DropNet
2020-ICML-DropNet Reducing Neural Network Complexity via Iterative Pruning
来源:ChenBong 博客园
- Institute:NUS
- Author:John Tan Chong Min,Mehul Motani
- GitHub:https://github.com/tanchongmin/DropNet
- Citation:/
Introduction
提出了一种基于卷积核重要性指标:卷积核对所有训练集样本的平均激活值。
提出了根据该激活值的一种迭代剪枝算法。
Contribution
- 第一个提出根据所有训练集样本的平均激活值来进行剪枝的方法,即利用了权重值,也利用了输入数据。
- 对全连接MLP和卷积网络CNN都适用
- 不需要特殊的权重初始化,随机初始化也表现良好
Method
重要性指标 metric
**全连接网络节点 (a_i) 的重要性指标 ** (Eleft(a_{i} ight)=frac{1}{t} sum_{j=1}^{t}left|Vleft(a_{i} mid x_{j} ight) ight|)
(Vleft(a_{i} mid x_{j} ight)) 表示节点 (a_i) 对样本 (x_j) 的激活值(ReLU之后的值),(t) 为训练集样本个数
CNN 卷积核 (f_i) 的重要性指标: (Eleft(f_{i} ight)=frac{1}{r} sum_{j=1}^{r}left|E(a_j) ight|)
(a_j) 为卷积核 (f_i) 中的一个权重,类似全连接网络中的一个节点(将卷积核内的每个权重看做全连接网络的一个节点),卷积核 (f_i) 有 (r) 个节点,每个节点的激活值是所有训练集样本的平均激活值,每个节点的激活值之和作为该卷积核的 重要性。
&& 这里感觉不是特别严谨
简单理解应该就是将n个训练集样本跑一遍,将某个卷积核输出的n个(ReLU后的)feature map的平均值,作为该卷积核的重要性。
实际实验中用到的指标有以下几种:
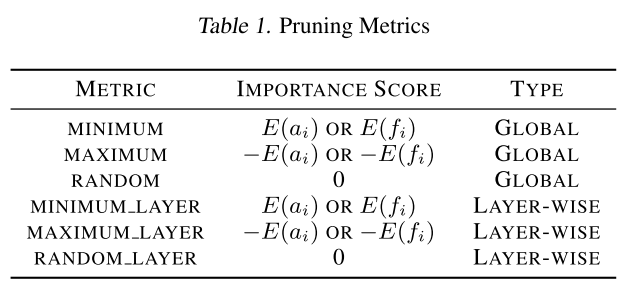
每轮剪枝都是将metric值低的节点/卷积核剪掉
- MINIMUM:以 (E(a_i) or E(f_i)) 为重要性metric,将全局的节点/卷积核剪掉比例p
- MAXIMUM:以 (-E(a_i) or -E(f_i)) 为重要性metric,将全局的节点/卷积核剪掉比例p(相当于将 (E(a_i) or E(f_i)) 值大的卷积核剪掉,以便对比 MINIMUM 的重要性metric是否有效)
