3.1 scrapy框架 -- 安装与基本使用
1.scrapy的安装
1 # 1.在安装scrapy前需要安装好相应的依赖库, 再安装scrapy, 具体安装步骤如下:
2 (1).安装lxml库: pip install lxml
3 (2).安装wheel: pip install wheel
4 (3).安装twisted: pip install twisted文件路径
5 (twisted需下载后本地安装,下载地址:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted)
6 (版本选择如下图,版本后面有解释,请根据自己实际选择)
7 (4).安装pywin32: pip install pywin32
8 (注意:以上安装步骤一定要确保每一步安装都成功,没有报错信息,如有报错自行百度解决)
9 (5).安装scrapy: pip install scrapy
10 (注意:以上安装步骤一定要确保每一步安装都成功,没有报错信息,如有报错自行百度解决)
11 (6).成功验证:在cmd命令行输入scrapy,显示Scrapy1.6.0-no active project,证明安装成功

2.使用命令行创建, 启动项目
1 1.手动创建一个目录test
2 2.在test文件夹下创建爬虫项目为spiderpro: scrapy startproject spiderpro
3 3.进入项目文件夹: cd spiderpro
4 4.创建爬虫文件: scrapy genspider 爬虫名 url地址
3.项目目录结构
1 spiderpro
2 spiderpro # 项目目录
3 __init__
4 spiders:爬虫文件目录
5 __init__
6 tests.py:爬虫文件
7 items.py:定义爬取数据持久化的数据结构
8 middlewares.py:定义中间件
9 pipelines.py:管道,持久化存储相关
10 settings.py:配置文件
11 venv:虚拟环境目录
12 scrapy.cfg: scrapy项目配置文件
说明:
(1).spiders:其内包含一个个Spider的实现, 每个Spider是一个单独的文件
(2).items.py:它定义了Item数据结构, 爬取到的数据存储为哪些字段
(3).pipelines.py:它定义Item Pipeline的实现
(4).settings.py:项目的全局配置
(5).middlewares.py:定义中间件, 包括爬虫中间件和下载中间件
(6).scrapy.cfg:它是scrapy项目的配置文件, 其内定义了项目的配置路径, 部署相关的信息等
4.scrapy架构与任务处理流程
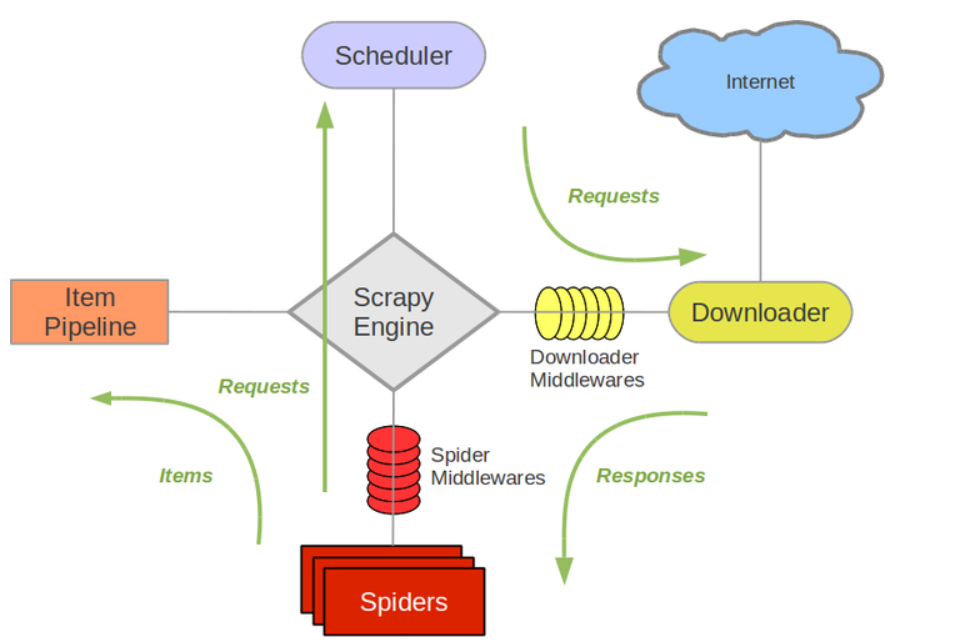
(1).架构:
Scrapy Engine: 这是引擎,负责Spiders、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等等!(像不像人的身体?)
Scheduler(调度器): 它负责接受引擎发送过来的requests请求,并按照一定的方式进行整理排列,入队、并等待Scrapy Engine(引擎)来请求时,交给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spiders来处理,
Spiders:它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
Item Pipeline:它负责处理Spiders中获取到的Item,并进行处理,比如去重,持久化存储(存数据库,写入文件,总之就是保存数据用的)
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spiders中间‘通信‘的功能组件(比如进入Spiders的Responses;和从Spiders出去的Requests)
(2).工作流:
1.spider将请求发送给引擎, 引擎将request发送给调度器进行请求调度
2.调度器把接下来要请求的request发送给引擎, 引擎传递给下载器, 中间会途径下载中间件
3.下载携带request访问服务器, 并将爬取内容response返回给引擎, 引擎将response返回给spider
4.spider将response传递给自己的parse进行数据解析处理及构建item一系列的工作, 最后将item返回给引擎, 引擎传递个pipeline
5.pipe获取到item后进行数据持久化
6.以上过程不断循环直至爬虫程序终止
5.简单使用示例:
1 #需求:爬取糗事百科热门板块,每一条的标题,好笑,评论条数及作者信息,解析爬取的信息数据,定制item数据存储结构,最终将数据存储于MongoDB数据库中.
