为什么使用线程池
Java中的线程池是运用场景最多的并发框架,几乎所有需要异步或并发执行任务的程序都可以使用线程池。在开发过程中,合理地使用线程池能够带来3个好处。
第一:降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。//Thread t = new Thread(); run();
第二:提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。假设一个服务器完成一项任务所需时间为:T1 创建线程时间,T2 在线程中执行任务的时间,T3 销毁线程时间。 如果:T1 + T3 远大于 T2,则可以采用线程池,以提高服务器性能。线程池技术正是关注如何缩短或调整T1,T3时间的技术,从而提高服务器程序性能的。它把T1,T3分别安排在服务器程序的启动和结束的时间段或者一些空闲的时间段,这样在服务器程序处理客户请求时,不会有T1,T3的开销了。
第三:提高线程的可管理性。线程是稀缺资源,如果无限制地创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一分配、调优和监控。
假设一个服务器一天要处理50000个请求,并且每个请求需要一个单独的线程完成。在线程池中,线程数一般是固定的,所以产生线程总数不会超过线程池中线程的数目,而如果服务器不利用线程池来处理这些请求则线程总数为50000。一般线程池大小是远小于50000。所以利用线程池的服务器程序不会为了创建50000而在处理请求时浪费时间,从而提高效率。
Executor框架
Executor是一个接口,它是Executor框架的基础,它将任务的提交与任务的执行分离开来。
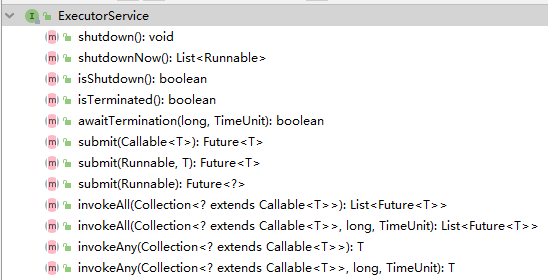
ExecutorService接口继承了Executor,在其上做了一些shutdown()、submit()的扩展,可以说是真正的线程池接口;
AbstractExecutorService抽象类实现了ExecutorService接口中的大部分方法;
ThreadPoolExecutor是线程池的核心实现类,用来执行被提交的任务。
ScheduledExecutorService接口继承了ExecutorService接口,提供了带"周期执行"功能ExecutorService;
ScheduledThreadPoolExecutor是一个实现类,可以在给定的延迟后运行命令,或者定期执行命令。ScheduledThreadPoolExecutor比Timer更灵活,功能更强大。
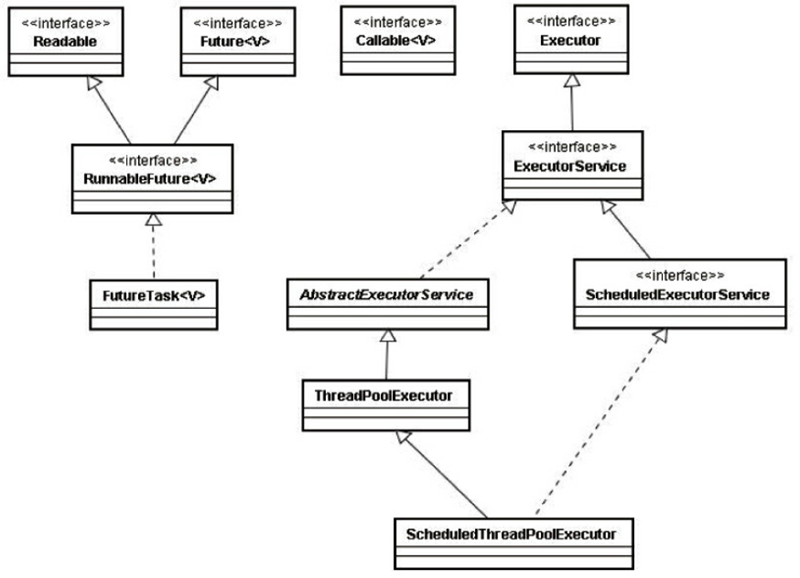

接口->抽象类->实现类
线程池创建参数的含义
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
corePoolSize
线程池中的核心线程数,当提交一个任务时,线程池创建一个新线程执行任务,直到当前线程数等于corePoolSize;
如果当前线程数为corePoolSize,继续提交的任务被保存到阻塞队列中,等待被执行;
如果执行了线程池的prestartAllCoreThreads()方法,线程池会提前创建并启动所有核心线程。
/** * Starts all core threads, causing them to idly wait for work. This * overrides the default policy of starting core threads only when * new tasks are executed. * * @return the number of threads started */ public int prestartAllCoreThreads() { int n = 0; while (addWorker(null, true)) ++n; return n; }
maximumPoolSize