- MINIMUM_LAYER:以 (E(a_i) or E(f_i)) 为重要性metric,每层剪掉相同的比例p
- MAXIMUM_LAYER:以 (-E(a_i) or -E(f_i)) 为重要性metric,每层剪掉相同的比例p
- RANDOM/RANDOM_LAYER: 随机剪枝
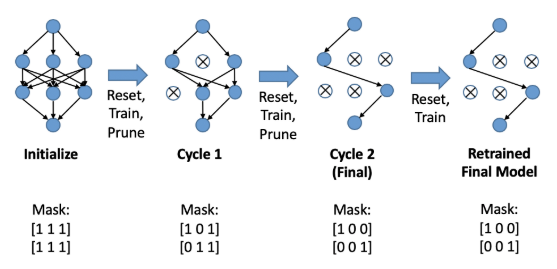
剪枝流程

算法输入:网络的初始权重 (θ_0) ,全连接网络的节点个数/卷积网络的卷积核个数 n,重要性metric
超参数:每轮训练的 iteration 数 (j) ,每轮的剪枝率 (p∈(0,1]) ,acc最大下降系数 (κ) ,初始化mask (m={1}^{|n|})
repeat
- 重置网络参数为 (θ_0)
- 在网络 (f(x;n)) 上应用mask (m) => (f(x;m⊙n))
- 训练 (j) 个iteration
- 根据重要性metric,在mask上剪掉p的节点/卷积核,更新mask
until 验证集准确率 (a'≤κa)
再运行一次步骤 1-3
Experiments
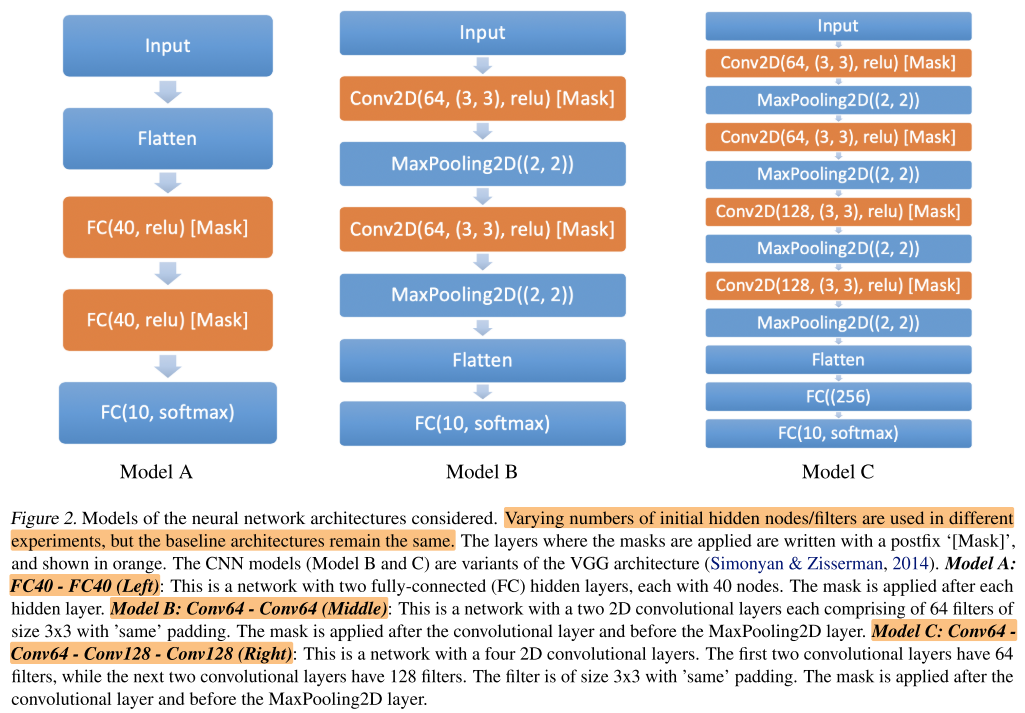
实验的backbone网络,大致是在这几种网络上进行实验。
MLP-MINIST
Q1. Can DropNet perform robustly well on MLPs of various starting configurations?

评价:
对于全连接网络,隐藏层的大小相等的情况下(没有bottleneck layer),minimum_layer metric效果更好;当隐藏层大小不等的情况下,minimum metric 更好。
CNN - MNIST
Q2. Can DropNet perform robustly well on CNNs of various starting configurations?
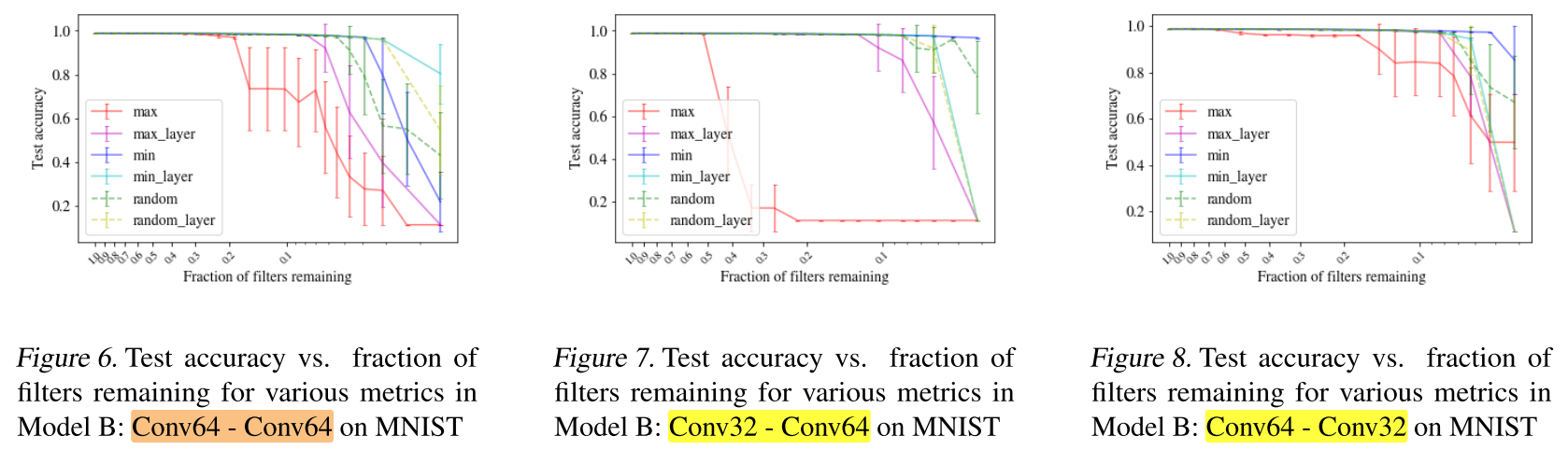
评价:
对于卷积网络,隐藏层的大小相等的情况下(没有bottleneck layer),minimum_layer metric效果更好;当隐藏层大小不等的情况下,minimum metric 更好。(和全连接网络的结论相同)
使用 DropNet,可以剪掉90%的卷积核而不带来精度损失。
CNN - CIFAR-10: Model C
Q3. Can DropNet perform well on a larger dataset like CIFAR-10?
