Dynamic Convolution
2020-CVPR-Dynamic Convolution Attention over Convolution Kernels
来源:ChenBong 博客园
- Institute:Microsoft
- Author:Yinpeng Chen,Xiyang Dai,Mengchen Liu
- GitHub:
- Citation: 30
Introduction
类似CondConv的条件卷积层,对每个样本单独计算不同的卷积层
方法几乎一致,出发点不同,CondConv是从分支集成的角度,本文是从权重Attention的角度
每层有K套权重,每个样本计算一组attention:(pi_1...pi_K) ,对K套权重加权求和:
attention 计算过程:
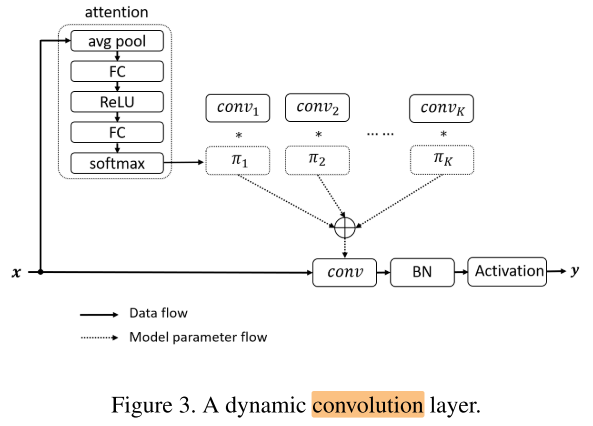
Motivation
Contribution
- 提高小计算量下模型的性能(不适用于大网络,占用K倍的显存)
- 使用多套权重,在略微增加一点计算量的条件下,增强模型的表达能力
- 不同的样本x有不同的attention
- 其他动态网络,都是固定权重+动态结构;本文的方法是动态权重,固定结构
Method
与CondConv的对比:
CondConv
出发点:分支集成
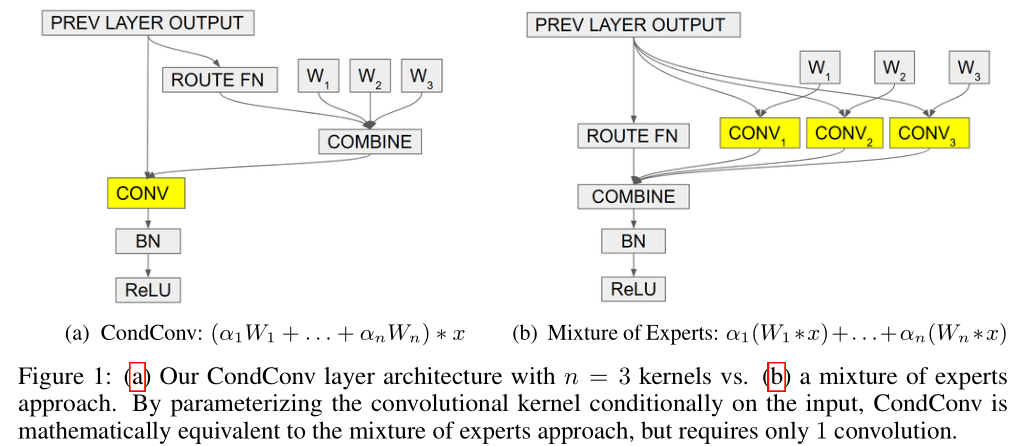
权重聚合的方式:
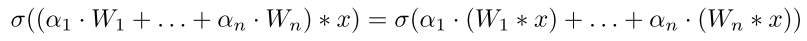
(alpha) 如何得到?
- routing function: (alpha) 是输入x的函数,其中R是 fc 层的参数),将 pool(x) ==> n dim
- (α=r(x)=sigmoid(fc(avg pool(x))))
Dynamic Convolution
出发点:权重attention
权重聚合的方式:
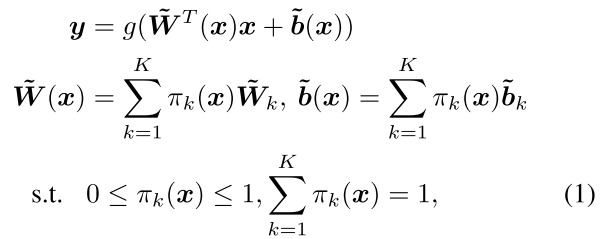
(pi) 如何得到?
