Balanced Sparsity for Efficient DNN Inference on GPU
2019-AAAI-Balanced Sparsity for Efficient DNN Inference on GPU
来源:ChenBong 博客园
- Institute:THU, HIT, Beihang, MSRA
- Author:Zhuliang Yao, Shijie Cao, Wencong Xiao
- GitHub:https://github.com/Howal/balanced-sparsity/
- Citation:22
Introduction
传统的剪枝一般分为 filter剪枝 和 weight剪枝,其中filter剪枝的粒度是整个卷积核,weight剪枝的粒度是单个权重。
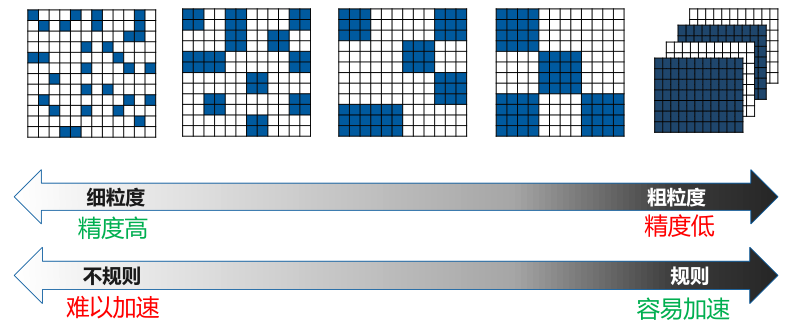

filter剪枝 和 weight剪枝 之间还有“中等粒度”的剪枝,如 vector,block,kernel 等。
本文提出的是一种新的不是基于粒度的剪枝方法,即 balance sparsity 。(balance sparsity的概念应该是这篇文章第一次提出来的)
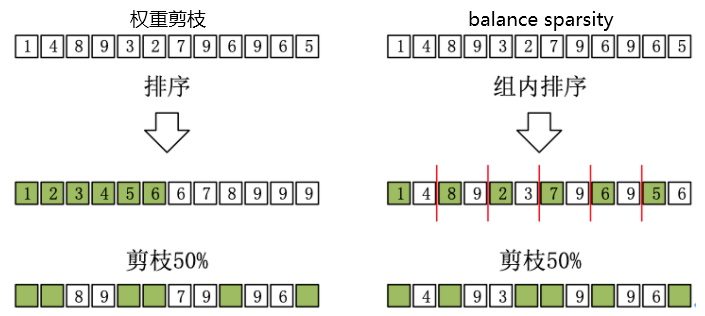
和A100相同都是balance sparsity,不同在于A100的pattern固定为2/4,本文提出的pattern的n/m的n,m都是可以调整的(同一个网络使用同一个m,同一层使用同一个n,但不同层的n可以不同,如第1层3/32,第2层4/32...)。
Motivation
motivation 很简单,weight剪枝 精度高,但加速困难;filter剪枝 加速效果好,但对精度低。
已有的不同粒度(vector,block,kernel)的剪枝本质上都是在(精度高、加速困难)和(精度低、加速容易)之间作权衡而已,是否存在精度又高,加速效果又好的剪枝方法?于是本文就提出了一种全新的稀疏 pattern balance sparsity。
Contribution
- 提出了一种新的稀疏pattern:sparsity balance
- sparsity balance 的GPU实现
- sota 的 speed up
Method
pattern

逐层迭代剪枝:
- 每一层视为一个Matrix,每一行划分为相同大小的block
- 该Matrix内每个block 的稀疏率是相同的, (tmp_{sparsity}) 从0开始逐渐提高到 target sparsity,每轮根据 (tmp_{sparsity}) 对每个block单独进行剪枝
- 如果 (tmp_{sparsity}) 未达到 target sparsity,重复2
每次剪枝后都进行fine-tune,如果性能急剧下降则撤回该次剪枝并停止当前 Matrix 的剪枝

GPU实现
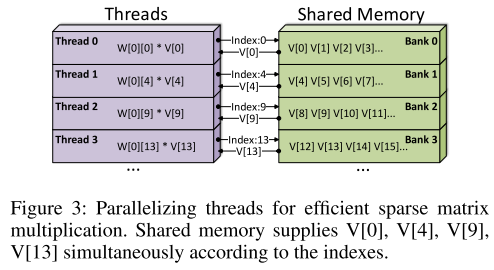
每个block中非零元素的个数相同,可以充分利用GPU高并行的特性
每个block用单独一个线程处理
(cuda编程)
Experiments
Matrix Benchmark
we conduct a benchmark to compare the inference time of a matrix multiplication among all existing sparsity patterns. This benchmark uses a matrix size of 16384 × 8192.
