—本博客为原创内容,转载需注明本人—
前几天有个师妹将要毕业,需要准备毕业论文,但是论文调研需要数据资料,上知网一查,十几万条数据!指导老师让她手动copy收集,十几万的数据手动copy要浪费多少时间啊,然后她就找我帮忙。我想了一下,写个爬虫程序去爬下来或许是个不错的解决方案呢!之前一直听其他人说爬虫最好用python,但是我是一名Java工程师啊!鲁迅曾说过,学python救不了中国人,但是Java可以!

![]()
好啦,开个玩笑,主要是她急着要,我单独学一门语言去做爬虫,有点不现实,然后我就用了Java,去知乎看一下,发现原来Java也有很多开源的爬虫api嘛,然后就是开始干了,三天时间写好程序,可以爬数据下来,下面分享一下技术总结,感兴趣的朋友可以一起交流一下!
![]()
在分享技术之前,先简单说一下爬虫的原理吧。网络爬虫听起来很高大上,其实就是原理很简单,说的通俗一点就是,程序向指定连接发出请求,服务器返回完整的html回来,程序拿到这个html之后就进行解析,解析的原理就是定位html元素,然后将你想要的数据拿下来。
那再看一下Java开源的爬虫API,挺多的,具体可以点击链接看一下:推荐一些优秀的开源Java爬虫项目
因为我不是要在实际的项目中应用,所以我选择非常轻量级易上手的 crawler4j 。感兴趣的可以去github看看它的介绍,我这边简单介绍一下怎么应用。用起来非常简单,现在maven导入依赖。
<dependency>
<groupId>edu.uci.ics</groupId>
<artifactId>crawler4j</artifactId>
<version>4.2</version>
</dependency>自定义爬虫类继承插件的WebCrawler类,然后重写里面shouldVisit和Visit方法。
package com.chf;
import edu.uci.ics.crawler4j.crawler.Page;
import edu.uci.ics.crawler4j.crawler.WebCrawler;
import edu.uci.ics.crawler4j.parser.HtmlParseData;
import edu.uci.ics.crawler4j.url.WebURL;
import java.util.Set;
import java.util.regex.Pattern;
/**
* @author:chf
* @description: 自定义爬虫类需要继承WebCrawler类,决定哪些url可以被爬以及处理爬取的页面信息
* @date:2019/3/8
**/
public class MyCraeler extends WebCrawler {
/**
* 正则匹配指定的后缀文件
*/
private final static Pattern FILTERS = Pattern.compile(".*(\.(css|js|bmp|gif|jpe?g" + "|png|tiff?|mid|mp2|mp3|mp4"
+ "|wav|avi|mov|mpeg|ram|m4v|pdf" + "|rm|smil|wmv|swf|wma|zip|rar|gz))$");
/**
* 这个方法主要是决定哪些url我们需要抓取,返回true表示是我们需要的,返回false表示不是我们需要的Url
* 第一个参数referringPage封装了当前爬取的页面信息
* 第二个参数url封装了当前爬取的页面url信息
*/
@Override
public boolean shouldVisit(Page referringPage, WebURL url) {
String href = url.getURL().toLowerCase(); // 得到小写的url
return !FILTERS.matcher(href).matches() // 正则匹配,过滤掉我们不需要的后缀文件
&& href.startsWith("http://r.cnki.net/kns/brief/result.aspx"); // url必须是http://www.java1234.com/开头,规定站点
}
/**
* 当我们爬到我们需要的页面,这个方法会被调用,我们可以尽情的处理这个页面
* page参数封装了所有页面信息
*/
