数据来源
电信用户数据:https://www.datafountain.cn/dataSets/35/details#
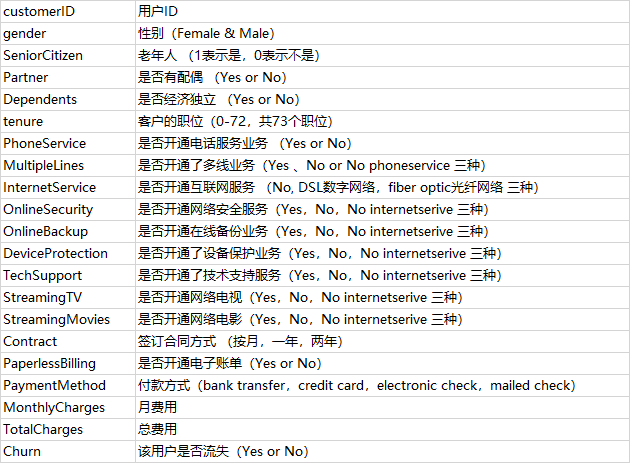
1.数据概述与可视化
# 模块 import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns import scipy.stats as st plt.rc("font",family="SimHei",size="12") #解决中文无法显示的问题 # 导入数据,且要赋值一份数据,用于数据可视化 train=pd.read_csv('F:\python\电信用户数据\WA_Fn-UseC_-Telco-Customer-Churn.csv')
train_data=train.copy()
1.1 数据概述
train_data.head() train_data.describe() train_data.info() train_data.shape #(7043, 21)
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 7043 entries, 0 to 7042
Data columns (total 21 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 customerID 7043 non-null object
1 gender 7043 non-null object
2 SeniorCitizen 7043 non-null int64
3 Partner 7043 non-null object
4 Dependents 7043 non-null object
5 tenure 7043 non-null int64
6 PhoneService 7043 non-null object
7 MultipleLines 7043 non-null object
8 InternetService 7043 non-null object
9 OnlineSecurity 7043 non-null object
10 OnlineBackup 7043 non-null object
11 DeviceProtection 7043 non-null object
12 TechSupport 7043 non-null object
13 StreamingTV 7043 non-null object
14 StreamingMovies 7043 non-null object
15 Contract 7043 non-null object
16 PaperlessBilling 7043 non-null object
17 PaymentMethod 7043 non-null object
18 MonthlyCharges 7043 non-null float64
19 TotalCharges 7043 non-null object
20 Churn 7043 non-null object
dtypes: float64(1), int64(2), object(18)
memory usage: 1.1+ MB
| SeniorCitizen | tenure | MonthlyCharges | |
|---|---|---|---|
| count | 7043.000000 | 7043.000000 | 7043.000000 |
| mean | 0.162147 | 32.371149 | 64.761692 |
| std | 0.368612 | 24.559481 | 30.090047 |
| min | 0.000000 | 0.000000 | 18.250000 |
| 25% | 0.000000 | 9.000000 | 35.500000 |
| 50% | 0.000000 | 29.000000 | 70.350000 |
| 75% | 0.000000 | 55.000000 | 89.850000 |
| max | 1.000000 | 72.000000 | 118.750000 |
由此可见很多数据都是对象型的,数值型很少,但是我们也要注意,居然没有缺失值,但是我们也要注意非空值的缺失值,类似于'-'这种的
1.2 数据可视化
首先区分一下数值型特征和类别型特征
#类别特征 object_col=dianxin.select_dtypes(include=[np.object]).columns ''' Index(['customerID', 'gender', 'Partner', 'Dependents', 'PhoneService', 'MultipleLines', 'InternetService', 'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies', 'Contract', 'PaperlessBilling', 'PaymentMethod', 'TotalCharges', 'Churn'], dtype='object') ''' #数值特征 num_col=dianxin.select_dtypes(include=[np.number]).columns ''' Index(['SeniorCitizen', 'tenure', 'MonthlyCharges'], dtype='object') '''
1.2.1单变量可视化(类别特征)
#单变量可视化 #首先看一些大体的分布如何,后面才好画图 for i in object_col: print(i,train_data[i].nunique())
customerID 7043 gender 2 Partner 2 Dependents 2 PhoneService 2 MultipleLines 3 InternetService 3 OnlineSecurity 3 OnlineBackup 3 DeviceProtection 3 TechSupport 3 StreamingTV 3 StreamingMovies 3 Contract 3 PaperlessBilling 2 PaymentMethod 4 TotalCharges 6531 Churn 2
