='"', quoting=csv.QUOTE_ALL,
lineterminator='
')
writer.writerow(columns)
...
new_row = (uid, d.id, pic_url, ic_no, name, gender, birthday)
writer.writerow(new_row)
6. 拆分表格(大json拆分为一个个小字段)
# 整个流程
for i in range(df_read.shape[0]):
# for i in range(50):
try:
one_line = df_read[i:i+1]
uid = one_line['uid'][i] #
one_line_json = list(one_line['data_json'])[0]
py_obj = json.loads(one_line_json)
# print(py_obj)
adv_list = py_obj['result'][0]['adv']
params = py_obj['result'][0]['param']
bday = params['bday'] #
name = params['name'] #
if len(adv_list)>0: # if adv_list
for u in adv_list:
report = u['reported']
advdate = u['advdate']
amount = u['secuamt']
advtype = u['advtype']
loantype = u['loantype']
bank = u['bank']
data_list = [uid, bday, name, report, advdate, amount, advtype, loantype, bank]
df_save = pd.DataFrame(data_list)
m = df_save.T
m.columns = ['uid', 'bday', 'name', 'report', 'advdate', 'amount', 'advtype', 'loantype', 'bank']
m.to_csv('test3.csv',mode='a',header=False)
except:
continue