@Override
public void visit(Page page) {
String url = page.getWebURL().getURL(); // 获取url
System.out.println("URL: " + url);
if (page.getParseData() instanceof HtmlParseData) { // 判断是否是html数据
HtmlParseData htmlParseData = (HtmlParseData) page.getParseData(); // 强制类型转换,获取html数据对象
String text = htmlParseData.getText(); // 获取页面纯文本(无html标签)
String html = htmlParseData.getHtml(); // 获取页面Html
Set<WebURL> links = htmlParseData.getOutgoingUrls(); // 获取页面输出链接
System.out.println("纯文本长度: " + text.length());
System.out.println("html长度: " + html.length());
System.out.println("输出链接个数: " + links.size());
}
}
}
然后定义一个Controller来执行你的爬虫类
package com.chf;
import edu.uci.ics.crawler4j.crawler.CrawlConfig;
import edu.uci.ics.crawler4j.crawler.CrawlController;
import edu.uci.ics.crawler4j.fetcher.PageFetcher;
import edu.uci.ics.crawler4j.robotstxt.RobotstxtConfig;
import edu.uci.ics.crawler4j.robotstxt.RobotstxtServer;
/**
* @author:chf
* @description: 爬虫机器人控制器
* @date:2019/3/8
**/
public class Controller {
public static void main(String[] args) throws Exception {
String crawlStorageFolder = "C:/Users/94068/Desktop/logs/crawl"; // 定义爬虫数据存储位置
int numberOfCrawlers =2; // 定义7个爬虫,也就是7个线程
CrawlConfig config = new CrawlConfig(); // 定义爬虫配置
config.setCrawlStorageFolder(crawlStorageFolder); // 设置爬虫文件存储位置
/*
* 最多爬取多少个页面
*/
config.setMaxPagesToFetch(1000);
//爬取二进制文件
// config.setIncludeBinaryContentInCrawling(true);
//爬取深度
config.setMaxDepthOfCrawling(1);
/*
* 实例化爬虫控制器
*/
PageFetcher pageFetcher = new PageFetcher(config); // 实例化页面获取器
RobotstxtConfig robotstxtConfig = new RobotstxtConfig(); // 实例化爬虫机器人配置 比如可以设置 user-agent
// 实例化爬虫机器人对目标服务器的配置,每个网站都有一个robots.txt文件 规定了该网站哪些页面可以爬,哪些页面禁止爬,该类是对robots.txt规范的实现
RobotstxtServer robotstxtServer = new RobotstxtServer(robotstxtConfig, pageFetcher);
// 实例化爬虫控制器
CrawlController controller = new CrawlController(config, pageFetcher, robotstxtServer);