#customerID,TotalCharges,可以不用画图 object_col=['gender', 'Partner', 'Dependents', 'PhoneService', 'MultipleLines', 'InternetService', 'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies', 'Contract', 'PaperlessBilling', 'PaymentMethod', 'Churn'] fig = plt.figure(figsize=[16,40]) for col,i in zip(object_col,range(1,17)): axes = fig.add_subplot(9,2,i) sns.countplot(train_data[col],ax=axes) plt.show()
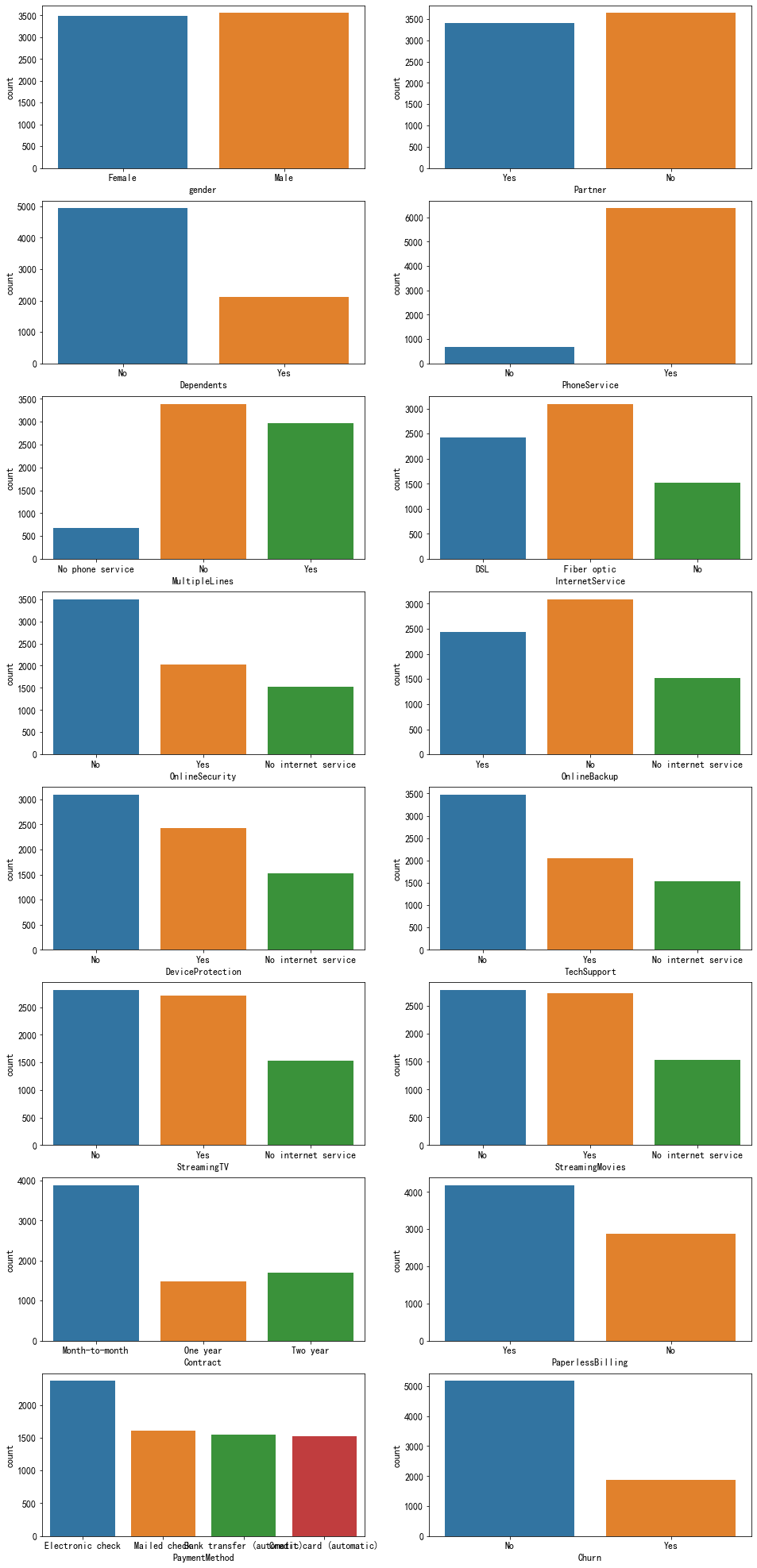
有上图可知,除了PhoneService分布特别不合理外,其余的分布还是比较均衡的
但是我们注意到下面,有三个值(类似于No phone service和No)其实是二个值,'MultipleLines' , 'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies'
for i in object_col: for j in train_data[i].value_counts(normalize = True).index: print(i,'=',j,":",round(train_data[i].value_counts(normalize = True)[j]*100,2),'%') print(' ')
gender = Male : 50.48 %
gender = Female : 49.52 %
Partner = No : 51.7 %
Partner = Yes : 48.3 %
Dependents = No : 70.04 %
Dependents = Yes : 29.96 %
PhoneService = Yes : 90.32 %
PhoneService = No : 9.68 %
MultipleLines = No : 48.13 %
MultipleLines = Yes : 42.18 %
MultipleLines = No phone service : 9.68 %
InternetService = Fiber optic : 43.96 %
InternetService = DSL : 34.37 %
InternetService = No : 21.67 %
OnlineSecurity = No : 49.67 %
OnlineSecurity = Yes : 28.67 %
OnlineSecurity = No internet service : 21.67 %
OnlineBackup = No : 43.84 %
OnlineBackup = Yes : 34.49 %
OnlineBackup = No internet service : 21.67 %
DeviceProtection = No : 43.94 %
DeviceProtection = Yes : 34.39 %
DeviceProtection = No internet service : 21.67 %
TechSupport = No : 49.31 %
TechSupport = Yes : 29.02 %
TechSupport = No internet service : 21.67 %
StreamingTV = No : 39.9 %
StreamingTV = Yes : 38.44 %
StreamingTV = No internet service : 21.67 %
StreamingMovies = No : 39.54 %
StreamingMovies = Yes : 38.79 %
StreamingMovies = No internet service : 21.67 %
Contract = Month-to-month : 55.02 %
Contract = Two year : 24.07 %
Contract = One year : 20.91 %
PaperlessBilling = Yes : 59.22 %
PaperlessBilling = No : 40.78 %
PaymentMethod = Electronic check : 33.58 %
PaymentMethod = Mailed check : 22.89 %
PaymentMethod = Bank transfer (automatic) : 21.92 %
PaymentMethod = Credit card (automatic) : 21.61 %
Churn = No : 73.46 %
Churn = Yes : 26.54 %
#但是我们注意到下面,有三个值(类似于No phone service和No)其实是二个值 two_no_col=['MultipleLines' , 'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies'] dict1={'No phone service':'No', 'No':'No', 'Yes':'Yes'} train_data['MultipleLines']=train_data['MultipleLines'].map(dict1) dict2={'No internet service':'No', 'No':'No', 'Yes':'Yes'} for i in ['OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies']: train_data[i]=train_data[i].map(dict2) fig = plt.figure(figsize=[16,20]) for col,i in zip(two_no_col,range(1,8)): axes = fig.add_subplot(4,2,i) sns.countplot(train_data[col],ax=axes) plt.show() for i in two_no_col: for j in train_data[i].value_counts(normalize = True).index: print(i,'=',j,":",round(train_data[i].value_counts(normalize = True)[j]*100,2),'%') print(' ')