2
3 #思路与步骤:
4 1.创建项目,起始url为:https://www.qiushibaike.com/
5 2.创建item类,定义要持久化存储的字段
6 3.定义parse解析类,并将字段信息存储在item中
7 4.定义pipeline类,进行数据持久化
8 5.在setting配置文件中配置要配置的项
创建项目
1 # 创建项目, 起始url为:https://www.qiushibaike.com/
2
3 # 1.创建项目命令:
4 scrapy startproject qsbk # 创建项目
5 cd qsbk # 切换到项目目录
6 scrapy genspider qsbk_hot www.qiushibaike.com # 创建爬虫文件, qsbk_hot为爬虫名, 后网址为起始url
创建item类, 用于存储目标数据
1 # 创建item类, 用于存储目标数据
2 import scrapy
3 classQsbkItem(scrapy.Item):
4 title = scrapy.Field()# 标题
5 lau = scrapy.Field()# 好笑数
6 comment = scrapy.Field()# 评论数
7 auth = scrapy.Field()# 作者
spider文件中定义解析数据的方法
1 # spider文件中定义解析数据的方法
2 classQsbkHotSpider(scrapy.Spider):
3 name ='qsbk_hot'
4 # allowed_domains = ['www.qiushibaike.com'] # 无用, 可注释掉
5 start_urls =['http://www.qiushibaike.com/']
6
7 # 思路:一条热点数据在前端中对应一个li标签, 将一页中的所有li标签取出, 再进一步操作
8 def parse(self, response):
9
10 li_list = response.selector.xpath('//div[@class="recommend-article"]/ul/li')
11
12 # 循环li标签组成的列表, 先实例化item, 再取需要的字段, 并该item对象的相应属性赋值
13 for li in li_list:
14
15 # 实例化item对象
16 item =QsbkItem()
17
18 # 解析获取title(标题), lau(好笑数), comment(评论数), auth(作者)等信息
19 title = li.xpath('./div[@class="recmd-right"]/a/text()').extract_first()
20 lau = li.xpath('./div[@class="recmd-right"]/div[@class="recmd-detail clearfix"]/div/span[1]/text()').extract_first()
21 comment = li.xpath('./div[@class="recmd-right"]/div[@class="recmd-detail clearfix"]/div/span[4]/text()').extract_first()
22 auth = li.xpath('./div[@class="recmd-right"]/div[@class="recmd-detail clearfix"]/a/span/text()').extract_first()
23
24 # 因为部分热点数据还没有评论和好笑数, 所以对齐做一下处理
25 if not lau:
26 lau =None
27 if not comment:
28 comment =None
29
30 # 将字段的值存储在item的属性中
31 item["title"]= title
32 item["lau"]= lau
33 item["comment"]= comment
34 item["auth"]= auth
35
36 # 返回item, 框架会自动将item传送至pipeline中的指定类
37 yield item
在pipeline中定义管道类进行数据的存储
# 在pipeline中定义管道类进行数据的存储
import pymongo
from qsbk.settings import MONGO_NAME # MONGO_NAME在配置文件中定义的, 其值为"qsbk"
from qsbk.settings import MONGO_URL_PORT # MONGO_URL_PORT在配置文件中定义, 其值为"MongoDB地址:端口"
classQsbkPipeline(object):
8
9 # 连接MongoDB数据库
10 mongo_client = pymongo.MongoClient(MONGO_URL_PORT)
11 mongo_db = mongo_client[MONGO_NAME]
12
13 def process_item(self, item, spider):
14 name =self.__class__.__name__
15
16 # 向数据库中出入数据
17 self.mongo_db[name].insert(dict(item))
18
19 # 此处return item是为了下一个管道类能够接收到item进行存储
20 return item
21
22 def close_spider(self):
23 # 关闭数据库连接
24 self.mongo_client.close()
此示例中配置文件中的配置的项, 注意是不是全部的配置, 是针对该项目增加或修改的配置项
1 # 此示例中配置文件中的配置的项, 注意是不是全部的配置, 是针对该项目增加或修改的配置项
2
3 # MongoDB数据库配置
4 MONGO_URL_PORT ='127.0.0.1:27017'# 设置数据库的连接地址和端口号
5 MONGO_NAME ='qsbk'# 数据库要存储在哪个库中
6
7 # 忽略robots协议
8 ROBOTSTXT_OBEY =False
9
10 # 管道类的注册配置
11 ITEM_PIPELINES ={
12 'qsbk.pipelines.QsbkPipeline':300,
13 }
启动项目
# 假设现在有一个名叫 one 的爬虫,启动指令如下
scrapy crawl one # 执行名为one爬虫文件,显示日志 【重点】
scrapy crawl one --nolog # 执行名为one爬虫文件,不显示日志【重点】
上面的例子就是scrapy的简单应用, 涉及到数据的请求, 数据的解析, 数据的持久化存储等操作