/**
* 配置爬虫种子页面,就是规定的从哪里开始爬,可以配置多个种子页面
*/
controller.addSeed("http://r.cnki.net/kns/brief/result.aspx?dbprefix=gwkt");
/**
* 启动爬虫,爬虫从此刻开始执行爬虫任务,根据以上配置
*/
controller.start(MyCraeler.class, numberOfCrawlers);
}
}
直接运行main方法,你的第一个爬虫程序就完成了,非常容易上手。
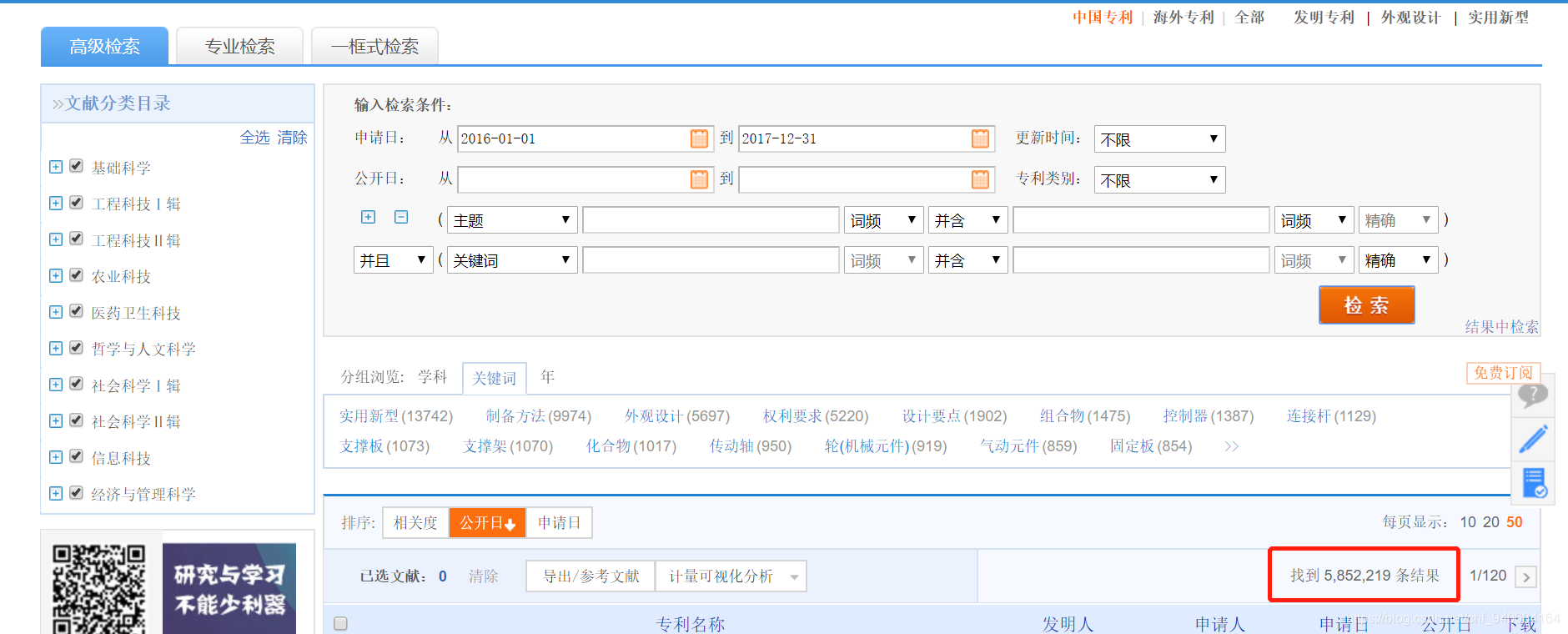
那接下来我们说一下程序的应用,我需要抓取中国知网上2016-2017两年的中国专利数据。
![]()
那么说一下这个应用的几个难点。
1.知网的接口使用asp.net做的,每次请求接口都要传当前的cookies,接口不直接返回数据,而是返回HTML界面
2.数据量过于庞大,而且需要爬取的是动态资源数据,需要输入条件检索之后,才能有数据
3.数据检索是内部用js进行跳转,直接访问链接没有数据出来
4.这个是最难的,知网做了反爬虫设置,当点击了15次下一页之后,网页提示输入验证码,才能继续下一页的操作
那接下来就根据以上的难点来一步一步的想解决方案吧。
首先就是数据检索是内部用js进行跳转,直接访问链接没有数据出来,这就表示上面的crawler4j没有用了,因为他是直接访问连接去拿html代码然后解析拿数据的。然后我再网上查了一下资料,发现Java有一个HtmlUtil。他相当于一个Java的浏览器,这简直是一个神器啊,访问到网页之后还能对返回来的网页进行操作,我用个工具类来创建它
<!-- 获取js动态生成之后的html -->
<dependency>
<groupId>net.sourceforge.htmlunit</groupId>
<artifactId>htmlunit</artifactId>
<version>2.29</version>
</dependency>package com.chf.Utils;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.FailingHttpStatusCodeException;
import com.gargoylesoftware.htmlunit.NicelyResynchronizingAjaxController;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import java.io.IOException;
import java.net.MalformedURLException;
/**
* @author:chf
* @description:模拟浏览器执行各种操作
* @date:2019/3/20
**/
public class HtmlUtil {
/*
* 启动JS
*/
public static WebClient iniParam_Js() {
final WebClient webClient = new WebClient(BrowserVersion.CHROME);
// 启动JS
webClient.getOptions().setJavaScriptEnabled(true);
//将ajax解析设为可用
webClient.getOptions().setActiveXNative(true);
//设置Ajax的解析器
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
// 禁止CSS
webClient.getOptions().setCssEnabled(false);
// 启动客户端重定向
webClient.getOptions().setRedirectEnabled(true);
// JS遇到问题时,不抛出异常
webClient.getOptions().setThrowExceptionOnScriptError(false);
// 设置超时
webClient.getOptions().setTimeout(10000);
//禁止下载照片
webClient.getOptions().setDownloadImages(false);
