一、概念
MapReduce:
"相同"的key为一组,调用一次reduce方法,方法内迭代这一组数据进行计算
块、分片、map、reduce、分组、分区之间对应关系
block > split
1:1:1个block可以切成1个分片
N:1:多个block可以以切成1个分片
1:N:1个block可以切成多个分片
split > map
1:1:一个分片只能产生一个map
map > reduce
N:1:多个Map可以对应一次reduce
N:N:多个Map可以对应多次reduce
1:1:1个Map可以对应1次reduce
1:N:1个Map可以对应多次reduce
group(key)>partition
1:1:1次分组可以对应1个分区
N:1:多个分组可以对应一个分区
N:N:多个分组可以对应多个分区
1:N? >违背了原语
partition > outputfile

MapTAsk:
(1)对于一个分片,加载到内存进行Map处理,
(2)Map业务逻辑将分片中数据处理成一个个的K,V键值对
(3)将Map输出的K,V键值对加工,生成含有分区partition的K,V,P键值对
(4)经过一段时间的处理,将生成的KVP数据放到缓存里(默认100M),然后按照分区P,键key排序,最终形成一个内部有序外部无序的100M文件
(5)将这个100M缓存输出到本地文件系统里,经过map处理完成后,最终生成一堆这样的小文件
(6)将这一堆小文件进行归并形成一个内部有序外部无序的大文件

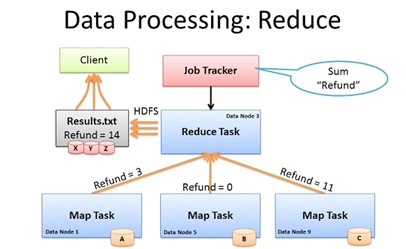
ReduceTask:
(1)将各个节点归并后的大文件中拉取(shuffler)属于同一分区的文件
这个地方会产生网络IO,map之后的文件如果很大会影响性能,因此可以对map之后的数据进行简单统计 降低拉取文件的大小
(2)将拉过来的小文件进行归并,reduce的归并强依赖map的排序结果
(3)将合并的文件调用reduce
二、Hadoop整体协作
Hadoop 1.x
1、客户端clients先启动,计算切片清单,
2、客户端将MR jar包、切片清单、配置文件等作业资源上传HDFS;
3、客户端提交任务给Job Tracker
4、Job Tracker从HDFS获取切片清单,参考Task Tracker上的资源负载情况,规划Map、Reduce任务去到的节点
5、Task Tracker通过与Job Tracker心跳,获取属于自己的任务清单
6、Task Tracker从HDFS上获取切片清单、jar、配置,map运行map任务,Reduce运行Reduce任务,
7、Reduce任务将生成结果文件返回给HDFS
8、客户端通过HDFS下载文件 查看结果
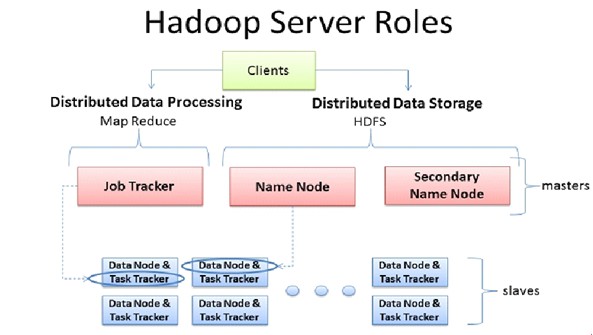

弊端:Job Tracker有两件事:任务调度和监控整个集群资源负载,存在单点故障、负载过重、资源管理和计算调度强耦合
因此有了Hadoop 2.x的YARN