MultipleLines = No : 57.82 %
MultipleLines = Yes : 42.18 %
OnlineSecurity = No : 71.33 %
OnlineSecurity = Yes : 28.67 %
OnlineBackup = No : 65.51 %
OnlineBackup = Yes : 34.49 %
DeviceProtection = No : 65.61 %
DeviceProtection = Yes : 34.39 %
TechSupport = No : 70.98 %
TechSupport = Yes : 29.02 %
StreamingTV = No : 61.56 %
StreamingTV = Yes : 38.44 %
StreamingMovies = No : 61.21 %
StreamingMovies = Yes : 38.79 %
1.2.2单变量和y值可视化(类别特征)
但是要注意,barplot需要y值是数值型的,现在我们先把y值转化成数值型的,Churn=1即是逾期
#类别变量和y值的可视化 #但是要注意,barplot需要y值是数值型的,现在我们先把y值转化成数值型的,Churn=0即是逾期 train_data.Churn[train_data['Churn']=='No']=0 train_data.Churn[train_data['Churn']=='Yes']=1 fig = plt.figure(figsize=[16,40]) for col,i in zip(object_col,range(1,17)): axes = fig.add_subplot(8,2,i) sns.barplot(train_data[col],train_data['Churn'],ax=axes) plt.show()
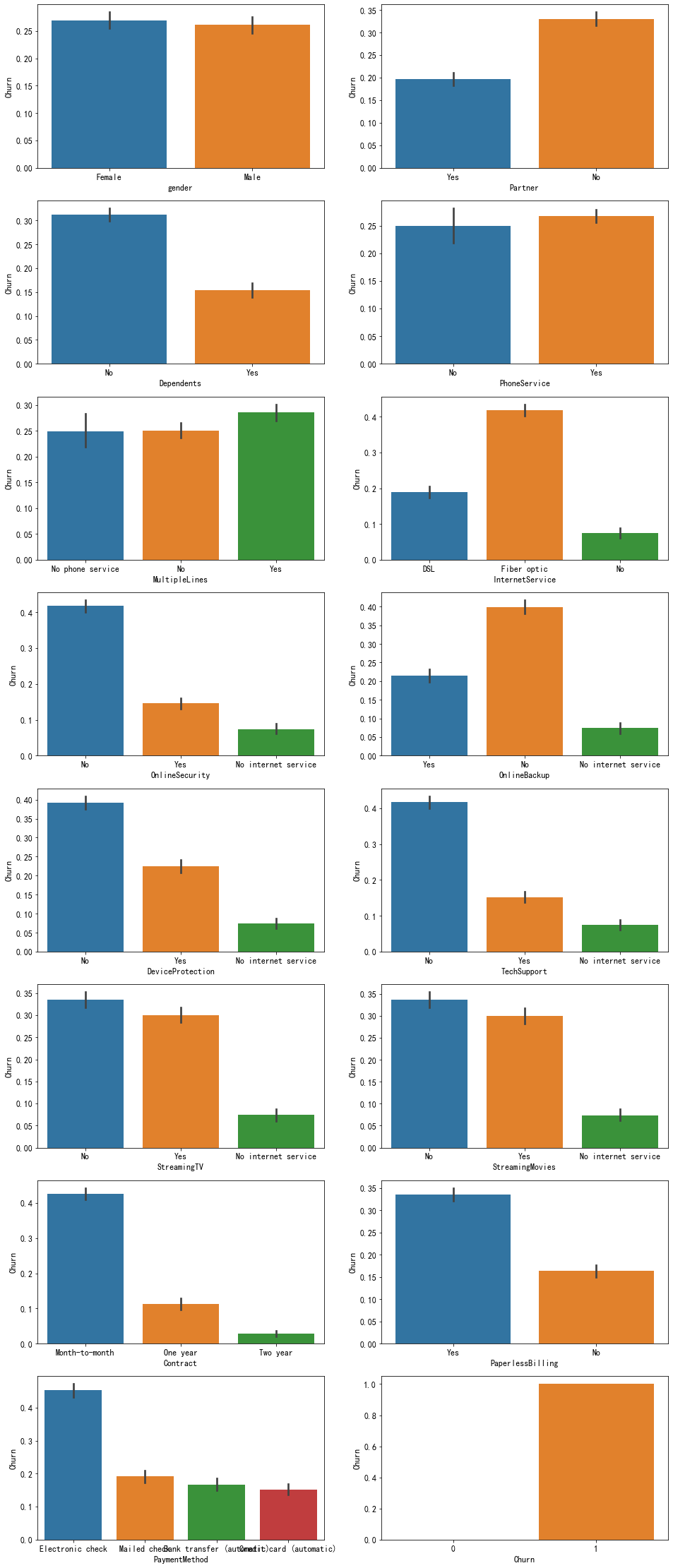
#不要y值 col=['gender', 'Partner', 'Dependents', 'PhoneService', 'MultipleLines', 'InternetService', 'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies', 'Contract', 'PaperlessBilling', 'PaymentMethod',] for i in col: for j in train_data[i].value_counts(normalize = True).index: print(i,'=',j,"的违约概率:",round(train_data.Churn[train_data[i]==j].value_counts(normalize = True)[1]*100,2),'%') print(' ')
gender = Male 的违约概率: 26.16 %
gender = Female 的违约概率: 26.92 %
Partner = No 的违约概率: 32.96 %
Partner = Yes 的违约概率: 19.66 %
Dependents = No 的违约概率: 31.28 %
Dependents = Yes 的违约概率: 15.45 %
PhoneService = Yes 的违约概率: 26.71 %
PhoneService = No 的违约概率: 24.93 %
MultipleLines = No 的违约概率: 25.04 %
MultipleLines = Yes 的违约概率: 28.61 %
MultipleLines = No phone service 的违约概率: 24.93 %
InternetService = Fiber optic 的违约概率: 41.89 %
InternetService = DSL 的违约概率: 18.96 %
InternetService = No 的违约概率: 7.4 %
OnlineSecurity = No 的违约概率: 41.77 %
OnlineSecurity = Yes 的违约概率: 14.61 %
OnlineSecurity = No internet service 的违约概率: 7.4 %
OnlineBackup = No 的违约概率: 39.93 %
OnlineBackup = Yes 的违约概率: 21.53 %
OnlineBackup = No internet service 的违约概率: 7.4 %
DeviceProtection = No 的违约概率: 39.13 %
DeviceProtection = Yes 的违约概率: 22.5 %
DeviceProtection = No internet service 的违约概率: 7.4 %
TechSupport = No 的违约概率: 41.64 %
TechSupport = Yes 的违约概率: 15.17 %
TechSupport = No internet service 的违约概率: 7.4 %
StreamingTV = No 的违约概率: 33.52 %
StreamingTV = Yes 的违约概率: 30.07 %
StreamingTV = No internet service 的违约概率: 7.4 %
StreamingMovies = No 的违约概率: 33.68 %
StreamingMovies = Yes 的违约概率: 29.94 %
StreamingMovies = No internet service 的违约概率: 7.4 %
Contract = Month-to-month 的违约概率: 42.71 %
Contract = Two year 的违约概率: 2.83 %
Contract = One year 的违约概率: 11.27 %