return webClient;
}
/*
* 禁止JS
*/
public static WebClient iniParam_NoJs() {
final WebClient webClient = new WebClient(BrowserVersion.CHROME);
// 禁止JS
webClient.getOptions().setJavaScriptEnabled(false);
// 禁止CSS
webClient.getOptions().setCssEnabled(false);
// 将返回错误状态码错误设置为false
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
// 启动客户端重定向
webClient.getOptions().setRedirectEnabled(true);
// 设置超时
webClient.getOptions().setTimeout(5000);
//禁止下载照片
webClient.getOptions().setDownloadImages(false);
return webClient;
}
/**
* 根据url获取页面,这里需要加载JS
* @param url
* @return 网页
* @throws FailingHttpStatusCodeException
* @throws MalformedURLException
* @throws IOException
*/
public static HtmlPage getPage_Js(String url) throws FailingHttpStatusCodeException, MalformedURLException, IOException{
final WebClient webClient = iniParam_Js();
HtmlPage page = webClient.getPage(url);
//webClient.waitForBackgroundJavaScriptStartingBefore(5000);
return page;
}
/**
* 根据url获取页面,这里不加载JS
* @param url
* @return 网页
* @throws FailingHttpStatusCodeException
* @throws MalformedURLException
* @throws IOException
*/
public static HtmlPage getPage_NoJs(String url) throws FailingHttpStatusCodeException, MalformedURLException, IOException {
final WebClient webClient = iniParam_NoJs();
HtmlPage page = webClient.getPage(url);
return page;
}
}
有了这个HtmlUtil,基本已经解决了大部分问题,我这里的操作逻辑是先用HtmlUtil访问知网,然后用定位器找到条件,输入搜索条件,然后点击检索按钮,用Java程序模拟人在浏览器的操作。
//获取客户端,禁止JS
WebClient webClient = HtmlUtil.iniParam_Js();
//获取搜索页面,搜索页面包含多个学者,机构通常是非完全匹配,姓名是完全匹配的,我们需要对所有的学者进行匹配操作
HtmlPage page = webClient.getPage(orgUrl);
// 根据名字得到一个表单,查看上面这个网页的源代码可以发现表单的名字叫“f”
final HtmlForm form = page.getFormByName("Form1");
// 同样道理,获取”检 索“这个按钮
final HtmlButtonInput button = form.getInputByValue("检 索");
// 得到搜索框
final HtmlTextInput from = form.getInputByName("publishdate_from");
final HtmlTextInput to = form.getInputByName("publishdate_to");
