简介
Spark SQL是Spark用来处理结构化数据的一个模块,它提供了一个编程抽象叫做DataFrame并且作为分布式SQL查询引擎的作用。
为什么要学习Spark SQL?我们已经学习了Hive,它是将Hive SQL转换成MapReduce然后提交到集群上执行,大大简化了编写MapReduce的程序的复杂性,由于MapReduce这种计算模型执行效率比较慢。所以Spark SQL的应运而生,它是将Spark SQL转换成RDD,然后提交到集群执行,执行效率非常快!同时Spark SQL也支持从Hive中读取数据。
Spark SQL允许使用SQL或数学的DataFrame API在Spark程序中查询结构化数据。可用于Java,Scala,Python和R。
Spark SQL的特点:
1.容易整合(集成)
2.统一的数据访问方式
3.兼容Hive
4.标准的数据连接
工作架构
Spark可以分为1个driver(笔记本电脑或者集群网关机器上,用户编写的Spark程序)和若干个executor(在RDD分布的各个节点上)。
通过SparkContext(简称sc)连接Spark集群、创建RDD、累加器(accumlator)、广播变量(broadcast variables),简单可以认为SparkContext是Spark程序的根本。
Driver会把计算任务分成一系列小的task,然后送到executor执行。executor之间可以通信,在每个executor完成自己的task以后,所有的信息会被传回。
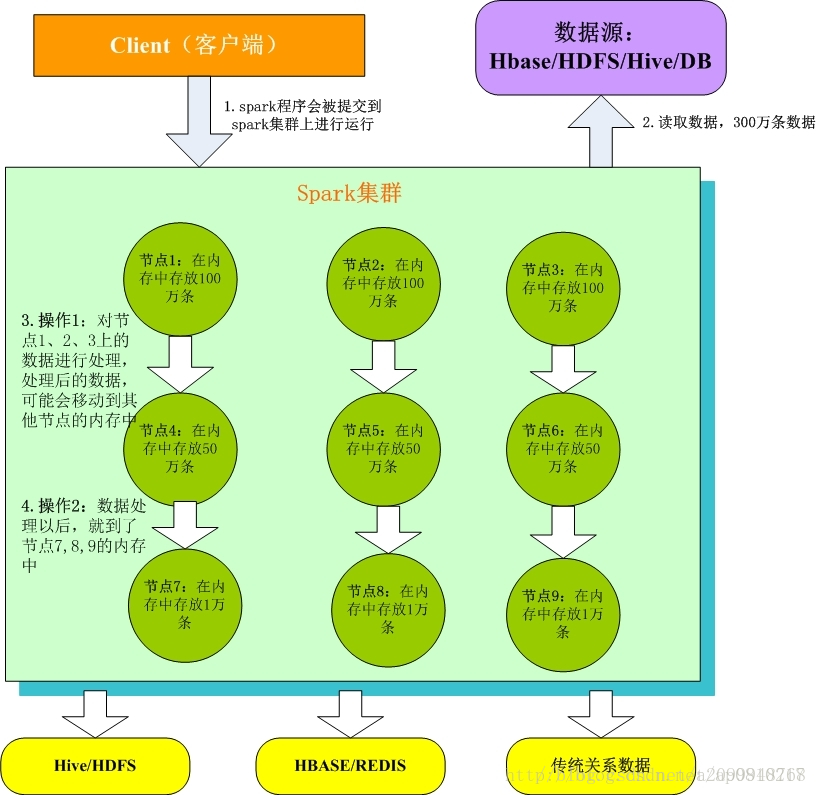
本图片来源网络
1. Client客户端:我们在本地编写了spark程序,打成jar包,或python脚本,通过spark submit命令提交到Spark集群;
2. 只有Spark程序在Spark集群上运行才能拿到Spark资源,来读取数据源的数据进入到内存里;
3. 客户端就在Spark分布式内存中并行迭代地处理数据,注意每个处理过程都是在内存中并行迭代完成;注意:每一批节点上的每一批数据,实际上就是一个RDD!!!一个RDD是分布式的,所以数据都散落在一批节点上了,每个节点都存储了RDD的部分partition。
4. Spark与MapReduce最大的不同在于,迭代式计算模型:MapReduce,分为两个阶段,map和reduce,两个阶段完了,就结束了,所以我们在一个job里能做的处理很有限; Spark,计算模型,可以分为n个阶段,因为它是内存迭代式的。我们在处理完一个阶段以后,可以继续往下处理很多个阶段,而不只是两个阶段。所以,Spark相较于MapReduce来说,计算模型可以提供更强大的功能。
spark的生态系统:
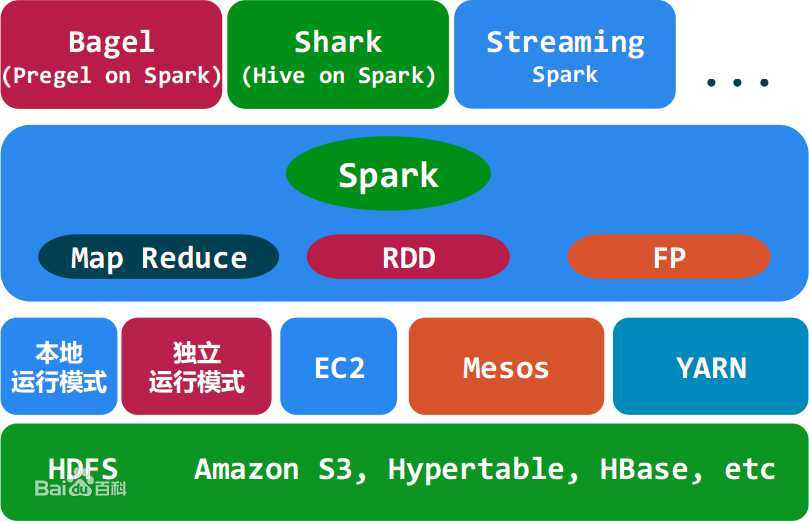
Mesos和yarn 作用一样,资源调度平台,用yarn的比较多
Tachyon:(1)内存当中hdfs(内存中的分布式存储系统,加快spark在内存中读取和处理速度)
(2)在不同应用程序之间实现数据共享
spark core:spark的核心,用于离线计算
语法
agg: 在整体DataFrame不分组聚合
withColumn: 添加额外列方法
join:两表拼接 sc.join(student,sc("sid")===student("sid"), "left").show ,Join有inner,leftouter,rightouter,fullouter,leftsemi,leftanti六种类型
函数返回值
// 1、使用return
def functionName ([参数列表]) : [return type] = {
function body
return [expr]
}
// 2、直接把返回值写在最后:
object Test {
def main(args: Array[String]) {
println( "Returned Value : " + addInt(5,7) );
}
def addInt( a:Int, b:Int ) : Int = {
var sum:Int = 0
sum = a + b
sum
}
}
results = spark.sql("SELECT * FROM people")
names = results.map(lambda p: p.name)
results.agg(count(ip).alias(ip_cnt))
results.withColumn("day_num", lit(1)).join(results, Seq("user"), "leftOuter").select("name", "day_num", "ip_cnt")
Join的例子
package com.sparkbyexamples.spark.dataframe.join
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.col
object JoinExample extends App {
val spark: SparkSession = SparkSession.builder()
.master("local[1]")
.appName("SparkByExamples.com")
.getOrCreate()
spark.sparkContext.setLogLevel("ERROR")
val emp = Seq((1,"Smith",-1,"2018","10","M",3000),
(2,"Rose",1,"2010","20","M",4000),
(3,"Williams",1,"2010","10","M",1000),
(4,"Jones",2,"2005","10","F",2000),
(5,"Brown",2,"2010","40","",-1),
(6,"Brown",2,"2010","50","",-1)
)
