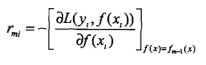树模型
- 应用场景:1.分类 2.回归
- 步骤:特征选择+树的生成+剪枝
- 分类应用中的树模型等价于if-then规则的集合or定义在特征空间与类空间的条件概率分布,可解释性强
- 概念:
1. 熵:表示随机变量的不确定程度,其数值越大,则随机变量的不确定性也越大
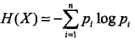
2.条件熵:表示在已知随机变量X的条件下随机变量Y的不确定性,定义为X已知时随机变量Y的条件概率的熵对X的数学期望
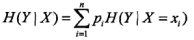
3.信息增益:表示已知特征X的信息而使得类Y的不确定性减少的程度
g(Y,X)=H(Y)-H(Y|X)
4.信息增益比:解决了信息增益受训练数据集影响而没有绝对意义的问题
g_r(Y,X)=g(Y,X)/H(Y)
- 实现:本质是特征选择问题
1. ID3决策树 :采用信息增益
2.C4.5决策树:采用信息增益比
- 决策树剪枝:防过拟合
1.定义:树T有|T|个叶节点,t为其中的一个叶节点,其内包含N_t个样本,该组样本中类型共有N_tk个类型为k的样本,k=1,2,...,K,H_t(T)为叶节点t上的信息熵,则定义决策树的损失函数为,
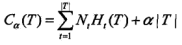
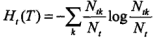
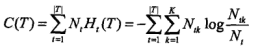
即,模型拟合数据的程度与模型的复杂度进行综合考虑。
2.策略:
- 分类与回归树:CART
1. 即可用于分类,又能用于回归
2.思想:特征生成时对分类树使用基尼系数最小化准则,对回归树使用均方误差最小化准则
a) 基尼系数:
1. 建模:A为特征,D为数据集,C_k表示类型为k的子数据块中数据的数目
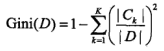
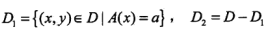
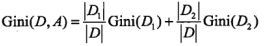
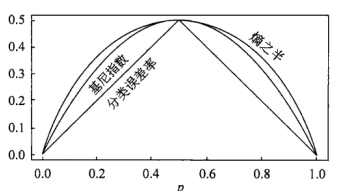
2.基尼系数描述了集合中数据的不确定性,基尼系数越大,则样本集合的不确定性也越大
b)最小均方误差:
1.建模:对于样本数据D={(x1,y1),...,(xn,yn)},将其划分为M个单元R_1,R_2,...,R_M,每个单元上固定输出值c_m,启发式递归进行以下操作,
1).寻找最佳切分变量与切分点以最小化损失函数:
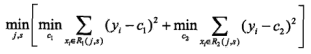
2).利用(j,s)对样本数据划分,并计算对应的输出c_m:
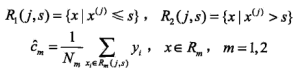
3).输出:
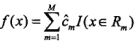
3.对比:
提升算法
- 基本概念:
1.强可学习和弱可学习是等价的。所以,可将弱学习算法提升成强学习算法。最具代表性的为AdaBoost算法。
2.提升方法的策略:a)改变训练数据的概率分布,即训练数据的权值分布,针对不同分布的数据学习得到弱分类器;b)组合弱分类器为强分类器;
- AdaBoost:
1.方案: a)提高被前一轮弱分类器错误分类样本的权值,使其被后一轮弱分类器关注;b)利用多数表决,对分类错差小的弱分类器加大权值,实现分类器组合;
2.算法:
a)初始化数据的权值分布:
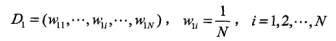
b)对各轮弱分类器m=1,2,...,M:
1.利用改变权值分布后的训练数据D_m训练得到弱分类器G_m,
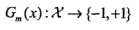
2.计算本轮得到的弱分类器在训练数据集上的误差e_m,并由此计算出此模型的加权系数alpha_m,
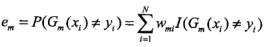
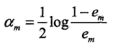
3.更新训练数据权值分布:
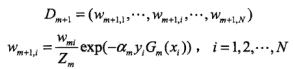

c)构建强分类器:
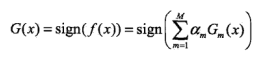
3.前向分布算法与AdaBoost:后者是前者的特例。加法模型。
- 提升树:
1.策略:
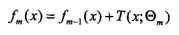
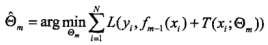
2.分类树提升:指数损失函数,限定Adaboost里的基分类器为决策树即可
3.回归树的提升:平方误差损失函数,拟合残差得到子回归树
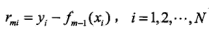
- 梯度提升:
1.目的:提升树使用加法模型及前向分布算法进行学习,此时损失函数为指数损失或均方误差时,学习过程很简单,但为解决一般损失函数的学习优化问题,可使用梯度提升
2.策略:利用损失函数的负梯度作为回归提升树残差的近似值来拟合回归树,