//设置搜索框的value
from.setValueAttribute("2016-01-01");
to.setValueAttribute("2016-12-31");
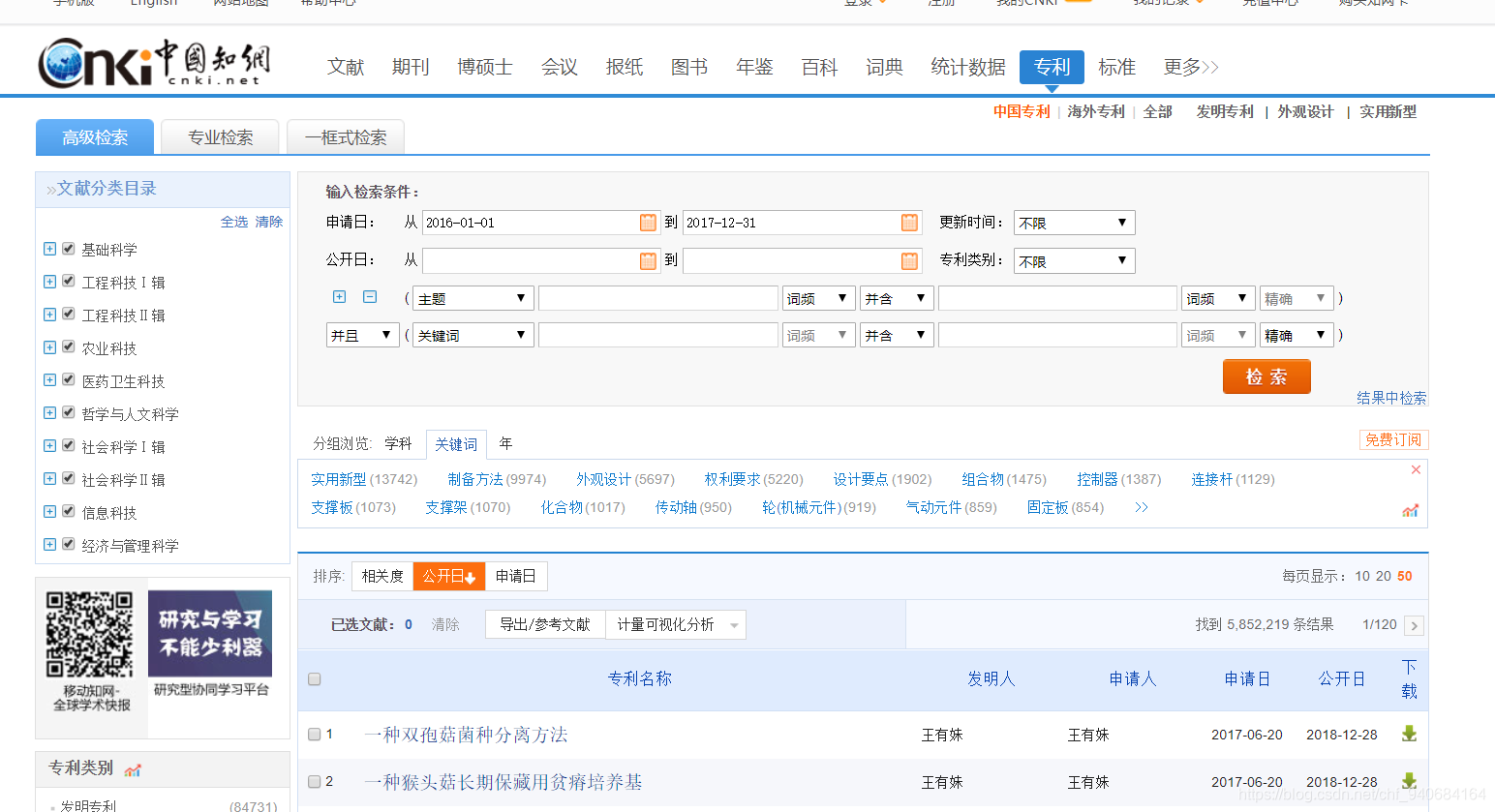
// 设置好之后,模拟点击按钮行为。
final HtmlPage nextPage = button.click();
HtmlAnchor date=nextPage.getAnchorByText("申请日");
final HtmlPage secondPage = date.click();
HtmlAnchor numNow=secondPage.getAnchorByText("50");
final HtmlPage thirdPage = numNow.click();
上述代码的thirdPage就是最终有数据的html页面。
![]()
那下面就是爬虫最关键的一个地方,解析爬下来的html代码,分析html代码的话,我就不在这里分析,html基础不好的朋友可以去w3cshool补一下,我这里直接说HtmlUtil定位html元素的的方法吧。上面的代码可以看到HtmlUtil可以通过value,text,id,name定位元素,如果上面这些都定位不了元素的话,那就使用Xpath来定位。
//解析知网原网页,获取列表的所有链接
List<HtmlAnchor> anchorList=thirdPage.getByXPath("//table[@class='GridTableContent']/tbody/tr/td/a[@class='fz14']");
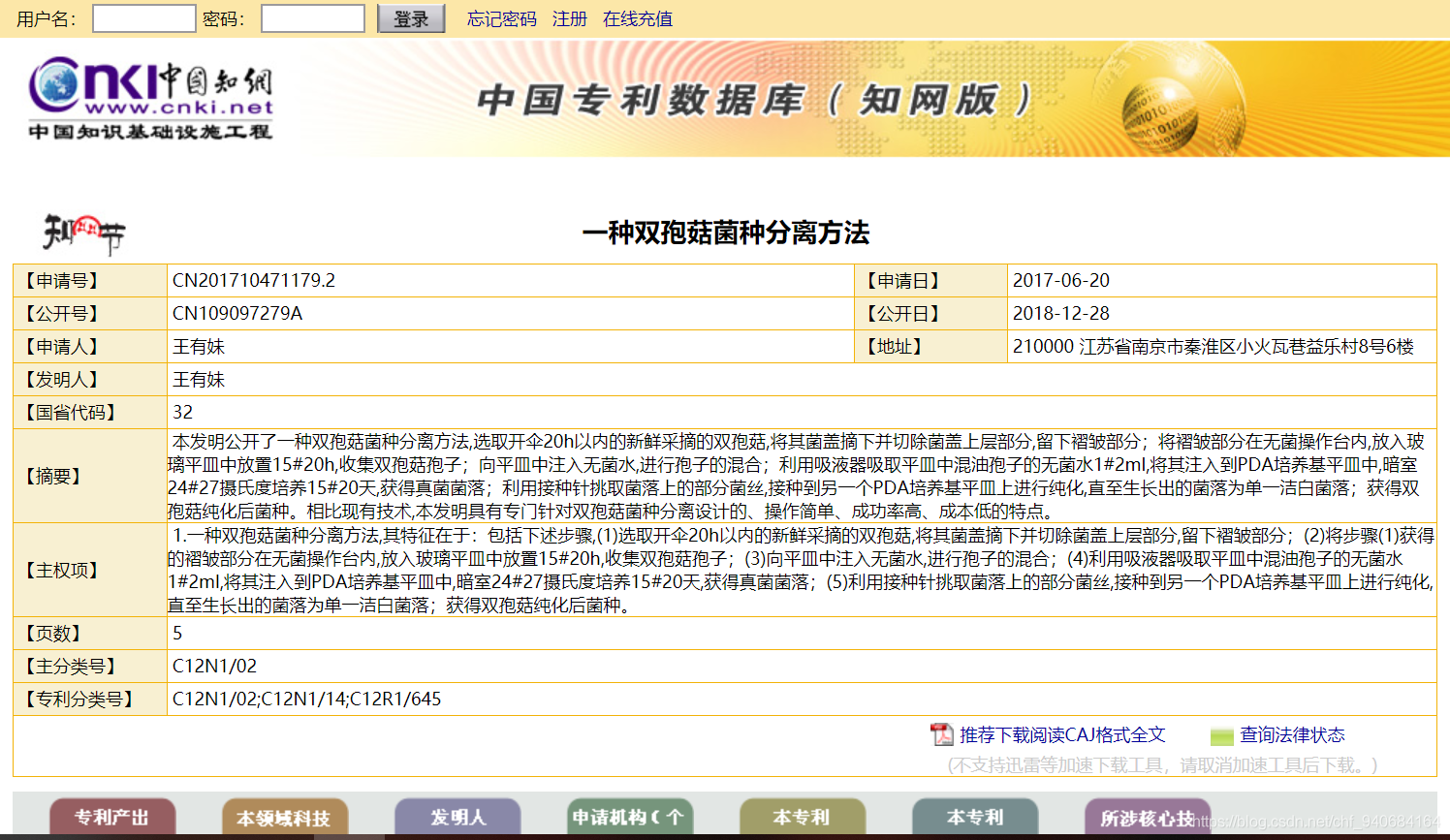
那拿到列表数据之后呢,我就用HtmlUtil一个个点击进去,进去专利的详情页。
![]()
这里面的专利名,申请日期,申请人和地址就是我要爬的数据,因为详情页的html比较复杂,我使用了Java一个比较好用的html解析器jsoup
<!-- jsoup的支持 -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.7.3</version>
</dependency>private static PatentDoc analyzeDetailPage(String detailPage) {
PatentDoc pc=new PatentDoc();
Document doc = Jsoup.parse(detailPage);
Element title=doc.select("td[style=font-size:18px;font-weight:bold;text-align:center;]").first();
Elements table=doc.select("table[id=box]>tbody>tr>td");
for (Element td:table) {
if (td.attr("width").equals("471") && td.attr("bgcolor").equals("#FFFFFF") && td.attr("class").equals("checkItem")){
String patentNo=td.text().replace(" ","");
pc.setPatentNo(patentNo);
}
if (td.attr("width").equals("294") && td.attr("bgcolor").equals("#FFFFFF")){
String patentDate=td.text().replace(" ","");
pc.setPatentDate(patentDate);
}
if (td.attr("bgcolor").equals("#FFFFFF") && td.attr("class").equals("checkItem")){
String patentPerson=td.text().replace(" ","");
pc.setPatentPerson(patentPerson);
}
if (td.attr("bgcolor").equals("#f8f0d2") && td.text().equals(" 【地址】")){