线程池中允许的最大线程数。如果当前阻塞队列满了,且继续提交任务,则创建新的线程执行任务,前提是当前线程数小于maximumPoolSize;
keepAliveTime
线程空闲时的存活时间,即当线程没有任务执行时,继续存活的时间。默认情况下,该参数只在线程数大于corePoolSize时才有用
TimeUnit
keepAliveTime的时间单位
workQueue
workQueue必须是BlockingQueue阻塞队列。当线程池中的线程数超过它的corePoolSize的时候,线程会进入阻塞队列进行阻塞等待。通过workQueue,线程池实现了阻塞功能;
用于保存等待执行的任务的阻塞队列,一般来说,我们应该尽量使用有界队列,因为使用无界队列作为工作队列会对线程池带来如下影响。
1)当线程池中的线程数达到corePoolSize后,新任务将在无界队列中等待,因此线程池中的线程数不会超过corePoolSize。
2)由于1,使用无界队列时maximumPoolSize将是一个无效参数。
3)由于1和2,使用无界队列时keepAliveTime将是一个无效参数。
4)更重要的,使用无界queue可能会耗尽系统资源,有界队列则有助于防止资源耗尽,同时即使使用有界队列,也要尽量控制队列的大小在一个合适的范围。
所以我们一般会使用,ArrayBlockingQueue、LinkedBlockingQueue、SynchronousQueue、PriorityBlockingQueue。
threadFactory
创建线程的工厂,通过自定义的线程工厂可以给每个新建的线程设置一个具有识别度的线程名,当然还可以更加自由的对线程做更多的设置,比如设置所有的线程为守护线程。
Executors静态工厂里默认的threadFactory,线程的命名规则是“pool-数字-thread-数字”。
RejectedExecutionHandler
线程池的饱和策略,当阻塞队列满了,且没有空闲的工作线程,如果继续提交任务,必须采取一种策略处理该任务,线程池提供了4种策略:
(1)AbortPolicy:直接抛出异常,默认策略;
(2)CallerRunsPolicy:用调用者所在的线程来执行任务;
(3)DiscardOldestPolicy:丢弃阻塞队列中靠最前的任务,并执行当前任务;
(4)DiscardPolicy:直接丢弃任务;
当然也可以根据应用场景实现RejectedExecutionHandler接口,自定义饱和策略,如记录日志或持久化存储不能处理的任务。
线程池功能扩展
/** * Method invoked prior to executing the given Runnable in the * given thread. This method is invoked by thread {@code t} that * will execute task {@code r}, and may be used to re-initialize * ThreadLocals, or to perform logging. * * <p>This implementation does nothing, but may be customized in * subclasses. Note: To properly nest multiple overridings, subclasses * should generally invoke {@code super.beforeExecute} at the end of * this method. * * @param t the thread that will run task {@code r} * @param r the task that will be executed */ protected void beforeExecute(Thread t, Runnable r) { }
/**
* Method invoked upon completion of execution of the given Runnable.