- (pi=softmax(fc(relu(fc(avgpool(x))))))

2个主要区别: (Sigma~pi=1) 的约束,退火的attention
Sum the Attention to One

以K=3为例,加入 (Sigma~pi=1) 的约束后,聚合后权重的空间从2个三棱锥内部空间,缩小到三角形的面上,有利于 (pi) 的优化
Near-uniform Attention in Early Training Epochs
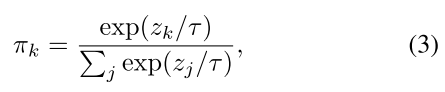
前期 attention 较为平均,有利于初始阶段的各套权重的学习:
与CondConv实验比较
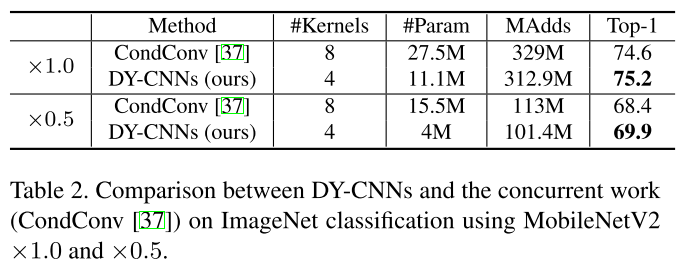
加入了以上2个trick,使得此类方法所需的权重套数变少(8 => 4),且性能更好
Experiments
ImageNet
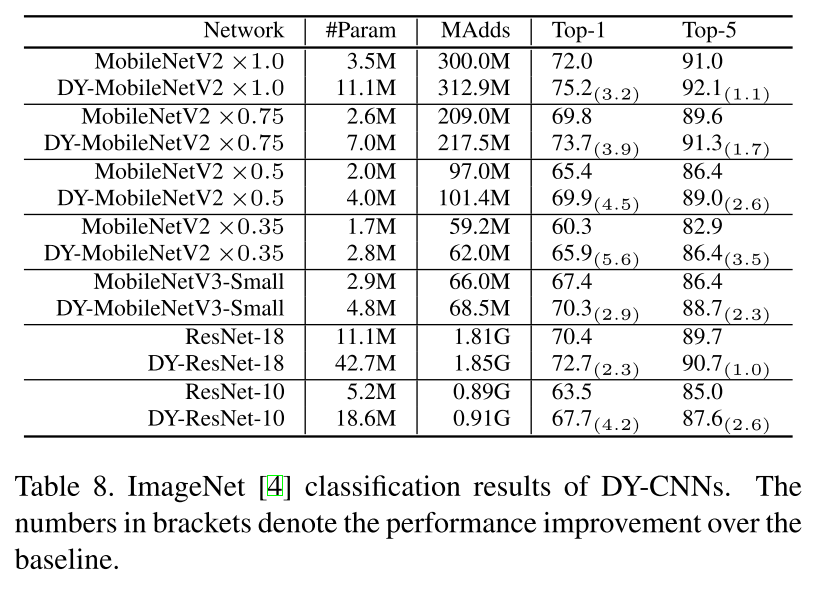
只能在小模型上实验,虽然MAdds增加不多,但训练阶段显存占用估计是原始网络的K倍
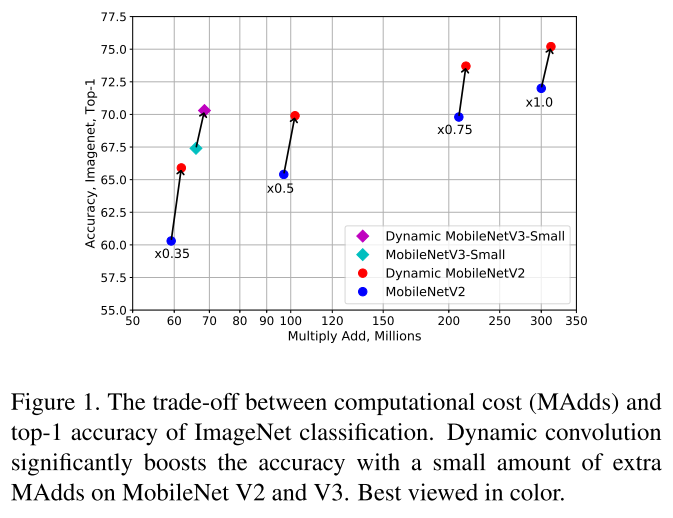
对MBv2/v3的改进效果
Ablation
不同的权重聚合方式
- attention:K套权重加权求和
- average:K套权重取平均(不同样本使用的weight都是一样的,weight不再有 input-dependency)
- max:取K套权重中,(pi_i) 最大的那套权重(有 input-dependency,但每个input只使用一套weight的知识,证明对于同一个input x使用多套weight聚合的有效性,最后并不是收敛到某套weight上)
- shuffle per image:同一个 (x) ,shuffle K套权重的 (pi) (证明网络确实学到了该如何分配K套 weight 的权值)
