高级查询
标准查询
select */字段列表 from 表名 [where条件];
完整查询
select [select选项] */字段列表[字段别名] from 数据源 [where子句] [group by子句] [having子句] [order by子句] [limit子句];
一、select选项
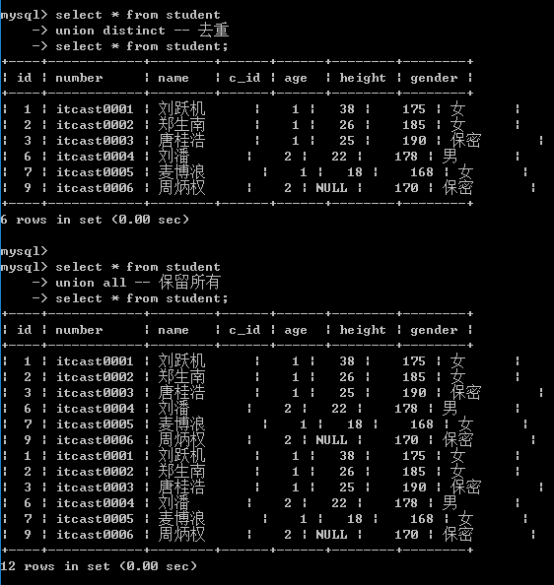
select选项: 用来控制数据的重复性
- all: 保存所有数据,重复的也无关(所有字段都重复), 默认的
- distinct: 去重,去掉重复记录(所有字段都重复)

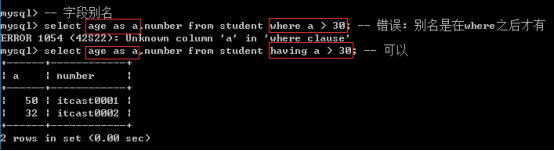
二、字段别名
字段在不同的表中很有可能同名, 同名之后外部的操作就可能无法进行区分数据: 需要对字段进行重命名给外部使用.(别名是在字段数据被取出到内存之后才拥有, 不会改变磁盘本身的字段名字)
别名语法
字段名 as 别名; -- as关键字
字段名 别名; -- as关键字可以省略

三、数据源
数据源: 数据的来源: 只要能够提供一张二维表
普通数据源: from 表名;

数据源可以是一张表,也可以是多张表
from 表名1,表名2...

逻辑: 从左边的一张表取出一条记录与右边表中的所有记录进行匹配: 都保留; 字段数都直接左边的放左边,右边的在后面追加(右边): 这种计算方式得到的结果: 笛卡尔积
笛卡尔积: 是一种无效连接操作, 没有意义: 应该尽量避免笛卡尔积出现.
来源不是表: 而是select语句产生的临时结果: 子查询
from (select语句) as 别名; -- from只认表: 必须给结果绑定一个表名

四、where子句
where子句: 是一种判断: 最终where返回的结果永远是0或者1: 0代表false, 1代表true
where后面的条件才是最终的判断:
- 比较运算: >, < ,>= , <= , !=, <>, =, in, between and
- 逻辑运算: and&&, or||, not
in操作: (附带逻辑运算)

between 左边数据 and右边数据: 操作
- 左边数据必须小于右边数据
- 左边数据和右边数据是闭区间
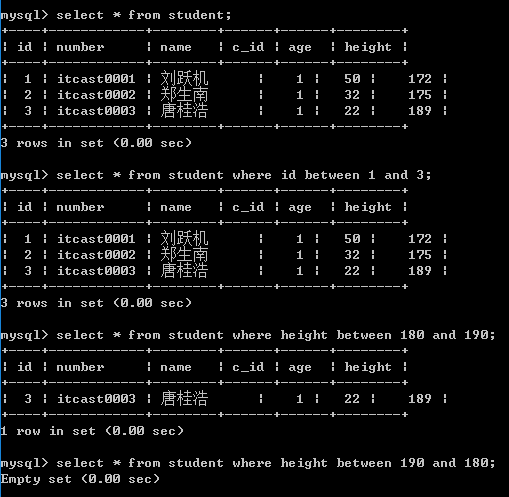
where原理: 从磁盘一条一条的取出数据: 取出之后在内存真正保留之前,将记录中的某个字段取出(where条件限制) 与条件进行比较: 返回结果为1就保留到内存; 否则就放弃.

