环境
虚拟机:VMware 10
Linux版本:CentOS-6.5-x86_64
客户端:Xshell4
FTP:Xftp4
jdk1.8
scala-2.10.4(依赖jdk1.8)
spark-1.6
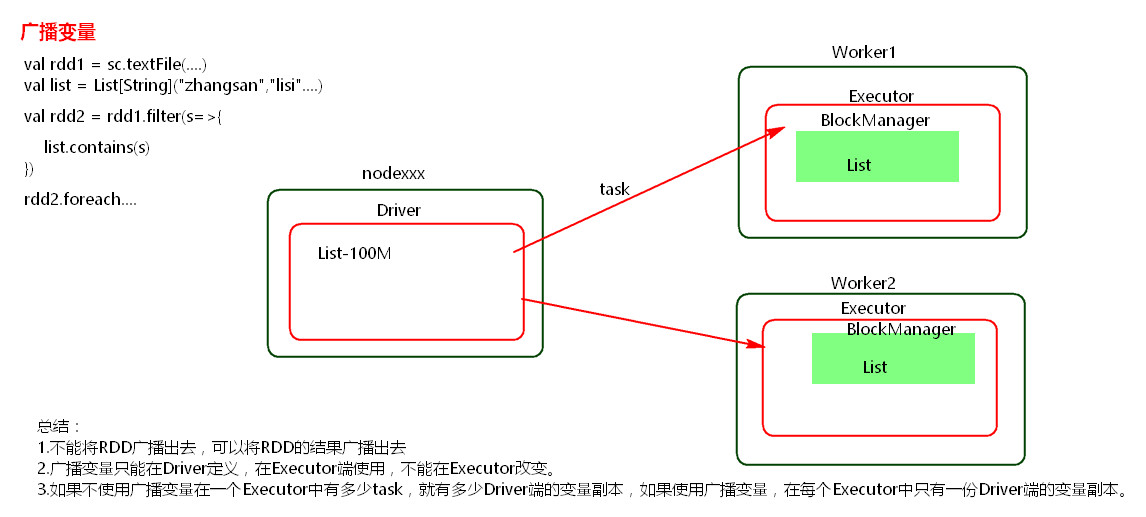
一、广播变量
package com.wjy import org.apache.spark.SparkConf import org.apache.spark.SparkContext object GuboVal { def main(args: Array[String]): Unit = { val conf = new SparkConf(); conf.setMaster("local").setAppName("broadcast"); val sc= new SparkContext(conf); val list = List("hello wjy"); val broadcast = sc.broadcast(list);//定义一个广播变量 val linesRDD = sc.textFile("./data/words.txt"); //广播变量可以在excutor使用 linesRDD.filter{x=>broadcast.value.contains(x)}.foreach(println); sc.stop(); } }
注意:
(1) 能不能将一个RDD使用广播变量广播出去?
不能,因为RDD是不存储数据的。可以将RDD的结果广播出去。
(2)广播变量只能在Driver端定义,不能在Executor端定义。
(3) 在Driver端可以修改广播变量的值,在Executor端无法修改广播变量的值。
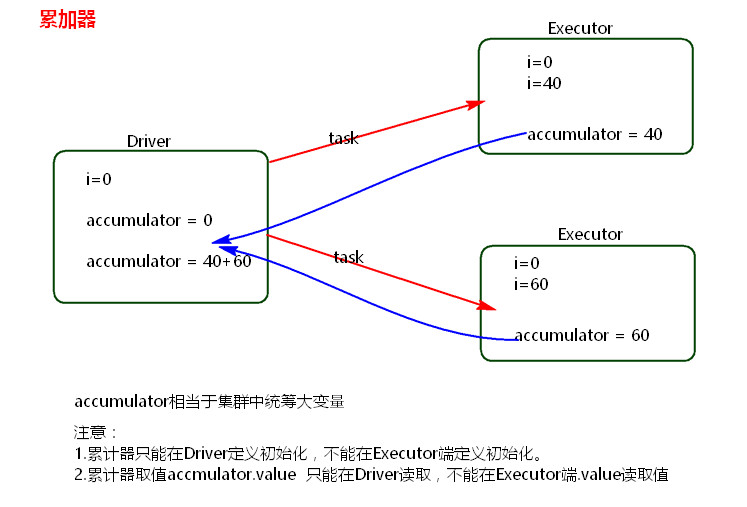
二、累加器
package com.wjy import org.apache.spark.SparkConf import org.apache.spark.SparkContext object accumulator { def main(args: Array[String]): Unit = { val conf =new SparkConf(); conf.setMaster("local").setAppName("accumulator"); val sc = new SparkContext(conf); //创建累加器 累加器可以是整形 也可以是其他自定义对象 val accumulator = sc.accumulator(0); //累加器在excutor里累加 sc.textFile("./data/words.txt").foreach(x=>{accumulator.add(1)}); println(accumulator.value); sc.stop(); } }
注意:
累加器在Driver端定义赋初始值,累加器只能在Driver端读取,在Excutor端更新。
参考:
Spark