* This method is invoked by the thread that executed the task. If
* non-null, the Throwable is the uncaught {@code RuntimeException}
* or {@code Error} that caused execution to terminate abruptly.
*
* <p>This implementation does nothing, but may be customized in
* subclasses. Note: To properly nest multiple overridings, subclasses
* should generally invoke {@code super.afterExecute} at the
* beginning of this method.
*
* <p><b>Note:</b> When actions are enclosed in tasks (such as
* {@link FutureTask}) either explicitly or via methods such as
* {@code submit}, these task objects catch and maintain
* computational exceptions, and so they do not cause abrupt
* termination, and the internal exceptions are <em>not</em>
* passed to this method. If you would like to trap both kinds of
* failures in this method, you can further probe for such cases,
* as in this sample subclass that prints either the direct cause
* or the underlying exception if a task has been aborted:
*
* <pre> {@code
* class ExtendedExecutor extends ThreadPoolExecutor {
* // ...
* protected void afterExecute(Runnable r, Throwable t) {
* super.afterExecute(r, t);
* if (t == null && r instanceof Future<?>) {
* try {
* Object result = ((Future<?>) r).get();
* } catch (CancellationException ce) {
* t = ce;
* } catch (ExecutionException ee) {
* t = ee.getCause();
* } catch (InterruptedException ie) {
* Thread.currentThread().interrupt(); // ignore/reset
* }
* }
* if (t != null)
* System.out.println(t);
* }
* }}</pre>
*
* @param r the runnable that has completed
* @param t the exception that caused termination, or null if
* execution completed normally
*/
protected void afterExecute(Runnable r, Throwable t) { }
/**
* Method invoked when the Executor has terminated. Default
* implementation does nothing. Note: To properly nest multiple
* overridings, subclasses should generally invoke
* {@code super.terminated} within this method.
*/
protected void terminated() { }
每个任务执行前后都会调用 beforeExecute和 afterExecute方法。相当于执行了一个切面。而在调用 shutdown 方法后则会调用 terminated 方法。这些方法都是JDK预留的空方法,可以由我们自定义实现。
线程池工作机制
1)如果当前运行的线程少于corePoolSize,则创建新线程来执行任务(注意,执行这一步骤需要获取全局锁)。
2)如果运行的线程等于或多于corePoolSize,则将任务加入BlockingQueue。
3)如果无法将任务加入BlockingQueue(队列已满),则创建新的线程来处理任务。
4)如果创建新线程将使当前运行的线程超出maximumPoolSize,任务将被拒绝,并调用RejectedExecutionHandler.rejectedExecution()方法。