| pattern | library |
|---|---|
| dense | cuBLAS |
| random sparse | cuSPARSE |
| vector | no library,不做latency的对比 |
| block sparse | open sourced GPU library |
| balanced sparse | our GPU implement |
ideal为理论加速曲线,i_time = (d_time−o_time)∗(1−sparsity)+o_time. (we take 10us as o time)

Notice that using cuSPARSE for sparse computation can achieve speedup only if the sparsity ratio is higher than around 91%, while our method is always faster than the dense baseline.
Real Workloads
VGG-16 on ImageNet
dense,random,block,balance都是在相同的精度下(top5=90.03%)
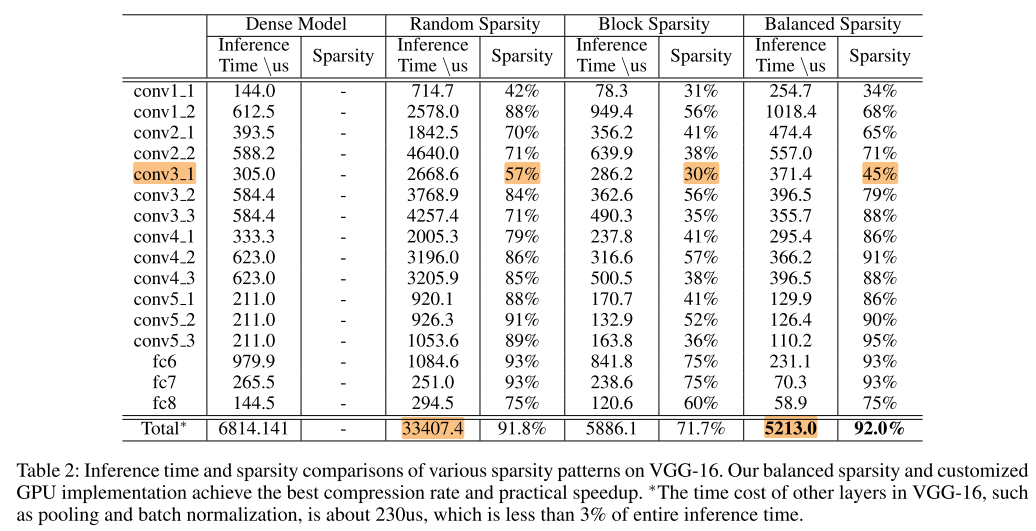
在相同的精度下,balance sparsity 的稀疏率和random几乎一致,且有一定的加速效果。
LSTM on PTB
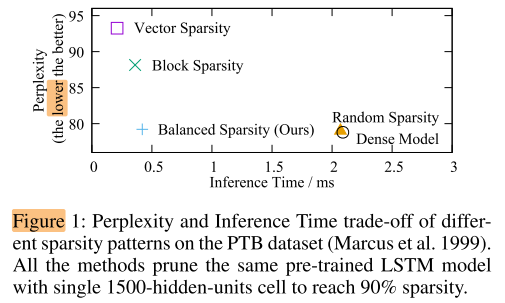
balance sparsity 可以在和dense、random 相当的精度下,取得很好的加速效果。
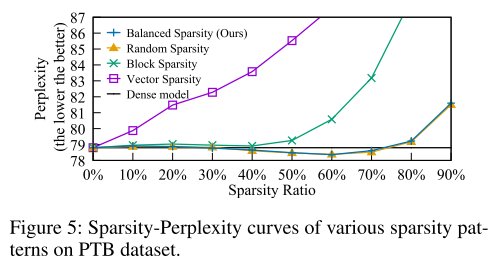
balance sparsity 和 random在不同稀疏率下的精度几乎一致。
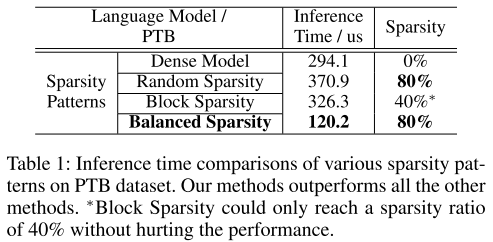
3.1x speedup compared to the random sparse model running on cuSPARSE,
2.7x speedup compared to the block sparse model running on block sparse library,
2.5x speedup compared to the baseline dense model running on cuBLAS.