int index=table.indexOf(td);
String patentAdress=table.get(index+1).text().replace(" ","");
pc.setPatentAdress(patentAdress);
break;
}
}
pc.setPatentName(title.text());
return pc;
}解析完之后呢,将数据封装到对象里,然后将对象存在一个List里,全部数据解析完之后,就把数据导出的csv文件中。
String path = "C://exportParent";
String fileName = "导出专利";
String fileds[] = new String[] { "patentName", "patentPerson","patentDate", "patentNo","patentAdress"};// 设置列英文名(也就是实体类里面对应的列名)
CSVUtils.createCSVFile(resultList, fileds, map, path,fileName);
resultList.clear();这样爬虫程序就基本写好了,运行一下发现效率太慢了,爬一页列表的数据加导出,花了1分多钟,然后我优化了一下程序,将解析和导出业务逻辑开一条线程来做,主线程负责操作HtmlUtil和返回Html。
//建立线程池管理线程
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(3);
//利用线程池开启线程解析首页的数据
fixedThreadPool.execute(new AnalyzedTask(lastOnePage,18));package com.chf.enilty;
import com.chf.Utils.CSVUtils;
import com.gargoylesoftware.htmlunit.html.HtmlAnchor;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.util.ArrayList;
import java.util.LinkedHashMap;
import java.util.List;
/**
* @author:chf
* @description: 解析详情并导出出的线程
* @date:2019/3/20
**/
public class AnalyzedTask implements Runnable{
//建立返回结果对象集
List<PatentDoc> resultList=new ArrayList<>();
private HtmlPage lastOnePage =null;
private int curPage=0;
public AnalyzedTask(HtmlPage lastOnePage,int curPage) {
this.lastOnePage = lastOnePage;
this.curPage=curPage;
}
@Override
public void run() {
/** 获取当前系统时间*/
long startTime = System.currentTimeMillis();
System.out.println("线程开始第"+curPage+"页的解析数据。");
//解析首页的数据
try {
startAnalyzed(lastOnePage);
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("第"+curPage+"页数据解析完成。耗时:"+((System.currentTimeMillis()-startTime)/1000)+"s");
}
//开始解析列表数据
private void startAnalyzed(HtmlPage thirdPage) throws Exception {
//解析知网原网页,获取列表的所有链接
List<HtmlAnchor> anchorList=thirdPage.getByXPath("//table[@class='GridTableContent']/tbody/tr/td/a[@class='fz14']");
