1.K-means算法介绍
(1)
(2)
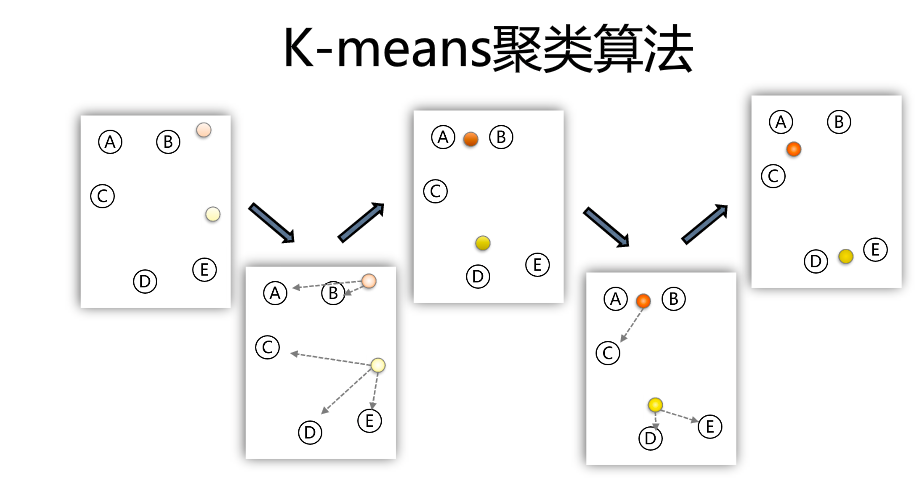
(3)例子应用


2过程









3.代码(里面我自己做了自我化的通俗注解)
import sklearn
import numpy as np
from sklearn.cluster import KMeans
#文件载入
def loadData(filepath):
fr=open(filepath,'r+',buffering=1,encoding='gbk')
lines=fr.readlines()
retDate=[]
retCityname=[]
for line in lines:
items=line.strip().split(',')#默认去空格换行符,以“,”切片,返回参数列表
# print(items)
# print(line)
retCityname.append(items[0])
retDate.append([float(items[i]) for i in range(1,len(items))])
return retDate,retCityname
if __name__=='__main__':
Date,Cityname=loadData('/Users/helong/PycharmProjects/untitled1/study/machine_learning/聚类/31省市居民家庭消费水平-city.txt')
km=KMeans(n_clusters=5)#n_clusters 聚类中心的个数
label=km.fit_predict(Date)#导入数据后,label表示计算后各数据所属的标签,fit_predict表示计算簇中心以及为簇分配序号
print(label)
print(km.cluster_centers_)#每个簇的每种消费的mean值
expenses=np.sum(km.cluster_centers_,axis=1)#每个簇的平均总消费()
print("+++++++++++对比线+++++++++++")
print(expenses)
Citycluster=[[],[],[],[],[]]
for i in range(len(Cityname)):
Citycluster[label[i]].append(Cityname[i]) #把城市和标签一一对应
for j in range(len(Citycluster)):
print('Expenses:{}'.format(expenses[j]))
print(Citycluster[j])
输出结果(5个簇):
[2 2 1 1 1 1 1 1 4 3 2 3 0 1 1 1 3 3 4 3 3 3 3 1 3 0 1 1 1 1 1]
[[2678.035 633.905 269.28 184.94 392.22
416.355 402.36 310.81 ]
[1525.81533333 478.672 322.88266667 232.4 236.41866667
457.53133333 344.81866667 190.21933333]
[2682.70666667 594.52666667 712.15666667 417.3 422.24
891.22 541.67333333 362.02666667]
[2037.95222222 447.31444444 366.59444444 196.02111111 300.58333333
597.70444444 437.36777778 232.28555556]
[3383.74 451.985 728.965 351.6 669.44
954.02 901.575 441.42 ]]
+++++++++++对比线+++++++++++
[5287.905 3788.758 6623.85 4615.82333333 7882.745 ]
Expenses:5287.905
['福建', '西藏']
Expenses:3788.758
['河北', '山西', '内蒙古', '辽宁', '吉林', '黑龙江', '江西', '山东', '河南', '贵州', '陕西', '甘肃', '青海', '宁夏', '新疆']
Expenses:6623.849999999999
['北京', '天津', '浙江']
Expenses:4615.823333333334
['江苏', '安徽', '湖南', '湖北', '广西', '海南', '重庆', '四川', '云南']
Expenses:7882.745
['上海', '广东']
注意:(1)这里的label输出顺序还是和愿数据城市的排序一样,便于城市对应相应的簇(归类),
(2)label的编号只是单纯编号,没有经过排序(没有严格大小关系),但是每个簇的中心值(mean)数据是严格按照label的[0,1,2,3,。。。]
的排序是顺序输出的
2020-06-08