zoukankan
html css js c++ java
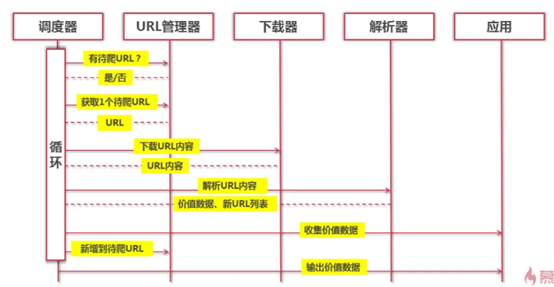
简单爬虫架构解析
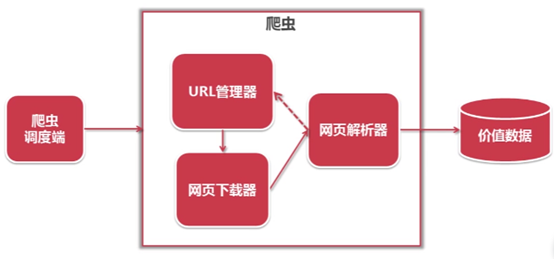
整体架构
主函数
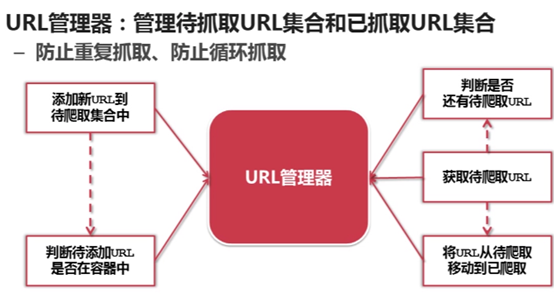
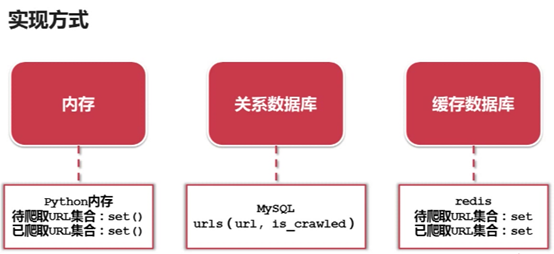
一、 URL管理器
管理即将爬取的URL和已经爬取的URL
URL管理器
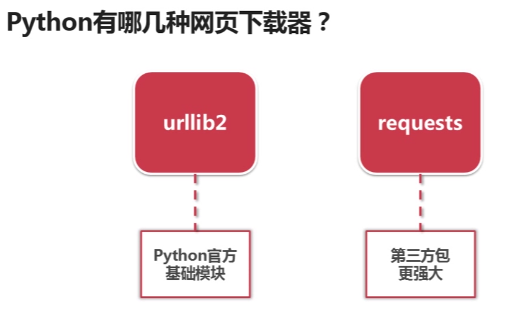
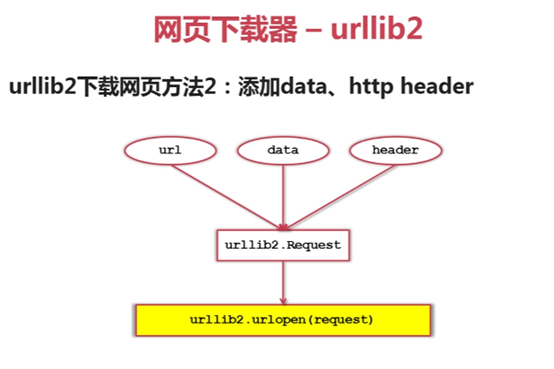
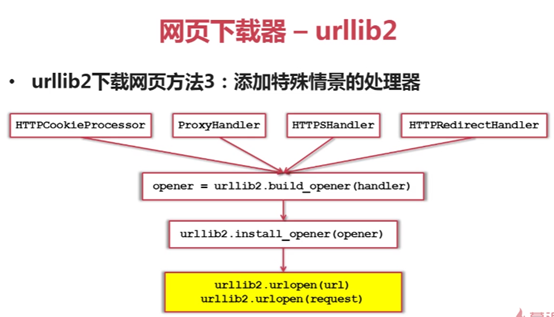
二、 网页下载器
用于下载网页
三种urllib实现网页下载,含cookie模拟登陆
三、 网页解析器
用于解析网页,获得有价值数据或者新的待爬取URL填充URL管理器
使用bs4的网页解析器
四、文件输出
文件输出
查看全文
相关阅读:
android逆向奇技淫巧五:x音fiddler抓包分析协议字段
windows:3环自行加载PE文件实现进程隐藏
android逆向奇技淫巧四:模拟器检测和反检测
android逆向奇技淫巧三:MT管理器替代android killer修改和重新编译smail代码/frida hook 更改so层代码
windows运算符和数据类型重载反CE查询搜索
android逆向奇技淫巧二:uiautomatorviewer&method profiling定位x音java层的关键代码和方法
android逆向奇技淫巧一:去掉开屏广告
xx课堂m3u8加密视频下载
Python接口自动化之logging日志
Python接口自动化之pymysql数据库操作
原文地址:https://www.cnblogs.com/cenzhongman/p/7344440.html
最新文章
AtCoder Beginner Contest 042 题解
信息学竞赛中计算结果对 $10^9+7$ 取余数的原因
windows环境下hbase1.4.13单机版安装
FlinkSQL写入hive
Flink开发本地模式开启WebUI
MySQL-CDC和Canal
Clickhouse数据导入到处命令使用
FlinkSQL-Upsert-kafka、MySQL-cdc、kafka-canal-json、kafka-changelog-json等连接器的使用
Linux shell中对日期时间的处理、日期时间加减
Flink快速构建项目quickstart
热门文章
linux sed命令就是这么简单
python解决url的请求参数中中文是乱码(%..%..)的问题
数据库篇:mysql表设计原则-三范式
网络篇:朋友面试之https认证加密过程
基础篇:java.security框架之签名、加密、摘要及证书
框架篇:ByteBuffer和netty.ByteBuf详解
Python爬虫学习笔记(四)
第4章 二次同余式与平方剩余 -《信息安全数学基础》
Python爬虫学习笔记(三)
随机数真的是随机的么? ---让菠菜、彩票等裤衩赔穿的漏洞
Copyright © 2011-2022 走看看