可以看出,balance sparsity 在LSTM上的加速效果比CNN更好。
Ablation Study
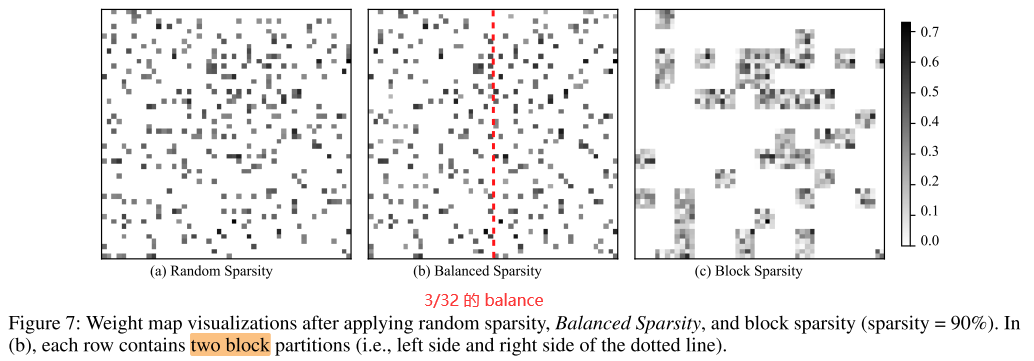
Figure 7 shows a random-selected 64 × 64 block from the same position of 1500 × 1500 weight matrix in our LSTM experiment, under the sparsity ratio of 90%.
balance sparsity 的稀疏模式和 random sparsity 十分相似,可能是两者性能接近的原因之一。
对比block sparsity 和 balance sparsity 的 Sensitivity:
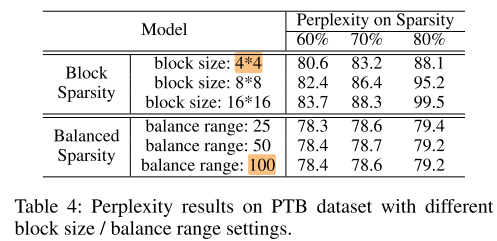
可以看出,在相同稀疏率下,balance sparsity 受到不同 range 的影响很小,block sparsity 受到不同block的影响很大。
其中 block sparsity 的block越小,balance sparsity 的 range 越大,越接近 random sparsity,性能越好,加速效果越差。
Conclusion
本文提出的 balance sparsity pattern 与稀疏pattern中性能表现最好的 random sparsity 在性能上几乎一致,却能提供更高的加速比,可以视为 random sparsity 的更好的替代。
在LSTM上可以在不损失模型性能的情况下达到2.5x的GPU加速比,在CNN上也有一定的加速效果。
Summary
没有与加速比最高的filter剪枝进行对比,在相同加速比的情况下稀疏率的对比,体现 balance sparsity 的加速能力。
random,block,balance的加速对比都是基于GPU library,受 library 的影响较大。
没有在GPU之外的平台上的实验。
To Read
Reference
https://www.jiqizhixin.com/articles/2019-06-25-18
https://zhuanlan.zhihu.com/p/148211855