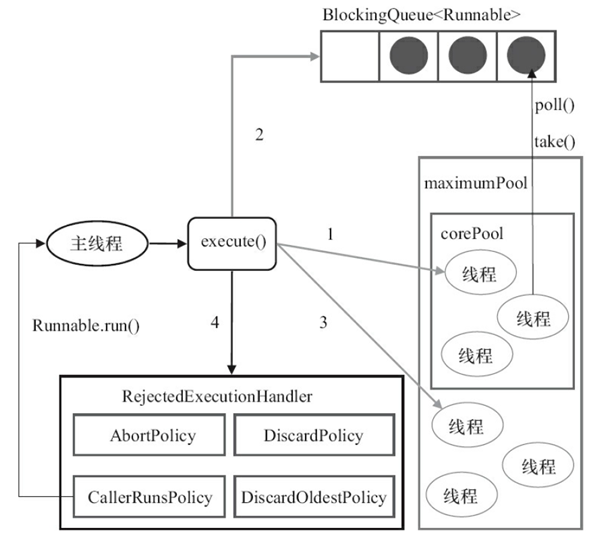
提交任务
execute()方法用于提交不需要返回值的任务,所以无法判断任务是否被线程池执行成功。
submit()方法用于提交需要返回值的任务。线程池会返回一个future类型的对象,通过这个future对象可以判断任务是否执行成功,并且可以通过future的get()方法来获取返回值,get()方法会阻塞当前线程直到任务完成,而使用get(long timeout,TimeUnit unit)方法则会阻塞当前线程一段时间后立即返回,这时候有可能任务没有执行完。
关闭线程池
可以通过调用线程池的shutdown或shutdownNow方法来关闭线程池。它们的原理是遍历线程池中的工作线程,然后逐个调用线程的interrupt方法来中断线程,所以无法响应中断的任务可能永远无法终止。但是它们存在一定的区别,shutdownNow首先将线程池的状态设置成STOP,然后尝试停止所有的正在执行或暂停任务的线程,并返回等待执行任务的列表,而shutdown只是将线程池的状态设置成SHUTDOWN状态,然后中断所有没有正在执行任务的线程。
只要调用了这两个关闭方法中的任意一个,isShutdown方法就会返回true。当所有的任务都已关闭后,才表示线程池关闭成功,这时调用isTerminaed方法会返回true。至于应该调用哪一种方法来关闭线程池,应该由提交到线程池的任务特性决定,通常调用shutdown方法来关闭线程池,如果任务不一定要执行完,则可以调用shutdownNow方法。
使用示例:
public class UseThreadPool { //无返回值 public static class Worker implements Runnable { private String taskName; private Random r = new Random(); public Worker(String taskName) { this.taskName = taskName; } public String getTaskName() { return taskName; } @Override public void run() { System.out.println(Thread.currentThread().getName() + "process the task:" + taskName); SleepTools.ms(r.nextInt(100) * 5); } } //有返回值 static class CallWorker implements Callable<String> { private String taskName; private Random r = new Random(); public CallWorker(String taskName) { this.taskName = taskName; } public String getTaskName() { return taskName; } @Override public String call() throws Exception { System.out.println(Thread.currentThread().getName() + " process the task : " + taskName); return Thread.currentThread().getName() + ":" + r.nextInt(100) * 5; } } public static void main(String[] args) throws ExecutionException, InterruptedException { ExecutorService threadPool = new ThreadPoolExecutor(2, 4, 3, TimeUnit.SECONDS, new ArrayBlockingQueue<>(5), new ThreadPoolExecutor.DiscardPolicy()); for (int i = 0; i <= 6; i++) { Worker worker = new Worker("work:" + i); System.out.println("A new task has been added : " + worker.getTaskName()); threadPool.execute(worker); } for (int i = 0; i <= 6; i++) { CallWorker callWorker = new CallWorker("callWork:" + i); System.out.println("A new task has been added : " + callWorker.getTaskName()); Future<String> future = threadPool.submit(callWorker); System.out.println(future.get()); } threadPool.shutdown();//中断空闲线程 // threadPool.shutdownNow();//中断所有线程 } }