where之前的操作都是在磁盘进行操作: where之后的所有操作都是在内存.(where不能操作字段别名: 字段别名是在where之后才会生成)

五、group by子句
group是分组的意思: group by 字段: 通过字段进行分组
分组的本意是为了统计.
语法规则: select * from 表名 group by 字段名;

分组统计: 每组只能返回一条记录(第一条记录)
分组的结果是为了统计: 统计函数
- count(*/字段): 统计记录数(条数)
- max(字段): 统计每组中最大的数据
- min(字段): 最小结果
- avg(字段): 分组平均值
- sum(字段): 求和

分组统计原理: 在系统中模拟划分多块内存(如果分组字段不一样,存放到不同的内存中), 最后统计数据的时候在不同的分组中统计,统计完结构,分别提交(汇总)

count()函数统计字段的时候,只能统计不为空的字段数据

分组排序: 分组会自动根据group by对应的字段进行升序排序
group by 字段 [asc|desc];

多字段分组: 先根据某个字段进行分组, 然后在对已经分组的数据再次进行另外的分组
group by 字段1 [排序], 字段2 [排序];

回溯统计: 当每个被分的组最后统计的时候, 会向上一层根据分组字段进行一次新的统计
with rollup;

六、having子句
having就是与where一致: 用于做条件判断: 因为groupby会进行数据的统计分析, 那么统计分析的结果有可能不是所需结果: 需要对结果筛选.
几乎所有where能做的事情,having都可以做.
不是所有的数据都有必要进入到内存: where在进入内存之前就进行数据筛选; having是针对内存数据进行筛选: 是针对where之后的分组统计(groupby)的结果进行筛选.
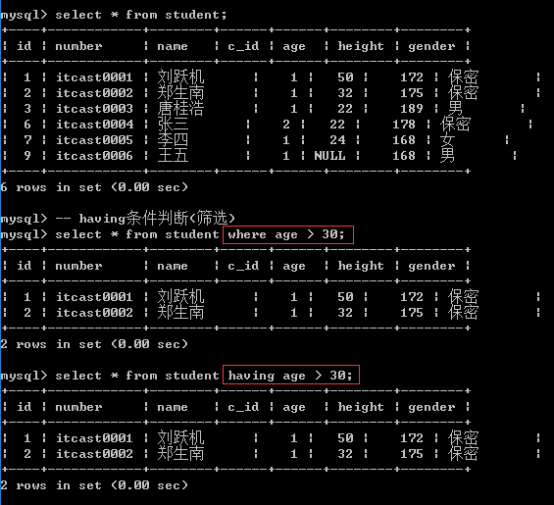
having主要针对是groupby操作: 凡是groupby的操作结果(统计函数),where都不能用,但是having能用.

字段别名是在where之后数据进入到内存的时候才有的,所以where不能使用字段别名,但是having可以
七、order by子句
order by: 对字段进行排序
order by 字段 [asc|desc]; -- asc默认升序, desc是降序

NULL永远按照最小的数据进行运算
多字段排序: order by 字段1 [asc|desc], 字段2 [asc|desc]...;