PaperlessBilling = Yes 的违约概率: 33.57 %
PaperlessBilling = No 的违约概率: 16.33 %
PaymentMethod = Electronic check 的违约概率: 45.29 %
PaymentMethod = Mailed check 的违约概率: 19.11 %
PaymentMethod = Bank transfer (automatic) 的违约概率: 16.71 %
PaymentMethod = Credit card (automatic) 的违约概率: 15.24 %
1.2.3单变量可视化(数值型特征)
连续型变量有['SeniorCitizen', 'tenure', 'MonthlyCharges'],再加上上面的 TotalCharges,仔细一卡,SeniorCitizen是否是老年人,这个字段也是离散型的,我们应该将他放到离散型里面,职业有74个值,而且还是加密的,我想把这个变量删除,如果是中文还好处理一点,但是是数值型就有点难处理了
先看下是否老年人这个字段
#先看老年人这个字段 fig, axes = plt.subplots(1,2,figsize=(12,6)) train_data['SeniorCitizen'].value_counts().plot.bar(ax=axes[0]) sns.barplot(train_data['SeniorCitizen'],train_data['Churn'],ax=axes[1]) print(train_data['SeniorCitizen'].value_counts()/len(train_data)) ''' 0 0.837853 1 0.162147 '''

看一下职业的,太离散了,删除吧
再看看两个费用,可知这两个费用相关性还是很高的,有65%多,而且总费用有缺失值'-',
#然后就是 #MonthlyCharges:月费用 #TotalCharges:总费用 #先把总费用转为数值型 train_data.TotalCharges.value_counts() #发现有11个' '值 #反正只有11个值,删除了没有影响 train_data['TotalCharges'].replace(' ',np.nan,inplace=True) train_data=train_data.dropna() train_data.TotalCharges=train_data.TotalCharges.astype(np.float64) train_data.TotalCharges.dtype #dtype('float64') #看一下两个费用相关性如何 train_data[['MonthlyCharges','TotalCharges']].corr() ''' MonthlyCharges TotalCharges MonthlyCharges 1.000000 0.651065 TotalCharges 0.651065 1.000000 '''
看看违约用户的费用的箱型图有啥区别
#看看违约用户的费用的箱型图有啥区别 plt.boxplot((train_data.MonthlyCharges[train_data.Churn==0],train_data.MonthlyCharges[train_data.Churn==1]),labels=('Churn==0','Churn==1')) plt.title('月费用') plt.show() plt.boxplot((train_data.TotalCharges[train_data.Churn==0],train_data.TotalCharges[train_data.Churn==1]),labels=('Churn==0','Churn==1')) plt.title('总费用') plt.show()

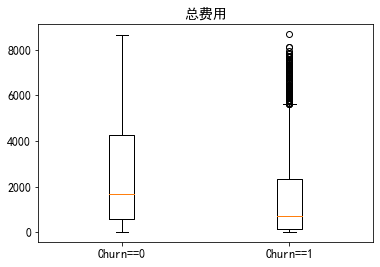
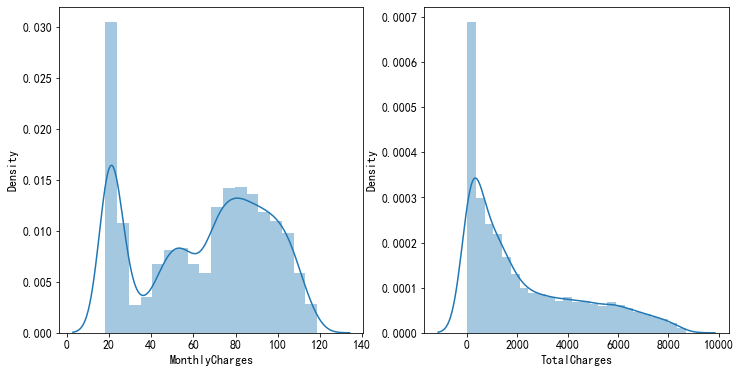
可以看得出流水用户的月费用会高一点,但是总费用却低一点,很有可能是月租太贵了,组那么几个月就不用的,我们还可以构建一个使用月长,用总费用除以月费用即是
#费用的分布 fig, axes = plt.subplots(1,2,figsize=(12,6)) sns.distplot( train_data.MonthlyCharges, ax=axes[0]) sns.distplot( train_data.TotalCharges, ax=axes[1])
2. 特征工程
特征工程用的是原数据
train=pd.read_csv('F:\python\电信用户数据\WA_Fn-UseC_-Telco-Customer-Churn.csv')
2.1 缺失值处理
从上面的数据可视化,我们知道总费用有11个‘-’类型的缺失值,我们先使用空值填充,然后再删除
train['TotalCharges'].replace(' ',np.nan,inplace=True) train=train.dropna()
2.2 处理No internet service和No,统一改为NO
处理同一个意思,却有两种表达方式的特征
#处理同一个意思,却有两种表达方式的特征 two_no_col=['MultipleLines' , 'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies'] dict1={'No phone service':'No', 'No':'No', 'Yes':'Yes'} train['MultipleLines']=train['MultipleLines'].map(dict1) dict2={'No internet service':'No', 'No':'No', 'Yes':'Yes'} for i in ['OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies']: train[i]=train[i].map(dict2)
2.3 处理费用
处理费用,首先我们先构造一个使用月长的字段,后面再做两个版本,一个是数值型特征有进行数据分箱,一个是没有分箱