//遍历点击链接,抓取数据
for (HtmlAnchor anchor:anchorList) {
HtmlPage detailPage = anchor.click();
PatentDoc pc=analyzeDetailPage(detailPage.asXml());
resultList.add(pc);
}
LinkedHashMap map = new LinkedHashMap();
map.put("1", "专利名");
map.put("2", "申请人");
map.put("3", "申请日期");
map.put("4", "申请号");
map.put("5", "申请地址");
String path = "C://exportParent";
String fileName = "导出专利";
String fileds[] = new String[] { "patentName", "patentPerson","patentDate", "patentNo","patentAdress"};// 设置列英文名(也就是实体类里面对应的列名)
CSVUtils.createCSVFile(resultList, fileds, map, path,fileName);
resultList.clear();
}
private PatentDoc analyzeDetailPage(String detailPage) {
PatentDoc pc=new PatentDoc();
Document doc = Jsoup.parse(detailPage);
Element title=doc.select("td[style=font-size:18px;font-weight:bold;text-align:center;]").first();
Elements table=doc.select("table[id=box]>tbody>tr>td");
for (Element td:table) {
if (td.attr("width").equals("471") && td.attr("bgcolor").equals("#FFFFFF") && td.attr("class").equals("checkItem")){
String patentNo=td.text().replace(" ","");
pc.setPatentNo(patentNo);
}
if (td.attr("width").equals("294") && td.attr("bgcolor").equals("#FFFFFF")){
String patentDate=td.text().replace(" ","");
pc.setPatentDate(patentDate);
}
if (td.attr("bgcolor").equals("#FFFFFF") && td.attr("class").equals("checkItem")){
String patentPerson=td.text().replace(" ","");
pc.setPatentPerson(patentPerson);
}
if (td.attr("bgcolor").equals("#f8f0d2") && td.text().equals(" 【地址】")){
int index=table.indexOf(td);
String patentAdress=table.get(index+1).text().replace(" ","");
pc.setPatentAdress(patentAdress);
break;
}
}
pc.setPatentName(title.text());
return pc;
}
}
现在再跑程序,速度快了一点,也能把数据爬下来了,项目源码可以在我的github下载:项目源码,感兴趣的同学可以下载来跑一下。有问题的可以在评论区交流,小弟我没什么经验,如果有什么问题还请指出,大家一起交流。
现在还有个难点没有解决就是知网的验证码验证,我这边想到的一个笨方法是缩小搜索范围,减少数据量从而减少点击下一页的次数来跳过验证码验证,不过这个需要手动改条件,重复跑很多次程序,如果有大佬有好的解决方案也可提出来。谢谢啦!