大数据第5周
1.Hadoop系统配置
1.1 环境配置
需要配置两个文件:hadoop-env.sh和yarn-env.sh,配置JAVA_HOME变量。
-
vi hadoop-env.sh,修改成了如下内容:

-
vi yarn-env.sh,增加了一句:export JAVA_HOME=/home/user1/jdk1.8。

1.2 配置core-site.xml
在文件中添加如下内容:
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/user1/hadoopdata</value>
</property>

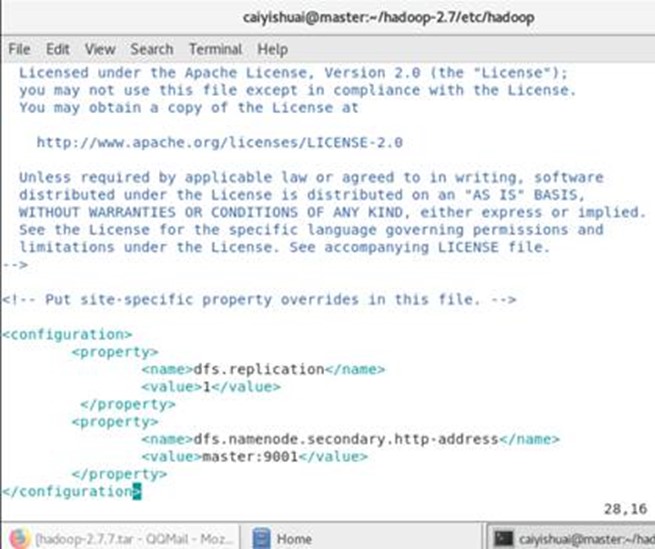
1.3 配置hdfs-site.xml
在文件中添加如下内容:
<property>
<name>dfs.replication</name>
<value>1</value>
<!--设置dfs的副本数,我们设置为1,这种情况下,数据没有任何安全性-->
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
<!--设置secondnamenode的地址,我们当前设置到namenode节点上,这种设置极其不合理,但考虑到我们当前的情况-->
</property>
1.4 配置yarn-site.xml
在文件中添加如下内容:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>

1.5 配置mapred-site.xml
先把模板文件另存为非模板文件:cp mapred-site.xml.template mapred-site.xml
在文件中添加如下内容
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
1.6 配置slaves文件
删除文件原内容,添加
slave0
slave1
2.拷贝hadoop文件包到其他节点。
scp -r hadoop-2.7 slave0:~
scp -r hadoop-2.7 slave1:~
3. 启动hadoop集群前准备
3.1在namenode上建立文件夹
按照core-site.xml文件,建立文件夹。
3.2格式化namenode
hadoop namenode –format
如果显示DEPRECATED: Use of this script to execute hdfs command is deprecated.Instead use the hdfs command for it.
原来从0.21.0版本以后,hadoop 命令换成了hdfs命令,上面的命令如同下面的命令
hdfs namenode –format
命令执行后如果看到这句:


说明格式化成功了。
如格式化不成功,下次格式化之前,需要删除在namenode上建立的文件夹hadoopdata,然后重新建立文件夹hadoopdata。
4.启动Hadoop集群
start-all.sh
执行后,用jps检查java线程,master节点如图,slave节点如图:
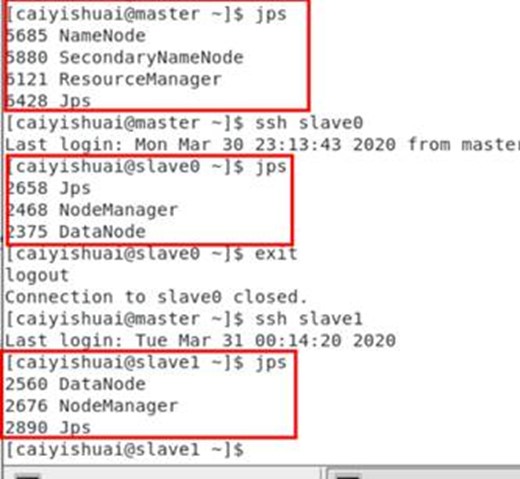
如果不成功,检查配置文件。
测试:上传一个文件到集群 hadoop fs –put 文件名 /,然后检查:hadoop fs –ls /
5关闭集群
stop-all.sh
关闭虚拟机之前,请务必先关闭集群。