- shuffle across images:对图片 (x) 使用图片 (x') 计算得到的 attention(证明确实存在 input-dependency )
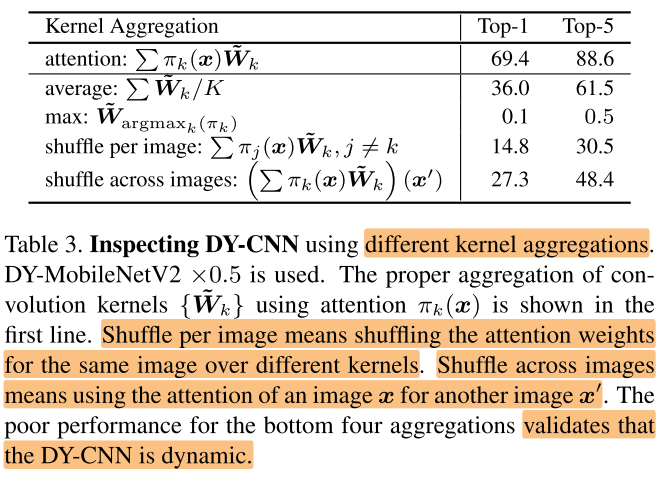
实验中观察到 attentions are flat at low levels and sparse at high levels. 的现象(在CondConv中同样观察到该现象),这也可以帮助解释表3中,max操作(sparse)对low layer有损害,而 avg 操作(flat)对high layer有损害,因此这2个操作会导致网络性能下降
不同层是否启用attention
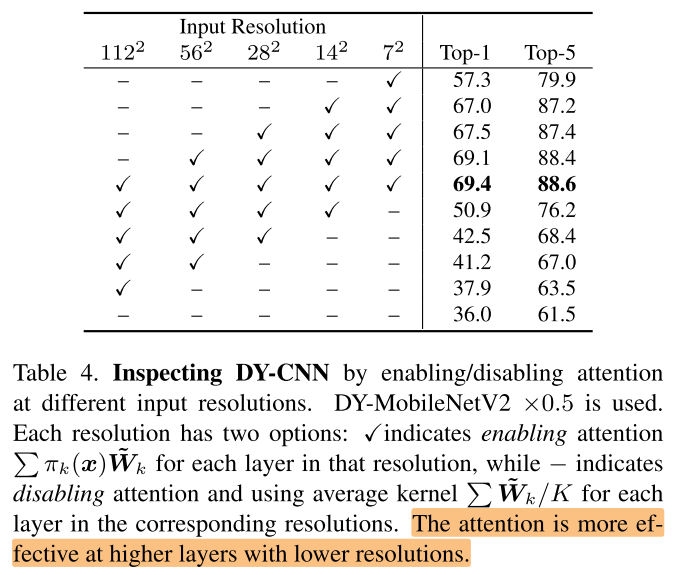
较深的层启用 attention 的效果较好
The number of convolution kernels (K)

K越大性能提升越好,K>=4以后提升不大
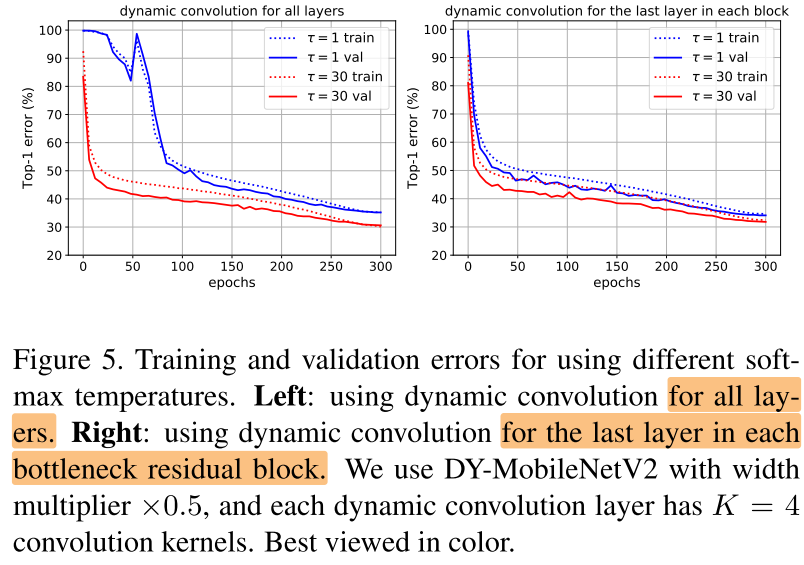
Softmax Temperature (( au))
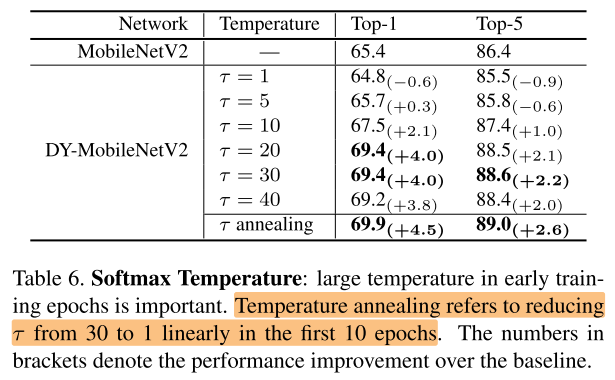
对 中的 ( au) 做消融实验
Conclusion
Summary
- 对CondConv的2个小的改进,提高了一点性能,补充了一些实验,一些现象在之前的CondConv中也有观察到,不够 novel
Reference
https://blog.csdn.net/weixin_42096202/article/details/103494599
https://blog.csdn.net/weipf8/article/details/105756526/
https://www.yuque.com/z_zhang/is/edrrwq
https://zhuanlan.zhihu.com/p/149805261