#处理费用,首先我们先构造一个使用月长的字段,后面再做两个版本,一个是数值型特征有进行数据分箱,一个是没有分箱 #先将总费用的类型改为数值型 train.TotalCharges=train.TotalCharges.astype(np.float64) train.TotalCharges.dtype #dtype('float64') #构造使用月长 train['use_month']=round(train.TotalCharges/train_data.MonthlyCharges,0) #特征分箱,这次的版本先不用分箱
2.4 类别特征做One-hot
首先要删除customerID和tenure :客户的职位,再将需要转化的特征改为str类型,然后再对独热编码,最后将原来的特征删除
#类别特征做One-hot #首先要删除customerID customerID=train.pop('customerID')
train.pop('tenure') train.columns ''' Index(['gender', 'SeniorCitizen', 'Partner', 'Dependents', 'tenure', 'PhoneService', 'MultipleLines', 'InternetService', 'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies', 'Contract', 'PaperlessBilling', 'PaymentMethod', 'MonthlyCharges', 'TotalCharges', 'Churn', 'use_month'], dtype='object') ''' onehot_col=['gender', 'SeniorCitizen', 'Partner', 'Dependents', 'tenure', 'PhoneService', 'MultipleLines', 'InternetService', 'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies', 'Contract', 'PaperlessBilling', 'PaymentMethod'] train[onehot_col] = train[onehot_col].astype(str) feature_dummies = pd.get_dummies(train[onehot_col]) # feature_dummies.head() train.drop(onehot_col, inplace=True, axis=1) train = pd.concat((train, feature_dummies), axis=1) train.head()
还需要将特征y变成0,1
#首先要将特征值换成0,1 train.Churn[train['Churn']=='No']=0 train.Churn[train['Churn']=='Yes']=1 train.Churn=train.Churn.astype(np.int64)
2.5 画特征相关性的地热图
plt.figure(figsize=(20,16)) sns.heatmap(train.corr(),xticklabels=train.corr().columns, yticklabels=train.corr().columns, linewidths=0.2, cmap="YlGnBu",annot=True)
3. 模型训练
3.1 逻辑回归
首先导入模快和分好x和y
#模型训练 #首先导入模快和分好x和y from sklearn.linear_model import LogisticRegression from sklearn.metrics import confusion_matrix, roc_curve,roc_auc_score,classification_report ,auc from sklearn.model_selection import train_test_split train_y=train['Churn'].values train_x=train x_train,x_test,y_train,y_test=train_test_split(train_x,train_y,test_size=0.3,random_state=0) #逻辑回归 clf = LogisticRegression() clf.fit(x_train.values,y_train) #训练集测试auc p=clf.predict(x_train) fpr, tpr, p_threshold = metrics.roc_curve(y_train, p, drop_intermediate=False, pos_label=1) auc(fpr, tpr) #1 #用测试集进行检验 p=clf.predict(x_test) fpr, tpr, p_threshold = metrics.roc_curve(y_test, p, drop_intermediate=False, pos_label=1) auc(fpr, tpr) #1
是特征处理的太好了吗,为什么结果会是1 ,太奇怪了
3.2 Random Forest
from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import cross_val_score import sklearn %matplotlib inline depth_ = [1, 2, 3, 4, 5, 6, 7, 8] scores = [] for depth in depth_: clf1 = RandomForestClassifier(n_estimators=100, max_depth=depth, random_state=0) test_score = cross_val_score(clf1, x_train.values,y_train, cv=10, scoring="precision") scores.append(np.mean(test_score)) plt.plot(depth_, scores)

结果也是很不错,看来是特征工程太完美了
3.3 XGBClassifier