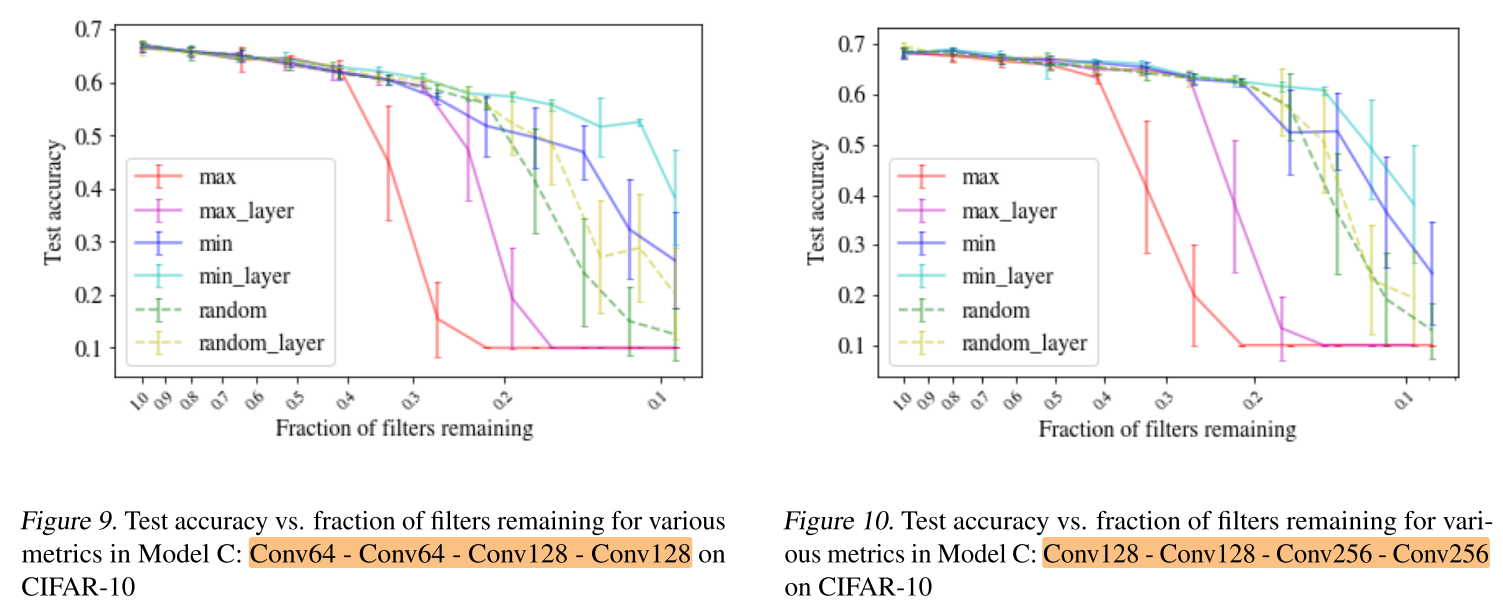
评价:
minimum 和 minimum_layer 在剪枝率<50%的时候效果都很好,>50%之后,minimum_layer的效果更好。
CNN - CIFAR-10: ResNet18/VGG19
Q4. Can DropNet perform robustly well on even larger models such as ResNet18 and VGG19?
