◆版权声明:本文出自胖喵~的博客,转载必须注明出处。
转载请注明出处:http://www.cnblogs.com/by-dream/p/7669139.html
首先解释一下几个名词,由于我的另外两篇文章还没有写出来,因此这里需要先介绍一下:
翻译评测集:以下简称评测集,一组由原文和译文组成的文件,译文一般由专业的译员根据原文翻译获得,在计算BLEU的时候只需要把译文作为参考答案使用即可。
BLEU:一种机器翻译评价指标,用于分析候选译文和参考译文中n元组共同出现的程度,由IBM于2002年提出。通常需要用译文和翻译翻译评测集共同计算获得分值,从而判定译文与评测集之间的相似程度。
为什么要写这么一篇文章呢?
翻译团队在制作翻译评测集时经常需要雇佣一些译员和翻译公司进行翻译工作,由于制作的评测集需要用来评价各个机器翻译引擎,所以该译文绝对不能参考机器翻译,那么如何得知译员是否有参考机器翻译引擎就成了一个比较重要的问题。目前市面上翻译的成本大概在千字120-150元人名币,我们通过这种方法可以有效的避免无效翻译,节省成本。当有翻译公司或个人完成翻译工作后,我们用这种方法来衡量翻译的内容是否为我们可用的内容。事实证明,我这种方法确实很有效。
此方法最便捷的方式就是通过脚本,可以快速定位出现有译文参考了哪些翻译引擎,并且可以快速定位到句子,然后人工分析句子后,就可以知道是否参考了机器翻译。
我们来看看具体的过程:
首先我们准备一份500句的英文语句,递交给翻译公司,需求是规定的时间内完成英文翻译中文的任务。
在递交之后,我们使用市面上现有的机器翻译引擎(百度翻译、Google翻译、有道翻译、Bing翻译、小牛翻译、搜狗翻译、腾讯翻译君翻译)对这份译文进行翻译,得到各个引擎的中文结果文件,我们把这些文件做为将来要评测翻译公司翻译结果的一个评测集。
待翻译公司呈交翻译结果后,我们用之前制作好的各个机器翻译引擎翻译结果的评测集针对译员的翻译结果进行BLEU的计算。我们得到如下数值:
百度:68.4, 89.4/73.5/63.2/56.1(BP=0.985,ratio=0.985,hyp_len=60808,ref_len=61743)
腾讯:45.96, 82.3/56.8/38.9/26.5(BP=0.981,ratio=0.981,hyp_len=60244,ref_len=61398)
搜狗:44.92, 81.1/55.8/37.8/25.7(BP=0.980,ratio=0.981,hyp_len=59788,ref_len=60967)
小牛:42.48, 80.5/53.9/35.7/23.3(BP=0.975,ratio=0.976,hyp_len=59451,ref_len=60940)
Bing:42.14, 81.5/54.0/36.0/23.9(BP=0.956,ratio=0.956,hyp_len=57653,ref_len=60276)
google:41.03, 80.8/52.5/34.3/22.5(BP=0.964,ratio=0.965,hyp_len=58155,ref_len=60260)
有道:40.01, 80.5/52.2/34.1/22.2(BP=0.947,ratio=0.949,hyp_len=56675,ref_len=59735)
一般我们只看第一个数值:
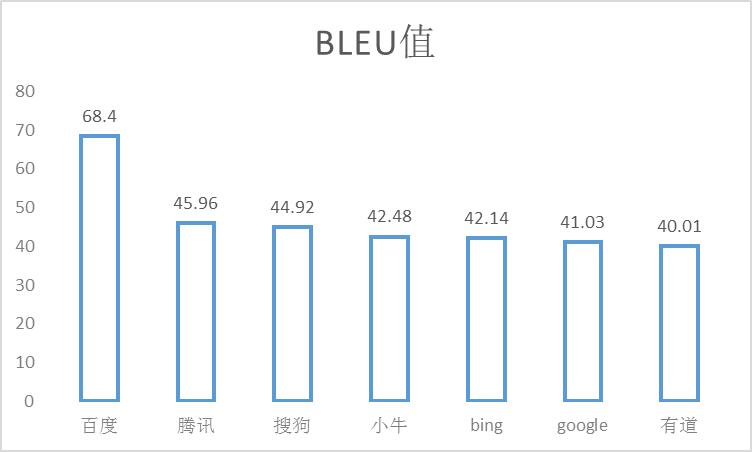
根据经验来看,一般BLEU的值的差距之间会比较小,例如上图中除百度之外的其他所有引擎,因此我们可以判断出百度的分值的异常,很有可能就是因为译文有大量参考百度机器翻译的原因,为了证实这个结论,我们需要用百度的机器翻译译文和人工翻译的译文进行比较,可以使用“比较软件Beyond Compare”,也可以使用我自己实现的same.py脚本,可以直接看出百度的机器翻译译文和人工翻译的译文中完全相同的句子。
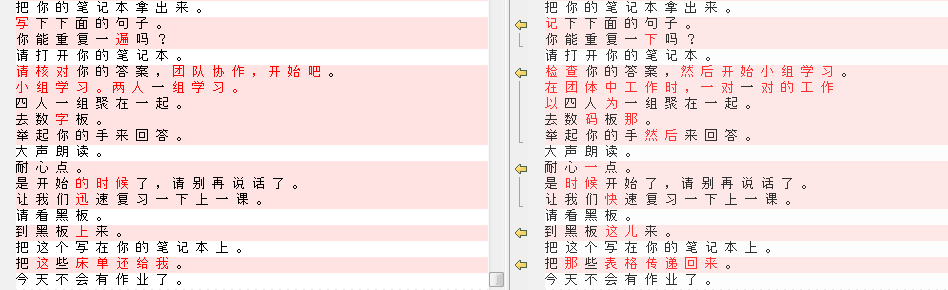
如上图所示,红色部分是两篇译文直接有差距的地方,白色底色的部分就是完全相同的句子。
这时候我们再次提取出这些完全相同的句子,BLEU如果特别高,基本就说明了参考的可能性越大,这时候我们对这些句子进行流畅度和翻译忠实度两个标准进行评判,如果句子本身质量特别高,都没有问题,那么说明百度的翻译质量非常高,已经接近了人翻,但是一般情况下人工评测完的结果都是这些句子的质量不是特别好,那么就说明这些句子并不是来自人翻,而是直接采用了机器翻译的结果。
之前合作的几家翻译公司提供过来的译文经过这种方法的计算后,均发现了译文有参考翻译引擎的嫌疑,事后经过人工二次确认,发现翻译公司确实没有按照规定完成任务,译员在翻译的过程中参考了机器翻译,甚至有些直接采用了一些有问题的机器翻译的结果。
说实话人都有惰性,一般让一个译员翻译过多的译文,难免会出现这样的情况,只要我们掌握了这个方法,就可以有效的避免这样事情的发生了。