from xgboost import XGBClassifier params = [1, 2, 3, 4, 5, 6] test_scores = [] for param in params: clf = XGBClassifier(max_depth=param) test_score = cross_val_score(clf, x_train.values,y_train, cv=10, scoring="precision") test_scores.append(np.mean(test_score)) plt.plot(params, test_scores)

天哪,我自闭了,还是1。
附上全部代码


# 模块 import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns import scipy.stats as st plt.rc("font",family="SimHei",size="12") #解决中文无法显示的问题 # 导入数据 dianxin=pd.read_csv('F:\python\电信用户数据\WA_Fn-UseC_-Telco-Customer-Churn.csv') train_data.head() train_data.describe() train_data.info() train_data.shape #(7043, 21) #类别特征 object_col=dianxin.select_dtypes(include=[np.object]).columns ''' Index(['customerID', 'gender', 'Partner', 'Dependents', 'PhoneService', 'MultipleLines', 'InternetService', 'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies', 'Contract', 'PaperlessBilling', 'PaymentMethod', 'TotalCharges', 'Churn'], dtype='object') ''' #数值特征 num_col=dianxin.select_dtypes(include=[np.number]).columns ''' Index(['SeniorCitizen', 'tenure', 'MonthlyCharges'], dtype='object') ''' #单变量可视化 #首先看一些大体的分布如何,后面才好画图 for i in object_col: print(i,train_data[i].nunique()) #customerID,TotalCharges,可以不用画图 object_col=['gender', 'Partner', 'Dependents', 'PhoneService', 'MultipleLines', 'InternetService', 'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies', 'Contract', 'PaperlessBilling', 'PaymentMethod', 'Churn'] fig = plt.figure(figsize=[16,40]) for col,i in zip(object_col,range(1,17)): axes = fig.add_subplot(9,2,i) sns.countplot(train_data[col],ax=axes) plt.show() for i in object_col: for j in train_data[i].value_counts(normalize = True).index: print(i,'=',j,":",round(train_data[i].value_counts(normalize = True)[j]*100,2),'%') print(' ') ''' 1.样本是否均匀 gender:性别。(Female & Male) 比较平均 Partner :是否有配偶 (Yes or No)比较平均 Dependents :是否经济独立 (Yes or No)不独立的占比约60% PhoneService :是否开通电话服务业务 (Yes or No) 很不均衡,开通的约占80%多 MultipleLines:是否开通了多线业务(Yes 、No or No phoneservice 三种) InternetService:是否开通互联网服务 (No, DSL数字网络,fiber optic光纤网络 三种) OnlineSecurity:是否开通网络安全服务(Yes,No,No internetserive 三种) OnlineBackup:是否开通在线备份业务(Yes,No,No internetserive 三种) DeviceProtection:是否开通了设备保护业务(Yes,No,No internetserive 三种) TechSupport:是否开通了技术支持服务(Yes,No,No internetserive 三种) StreamingTV:是否开通网络电视(Yes,No,No internetserive 三种) StreamingMovies:是否开通网络电影(Yes,No,No internetserive 三种) Contract:签订合同方式 (按月,一年,两年) PaperlessBilling:是否开通电子账单(Yes or No) PaymentMethod:付款方式(bank transfer,credit card,electronic check,mailed check) Churn:该用户是否流失(Yes or No) ''' #但是我们注意到下面,有三个值(类似于No phone service和No)其实是二个值 two_no_col=['MultipleLines' , 'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies'] dict1={'No phone service':'No', 'No':'No', 'Yes':'Yes'} train_data['MultipleLines']=train_data['MultipleLines'].map(dict1) dict2={'No internet