val empColumns = Seq("emp_id","name","superior_emp_id","year_joined","emp_dept_id","gender","salary")
import spark.sqlContext.implicits._
val empDF = emp.toDF(empColumns:_*)
empDF.show(false)
val dept = Seq(("Finance",10),
("Marketing",20),
("Sales",30),
("IT",40)
)
val deptColumns = Seq("dept_name","dept_id")
val deptDF = dept.toDF(deptColumns:_*)
deptDF.show(false)
println("Inner join")
empDF.join(deptDF,empDF("emp_dept_id") === deptDF("dept_id"),"inner")
.show(false)
println("Outer join")
empDF.join(deptDF,empDF("emp_dept_id") === deptDF("dept_id"),"outer")
.show(false)
println("full join")
empDF.join(deptDF,empDF("emp_dept_id") === deptDF("dept_id"),"full")
.show(false)
println("fullouter join")
empDF.join(deptDF,empDF("emp_dept_id") === deptDF("dept_id"),"fullouter")
.show(false)
println("right join")
empDF.join(deptDF,empDF("emp_dept_id") === deptDF("dept_id"),"right")
.show(false)
println("rightouter join")
empDF.join(deptDF,empDF("emp_dept_id") === deptDF("dept_id"),"rightouter")
.show(false)
println("left join")
empDF.join(deptDF,empDF("emp_dept_id") === deptDF("dept_id"),"left")
.show(false)
println("leftouter join")
empDF.join(deptDF,empDF("emp_dept_id") === deptDF("dept_id"),"leftouter")
.show(false)
println("leftanti join")
empDF.join(deptDF,empDF("emp_dept_id") === deptDF("dept_id"),"leftanti")
.show(false)
println("leftsemi join")
empDF.join(deptDF,empDF("emp_dept_id") === deptDF("dept_id"),"leftsemi")
.show(false)
println("cross join")
empDF.join(deptDF,empDF("emp_dept_id") === deptDF("dept_id"),"cross")
.show(false)
println("Using crossJoin()")
empDF.crossJoin(deptDF).show(false)
println("self join")
empDF.as("emp1").join(empDF.as("emp2"),
col("emp1.superior_emp_id") === col("emp2.emp_id"),"inner")
.select(col("emp1.emp_id"),col("emp1.name"),
col("emp2.emp_id").as("superior_emp_id"),
col("emp2.name").as("superior_emp_name"))
.show(false)
empDF.createOrReplaceTempView("EMP")
deptDF.createOrReplaceTempView("DEPT")
//SQL JOIN
val joinDF = spark.sql("select * from EMP e, DEPT d where e.emp_dept_id == d.dept_id")
joinDF.show(false)
val joinDF2 = spark.sql("select * from EMP e INNER JOIN DEPT d ON e.emp_dept_id == d.dept_id")
joinDF2.show(false)
}
资料
http://spark.apache.org/sql/
https://www.cnblogs.com/lq0310/p/9842078.html
https://sparkbyexamples.com/spark/spark-sql-dataframe-join/
https://www.jianshu.com/p/69bff3c7ec97
-----Spark SQL Join------
https://blog.51cto.com/wangyichao/2351971
https://www.cnblogs.com/duodushuduokanbao/p/9911256.html
https://support-it.huawei.com/docs/zh-cn/fusioninsight-all/developer_guide/zh-cn_topic_0171822912.html