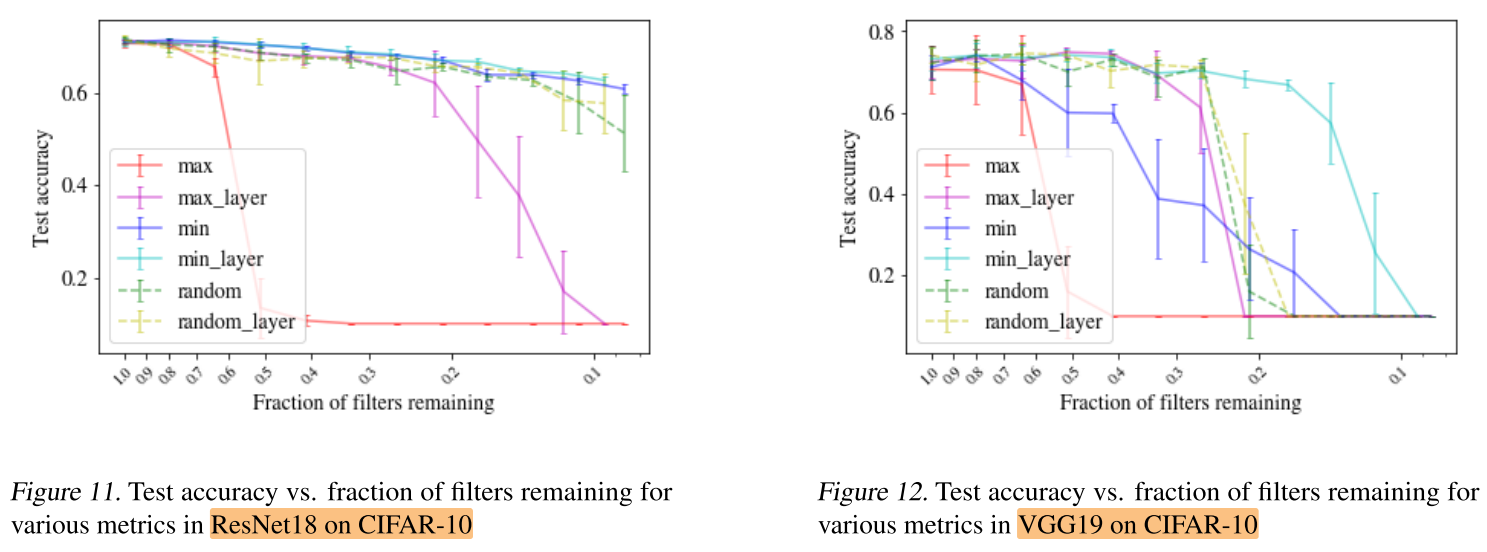
评价:
对于大网络,minimum_layer 效果更好。
对于ResNet-18,minimum_layer 和 minimum 表现相当;但对于VGG-19,minimum表现的比Random还差,说明ResNet-18中的 skip connection 可以缓解全局度量minimum的一些缺陷。
有趣的是,minimum 会修剪ResNet-18中的一些 skip connection,说明部分 skip connection可能不是必要的。
总之,DropNet可以在不显著影响精度的情况下,将卷积核数量减少80%甚至更多。
Oracle Comparison
Q5. How competitive is the DropNet algorithm compared to an oracle?

评价:
minimum metric 和 oracle相当。
Random Initialization
Q6. Is the starting initialization of weights and biases important?