service':'No', 'No':'No', 'Yes':'Yes'} for i in ['OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies']: train_data[i]=train_data[i].map(dict2) fig = plt.figure(figsize=[16,20]) for col,i in zip(two_no_col,range(1,8)): axes = fig.add_subplot(4,2,i) sns.countplot(train_data[col],ax=axes) plt.show() for i in two_no_col: for j in train_data[i].value_counts(normalize = True).index: print(i,'=',j,":",round(train_data[i].value_counts(normalize = True)[j]*100,2),'%') print(' ') #类别变量和y值的可视化 #但是要注意,barplot需要y值是数值型的,现在我们先把y值转化成数值型的,Churn=1即是逾期 train_data.Churn[train_data['Churn']=='No']=0 train_data.Churn[train_data['Churn']=='Yes']=1 fig = plt.figure(figsize=[16,40]) for col,i in zip(object_col,range(1,17)): axes = fig.add_subplot(8,2,i) sns.barplot(train_data[col],train_data['Churn'],ax=axes) plt.show() #不要y值 col=['gender', 'Partner', 'Dependents', 'PhoneService', 'MultipleLines', 'InternetService', 'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies', 'Contract', 'PaperlessBilling', 'PaymentMethod',] for i in col: for j in train_data[i].value_counts(normalize = True).index: print(i,'=',j,"的违约概率:",round(train_data.Churn[train_data[i]==j].value_counts(normalize = True)[1]*100,2),'%') print(' ') #单变量可视化(连续型) #['SeniorCitizen', 'tenure', 'MonthlyCharges'] #再加上上面的 TotalCharges #仔细一卡,SeniorCitizen是否是老年人,这个字段也是离散型的,我们应该将他放到离散型里面, #职业有74个值,而且还是加密的,我想把这个变量删除,如果是中文还好处理一点,但是是数值型就有点难处理了 num_col=['SeniorCitizen', 'tenure', 'MonthlyCharges','TotalCharges'] train_data[num_col] #先看老年人这个字段 fig, axes = plt.subplots(1,2,figsize=(12,6)) train_data['SeniorCitizen'].value_counts().plot.bar(ax=axes[0]) sns.barplot(train_data['SeniorCitizen'],train_data['Churn'],ax=axes[1]) print(train_data['SeniorCitizen'].value_counts()/len(train_data)) #看一下职业的,太离散了,删除吧 #然后就是 #MonthlyCharges:月费用 #TotalCharges:总费用 #先把总费用转为数值型 train_data.TotalCharges.value_counts() #发现有11个' '值 #反正只有11个值,删除了没有影响 train_data['TotalCharges'].replace(' ',np.nan,inplace=True) train_data=train_data.dropna() train_data.TotalCharges=train_data.TotalCharges.astype(np.float64) train_data.TotalCharges.dtype #dtype('float64') #看一下两个费用相关性如何 train_data[['MonthlyCharges','TotalCharges']].corr() ''' MonthlyCharges TotalCharges MonthlyCharges 1.000000 0.651065 TotalCharges 0.651065 1.000000 ''' #看看违约用户的费用的箱型图有啥区别 plt.boxplot((train_data.MonthlyCharges[train_data.Churn==0],train_data.MonthlyCharges[train_data.Churn==1]),labels=('Churn==0','Churn==1')) plt.title('月费用') plt.show() plt.boxplot((train_data.TotalCharges[train_data.Churn==0],train_data.TotalCharges[train_data.Churn==1]),labels=('Churn==0','Churn==1')) plt.title('总费用') plt.show() #费用的分布 fig, axes = plt.subplots(1,2,figsize=(12,6)) sns.distplot( train_data.MonthlyCharges, ax=axes[0]) sns.distplot( train_data.TotalCharges, ax=axes[1]) #特征工程 train=pd.read_csv('F:\python\电信用户数据\WA_Fn-UseC_-Telco-Customer-Churn.csv') #1.