介绍
1.什么时候需要进行迁移学习
目前大多数机器学习算法均是假设训练数据以及测试数据的特征分布相同。然而这在现实世界中却时常不可行。例如我们我们要对一个任务进行分类,但是此任务中数据不充足(在迁移学习中也被称为目标域),然而却有大量的相关的训练数据(在迁移学习中也被称为源域),但是此训练数据与所需进行的分类任务中的测试数据特征分布不同(例如语音情感识别中,一种语言的语音数据充足,然而所需进行分类任务的情感数据却极度缺乏),在这种情况下如果可以采用合适的迁移学习方法则可以大大提高样本不充足任务的分类识别结果。也即是大家通常所说的将知识迁移到新环境中的能力,这通常被称为迁移学习。
具体的示例:
- 例如在评价用于对某一品牌的情感分类任务中(假如用户对任一品牌的评价有positive和negative两类),在分类任务之前首先要通过收集大量的用户评价,对其进行标注,然后进行模型的训练。然而现实生活中品牌众多,不同的人也会有不同的语言表达自己的情绪,我们无法收集到非常全面的用户评价的数据,因此当我们直接通过之前训练好的模型进行情感识别时,效果必然会受到影响。如果想要在测试数据上有好的分类效果,最直接的方式是收集大量与测试数据分布相似的数据,但是这样的开销非常大。因此这个时候通过迁移学习可以节省大量的时间和精力,并且通过合适的方法也可以得到较好的识别结果。
- 小数据的问题。比方说新开一个网店,卖一种新的糕点,没有任何的数据,就无法建立模型对用户进行推荐。但用户买一个东西会反映到用户可能还会买另外一个东西,所以如果知道用户在另外一个领域,比方说卖饮料,已经有了很多很多的数据,利用这些数据建一个模型,结合用户买饮料的习惯和买糕点的习惯的关联,就可以把饮料的推荐模型给成功地迁移到糕点的领域,这样,在数据不多的情况下可以成功推荐一些用户可能喜欢的糕点。这个例子就说明,有两个领域,一个领域已经有很多的数据,能成功地建一个模型,有一个领域数据不多,但是和前面那个领域是关联的,就可以把那个模型给迁移过来。
- 个性化的问题。比如每个人都希望自己的手机能够记住一些习惯,这样不用每次都去设定它,怎么才能让手机记住这一点呢?其实可以通过迁移学习把一个通用的用户使用手机的模型迁移到个性化的数据上面。
2.迁移学习的历史
多任务学习和迁移学习相似,但是不同是多任务学习是对目标域和源域进行共同学习,而迁移学习主要是对通过对源域的学习解决目标域的识别任务。
下图展示了传统的机器学习方法与迁移学习的区别:
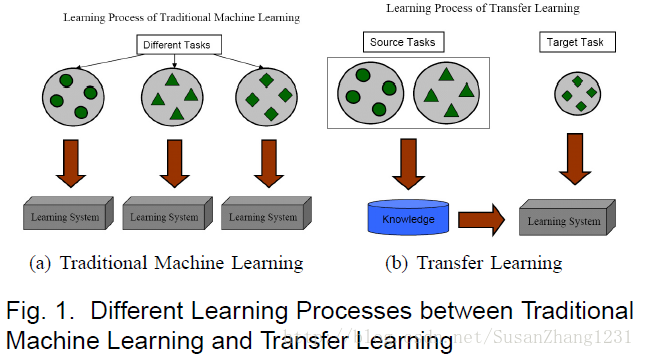
3.迁移什么
在一些学习任务中有一些特征是个体所特有的,这些特征不可以迁移。而有些特征是在所有的个体中具有贡献的,这些可以进行迁移。
4.什么时候迁移
有些时候如果迁移的不合适则会导致负迁移,例如当源域和目标域的任务毫不相关时有可能会导致负迁移。
5.迁移学习主要思想
对于源域和目标域,它们具有一部分相同分布的特征,目标域的数据集小于源域的数据集,举个例子:我们利用CNN对源域进行训练,使用了卷积层和全连接层,我们把卷积层拿来进行复用(这里只是做假设,具体情况尚待验证),将源域训练好的卷积层拿来复用到目标域的卷积层,目标域只需训练全连接层即可,达到了迁移的目的。
例子
在本例中,我们需要用深度学习技术对电影短评进行文本倾向性分析,例如“It was great,loved it.”表示积极正面的评论,“It was really stupid.”表示消极负面的评论。
假设现在可以得到的数据规模只有72条,其中62条没有经过预先的倾向性标记,用来预训练。8条经过了预先的倾向性标记,用来训练模型。2条也经过了预先的倾向性标记,用来测试模型。
由于我们只有8条经过预先标记的训练数据,如果直接以这样的数据量对模型展开训练,无疑最终的测试准确率将非常低。(因为判断结果只有正面和负面两种,因此可以预见最终的测试准确率可能只有50%)
为了解决这个难题,我们引入迁移学习。即首先用62条未经标记的数据对模型展开通用的情感判断,然后在这一预训练的基础上对本例的特定问题展开分析,复用预训练模型中的部分层次(迁移学习主要思想),就可以将最终的测试准确率提升到100%。下面将从3个步骤展开分析。
步骤1
创建预训练模型来分析词与词之间的关系。这里我们通过分析未标记语句中的某一词汇,尝试预测出现在同一句子中的其他词汇。

步骤2
对模型展开训练,使得出现在类似上下文中的词汇获得类似的向量表示。在这一步骤中,62条待处理语句首先会被删除停用词,并被标记解释。之后,针对每个词汇,系统会尝试减小其向量表示与相关词汇的差别,并增加其与不相关词汇的差别。

步骤3
预测一个句子的文本倾向性。由于在此前的预训练模型中我们已经得到了针对所有词汇的向量表示,并且这些向量具有用数字表征的每个词汇的上下文属性,这将使得文本的倾向性分析变得更易于实现。

需要注意的是,这里并非直接使用10个已经被预先标记的句子,而是先将句子的向量设置为其所有词汇的平均值(在实际任务中,我们将使用类似时间递归神经网络LSTM的相关原理)。这样,经过平均化处理的句子向量将作为输入数据导入模型,而句子的正面或负面判定将作为结果输出。需要特别强调的是,这里我们在预训练模型和10个被预先标记的句子之间加入了一个隐藏层(hidden layer),用来适配文本倾向性分析这一特定场景。正如你所看到的,这里只用10个标记量就实现了100%的预测准确率。
当然,必须指出的是,这里展示的只是一个非常简单的模型示意,而且测试用例只有2条。但不可否认的一点是,由于迁移学习的引入,确实使得本例中的文本倾向性预测准确率从50%提升到了100%。
本例的完整代码详见如下链接:https://gist.github.com/prats226/9fffe8ba08e378e3d027610921c51a78