以下实验对比每轮迭代初始化为原始权重 (θ_0) 和随机初始化的结果。
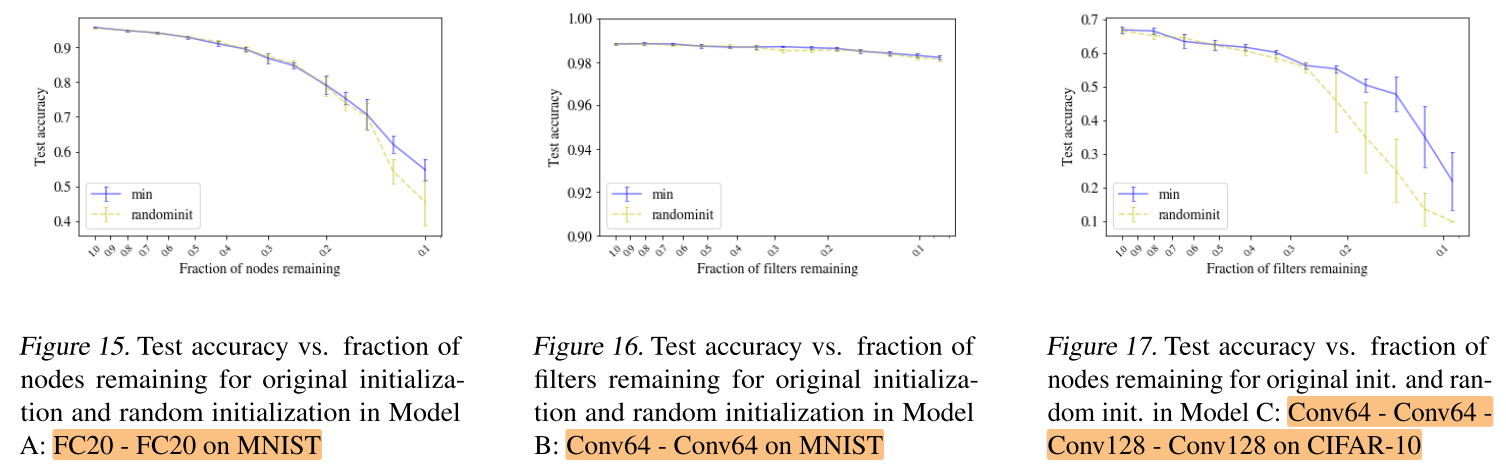
评价:
说明对于DropNet 方法来说,每轮迭代之初的权重初始化不重要(&& 明明图17中的差距挺大的),而是最终的剪枝结构更重要。
可能的原因是,每轮迭代权重随机初始化后,都会有足够的训练轮数,使得精度可以恢复。
Percentage of nodes/filters to Drop
Q7. Can we drop more nodes/filters at a time to reduce number of training cycles and prune the model faster without affecting accuracy?
超参敏感性分析,每轮迭代修剪的比例p设置为多少:
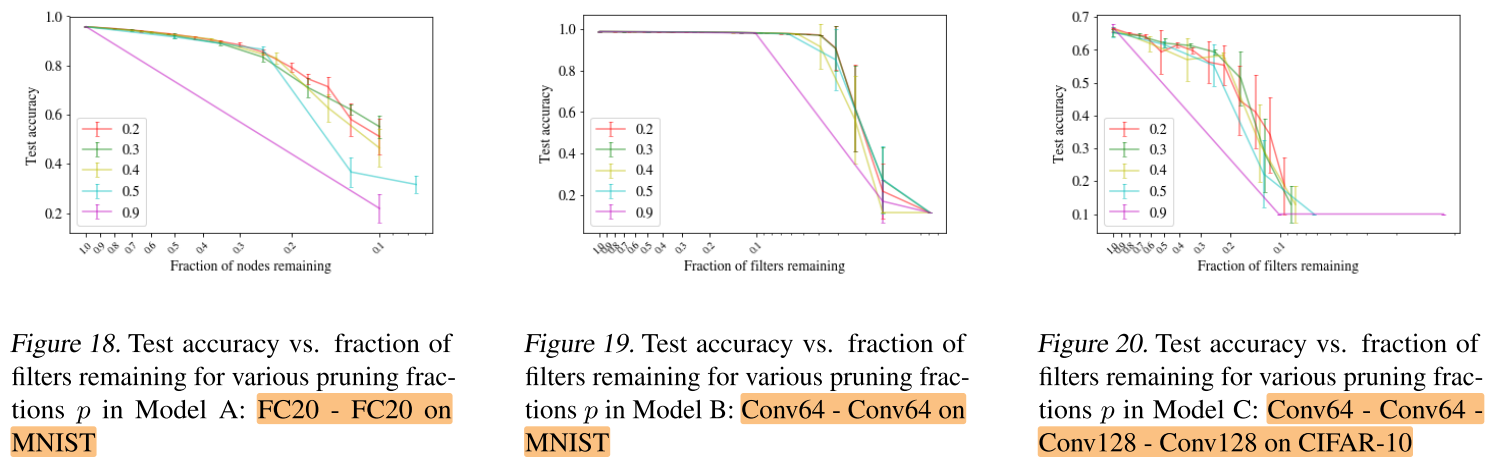
评价:
总体来说,p越小越好,即每轮剪掉的比例越小越好
Conclusion
Summary
Weakness
- 对比方法选了很老的Oracle
- 实验的数据集都很小:MINIST/CIFAR10
- 实验的网络大部分都很简单:FCN / 3-4层的CNN
- 基于激活值的metric很简单,创新性一般
- 虽然实验很多,但大多数实验都很简单,平平无奇,而且实验部分有很多重复的语句
- 迭代剪枝没有做剪枝的时间开销方面的实验,比如p越小
- ICML?
Strength
- 每个实验都采用 “提问-做实验-结果评价” 的顺序,逻辑比较清楚