合理配置线程池
要想合理地配置线程池,就必须首先分析任务特性,可以从以下几个角度来分析。
•任务的性质:CPU密集型任务、IO密集型任务和混合型任务。
•任务的优先级:高、中和低。
•任务的执行时间:长、中和短。
•任务的依赖性:是否依赖其他系统资源,如数据库连接。
性质不同的任务可以用不同规模的线程池分开处理。
CPU密集型任务应配置尽可能小的线程,如配置Ncpu+1个线程的线程池。由于IO密集型任务线程并不是一直在执行任务,则应配置尽可能多的线程,如2*Ncpu。
混合型的任务,如果可以拆分,将其拆分成一个CPU密集型任务和一个IO密集型任务,只要这两个任务执行的时间相差不是太大,那么分解后执行的吞吐量将高于串行执行的吞吐量。如果这两个任务执行时间相差太大,则没必要进行分解。可以通过Runtime.getRuntime().availableProcessors()方法获得当前设备的CPU个数。
优先级不同的任务可以使用优先级队列PriorityBlockingQueue来处理。它可以让优先级高的任务先执行。
执行时间不同的任务可以交给不同规模的线程池来处理,或者可以使用优先级队列,让执行时间短的任务先执行。
依赖数据库连接池的任务,因为线程提交SQL后需要等待数据库返回结果,等待的时间越长,则CPU空闲时间就越长,那么线程数应该设置得越大,这样才能更好地利用CPU。
建议使用有界队列。有界队列能增加系统的稳定性和预警能力,可以根据需要设大一点儿,比如几千。
假设,我们现在有一个Web系统,里面使用了线程池来处理业务,在某些情况下,系统里后台任务线程池的队列和线程池全满了,不断抛出抛弃任务的异常,通过排查发现是数据库出现了问题,导致执行SQL变得非常缓慢,因为后台任务线程池里的任务全是需要向数据库查询和插入数据的,所以导致线程池里的工作线程全部阻塞,任务积压在线程池里。
如果当时我们设置成无界队列,那么线程池的队列就会越来越多,有可能会撑满内存,导致整个系统不可用,而不只是后台任务出现问题。
预定义线程池
FixedThreadPool详解
创建使用固定线程数的FixedThreadPool的API。适用于为了满足资源管理的需求,而需求要限制当前线程数量的应用场景,它适用于负载比较重的服务器。FixedThreadPool的corePoolSize和maxmumPoolSize都被设置为创建FixedThreadPool时指定的参数nThreads。
当前线程池中的线程数大于corePoolSize时,keepAliveTime为多余的空闲线程等待新任务的最长时间,超过这个时间后多余的线程将被终止。这里把keepAliveTime设置为0L,意味着多余的线程会被 立即终止。
FixedThreadlPool使用有界队列LinkedBlockingQueue作为线程池的工作队列(队列的容量为Inter.MAX_VALUE)。
SingleThreadExecutor
创建使用单个线程的SingleThread-Executor的API,于需要保证顺序地执行各个任务;并且在任意时间点,不会有多个线程是活动的应用场景。
corePoolSize和maximumPoolSize被设置为1。其他参数与FixedThreadPool相同。SingleThreadExecutor使用有界队列LinkedBlockingQueue作为线程池的工作队列(队列的容量为Integer.MAX_VALUE)。
CacheThreadPool
创建一个会根据需要创建新线程的CachedThreadPool的API。大小无界的线程池,适用于执行很多的短期异步任务的小程序,或者是负载较轻的服务器。
corePoolSize被设置为0,即corePool为空;maximumPoolSize被设置为Integer.MAX_VALUE。这里把keepAliveTime设置为60L,意味着CachedThreadPool中的空闲线程等待新任务的最长时间为60秒,空闲线程超过60秒后将会被终止。
FixedThreadPool和SingleThreadExecutor使用有界队列LinkedBlockingQueue作为线程池的工作队列。CachedThreadPool使用没有容量的SynchronousQueue作为线程池的工作队列,但CachedThreadPool的maximumPool是无界的。这意味着,如果主线程提交任务的速度高于maximumPool中线程处理任务的速度时,CachedThreadPool会不断创建新线程。极端情况下,CachedThreadPool会因为创建过多线程而耗尽CPU和内存资源。
WorkStealingPool
利用所有运行的处理器数目来创建一个工作窃取的线程池,使用forkjoin实现
ScheduleThreadPoolExecutor
使用工厂类Executors来创建。Executors可以创建2种类型的ScheduledThreadPoolExecutor,如下。
•ScheduledThreadPoolExecutor。包含若干个线程的ScheduledThreadPoolExecutor。