缺失值处理,我们知道总费用有11个‘-’类型的缺失值,我们先使用空值填充,然后再删除 train['TotalCharges'].replace(' ',np.nan,inplace=True) train=train.dropna() #处理同一个意思,却有两种表达方式的特征 two_no_col=['MultipleLines' , 'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies'] dict1={'No phone service':'No', 'No':'No', 'Yes':'Yes'} train['MultipleLines']=train['MultipleLines'].map(dict1) dict2={'No internet service':'No', 'No':'No', 'Yes':'Yes'} for i in ['OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies']: train[i]=train[i].map(dict2) #处理费用,首先我们先构造一个使用月长的字段,后面再做两个版本,一个是数值型特征有进行数据分箱,一个是没有分箱 #先将总费用的类型改为数值型 train.TotalCharges=train.TotalCharges.astype(np.float64) train.TotalCharges.dtype #dtype('float64') #构造使用月长 train['use_month']=round(train.TotalCharges/train_data.MonthlyCharges,0) #特征分箱,这次的版本先不用分箱 #类别特征做One-hot #首先要删除customerID customerID=train.pop('customerID') train.pop('tenure') train.columns ''' Index(['gender', 'SeniorCitizen', 'Partner', 'Dependents', 'tenure', 'PhoneService', 'MultipleLines', 'InternetService', 'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies', 'Contract', 'PaperlessBilling', 'PaymentMethod', 'MonthlyCharges', 'TotalCharges', 'Churn', 'use_month'], dtype='object') ''' onehot_col=['gender', 'SeniorCitizen', 'Partner', 'Dependents', 'PhoneService', 'MultipleLines', 'InternetService', 'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies', 'Contract', 'PaperlessBilling', 'PaymentMethod'] train[onehot_col] = train[onehot_col].astype(str) feature_dummies = pd.get_dummies(train[onehot_col]) # feature_dummies.head() train.drop(onehot_col, inplace=True, axis=1) train = pd.concat((train, feature_dummies), axis=1) train.head() #首先要将特征值换成0,1 train.Churn[train['Churn']=='No']=0 train.Churn[train['Churn']=='Yes']=1 train.Churn=train.Churn.astype(np.int64) plt.figure(figsize=(20,16)) sns.heatmap(train.corr(),xticklabels=train.corr().columns, yticklabels=train.corr().columns, linewidths=0.2, cmap="YlGnBu",annot=True) #模型训练 #首先导入模快和分好x和y from sklearn.linear_model import LogisticRegression from sklearn.metrics import confusion_matrix, roc_curve,roc_auc_score,classification_report ,auc from sklearn.model_selection import train_test_split train_y=train['Churn'].values train_x=train x_train,x_test,y_train,y_test=train_test_split(train_x,train_y,test_size=0.3,random_state=0) #逻辑回归 clf = LogisticRegression() clf.fit(x_train.values,y_train) #训练集测试auc p=clf.predict(x_train) fpr, tpr, p_threshold = metrics.roc_curve(y_train, p, drop_intermediate=False, pos_label=1) auc(fpr, tpr) #1 #用测试集进行检验 p=clf.predict(x_test) fpr, tpr, p_threshold = metrics.roc_curve(y_test, p, drop_intermediate=False, pos_label=1) auc(fpr, tpr) #1 ######################################################################### D