•SingleThreadScheduledExecutor。只包含一个线程的ScheduledThreadPoolExecutor。
ScheduledThreadPoolExecutor适用于需要多个后台线程执行周期任务,同时为了满足资源管理的需求而需要限制后台线程的数量的应用场景。
SingleThreadScheduledExecutor适用于需要单个后台线程执行周期任务,同时需要保证顺序地执行各个任务的应用场景。
提交定时任务
public ScheduledFuture<?> schedule(Runnable command, long delay, TimeUnit unit)
//向定时任务线程池提交一个延时Runnable任务(仅执行一次)
public <V> ScheduledFuture<V> schedule(Callable<V> callable, long delay, TimeUnit unit);
//向定时任务线程池提交一个延时的Callable任务(仅执行一次)
public ScheduledFuture<?> scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit)
//向定时任务线程池提交一个固定时间间隔执行的任务
public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command, long initialDelay, long delay, TimeUnit unit);
//向定时任务线程池提交一个固定延时间隔执行的任务
固定时间间隔的任务不论每次任务花费多少时间,下次任务开始执行时间从理论上讲是确定的,当然执行任务的时间不能超过执行周期。
固定延时间隔的任务是指每次执行完任务以后都延时一个固定的时间。由于操作系统调度以及每次任务执行的语句可能不同,所以每次任务执行所花费的时间是不确定的,也就导致了每次任务的执行周期存在一定的波动。
定时任务超时问题
scheduleAtFixedRate中,若任务处理时长超出设置的定时频率时长,本次任务执行完才开始下次任务,下次任务已经处于超时状态,会马上开始执行。
若任务处理时长小于定时频率时长,任务执行完后,定时器等待,下次任务会在定时器等待频率时长后执行。
示例:
设置定时任务每60s执行一次,那么从理论上应该第一次任务在第0s开始,第二次任务在第60s开始,第三次任务在120s开始,但实际运行时第一次任务时长80s,第二次任务时长30s,第三次任务时长50s,则实际运行结果为:
第一次任务第0s开始,第80s结束;
第二次任务第80s开始,第110s结束(上次任务已超时,本次不会再等待60s,会马上开始);
第三次任务第120s开始,第170s结束.
第四次任务第180s开始.....
CompletionService
CompletionService实际上可以看做是Executor和BlockingQueue的结合体。CompletionService在接收到要执行的任务时,通过类似BlockingQueue的put和take获得任务执行的结果。
CompletionService的一个实现是ExecutorCompletionService,ExecutorCompletionService把具体的计算任务交给Executor完成。
在实现上,ExecutorCompletionService在构造函数中会创建一个BlockingQueue(使用的基于链表的LinkedBlockingQueue),该BlockingQueue的作用是保存Executor执行的结果。
当提交一个任务到ExecutorCompletionService时,首先将任务包装成QueueingFuture,它是FutureTask的一个子类,然后改写FutureTask的done方法,之后把Executor执行的计算结果放入BlockingQueue中。
与ExecutorService最主要的区别在于submit的task不一定是按照加入时的顺序完成的。CompletionService对ExecutorService进行了包装,内部维护一个保存Future对象的BlockingQueue。只有当这个Future对象状态是结束的时候,才会加入到这个Queue中,take()方法其实就是Producer-Consumer中的Consumer。它会从Queue中取出Future对象,如果Queue是空的,就会阻塞在那里,直到有完成的Future对象加入到Queue中。所以,先完成的必定先被取出。这样就减少了不必要的等待时间。
参见代码cn.enjoyedu.ch6.comps. CompletionCase,我们可以得出结论:
使用方法一,自己创建一个集合来保存Future存根并循环调用其返回结果的时候,主线程并不能保证首先获得的是最先完成任务的线程返回值。它只是按加入线程池的顺序返回。因为take方法是阻塞方法,后面的任务完成了,前面的任务却没有完成,主程序就那样等待在那儿,只到前面的完成了,它才知道原来后面的也完成了。
使用方法二,使用CompletionService来维护处理线程不的返回结果时,主线程总是能够拿到最先完成的任务的返回值,而不管它们加入线程池的顺序。
参考:http://enjoy.ke.qq.com