八、limit子句
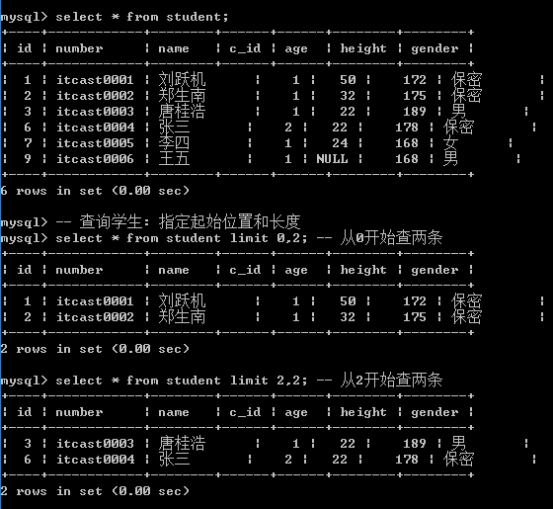
limit: 限制记录数
用法1: 限制数量: limit 记录数

用法2: 限制数据同时限制起始位置: limit offset,length
offset: 起始位置: 从查询出的多条数据中的某一条位置开始(默认第一条记录是0)
length: 长度,从起始位置开始向后获取指定长度的记录数(如果不够不影响)
联合查询
联合查询: 将多个查询的结果进行合并: 记录合并(字段不会增加)
一、基本用法
语法:select语句 union [union选项] select语句 ...; -- 可以有多个union
要求: union前边的select语句的字段数 必须严格等于右边的select语句的字段数
union选项
- all: 保留所有的记录
- distinct: 去重(默认的)
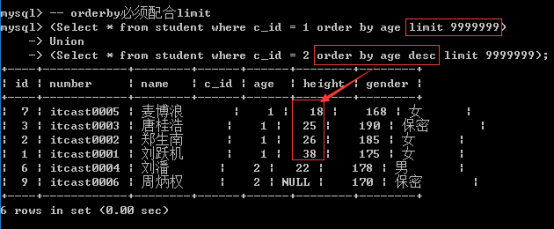
二、联合查询使用order by
需求: 将所有学生按照班级分开: 两个班级: 1班按照年龄升序排序, 2班使用年龄降序排序
解决方案: 按照需求解决
select * from student where c_id = 1 order by age
union
select * from student where c_id = 2 order by age desc;

解决1: 要在union中使用order by必须将select语句进行括号包裹: ()

解决2: 若要order by生效,必须配合limit语句
三、联合查询意义
哪些地方会用到联合查询呢?
- 在查询过程中,需要根据不同的条件进行查询, 将所有查询结果进行合并
- 在数据库优化之后: 会将数据表进行分表操作(一张表存储的数据量不会太大: 太大影响效率): 最终统计的时候,需要将所有表的结果合并.

联合查询只要求字段数一致即可,不需要数据类型对应: 字段名都是第一条SQL语句中的字段名
连接查询
连接查询: 将多个表进行连接(基于字段的: 基于条件), 将符合条件的所有结果进行保留(字段一定会增加,但是记录数未必)
连接查询分类: 内连接, 外连接, 交叉连接和自然连接
连接关键字: join, 一定至少由两张表构成: 示例: 表1 join 表2
- 左表: join关键字左边的表 , 表1
- 右表: join关键字右边的表 , 表2
连接的基本原理: 从一张表中一次取出所有记录(每次取一条), 去另外一张表中进行挨个匹配: 匹配成功的就保留,失败就不要.
一、交叉连接
交叉连接: cross join: 左表的记录与右边的记录进行连接之后,全部保留: 导致的结果是:
- 记录数 = 左表记录数 * 右表记录数
- 字段数: = 左表字段数 + 右表字段数
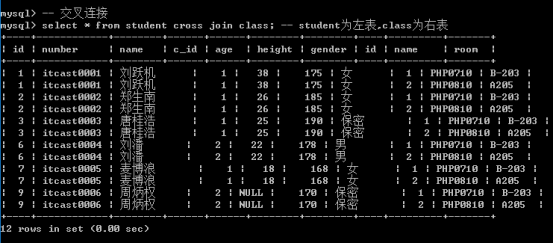
交叉连接的结果: 笛卡尔积(尽量避免)
交叉连接的存在的意义: 因为要保证结构的完整性
二、内连接
内连接: inner join, 从左表的每一条记录去匹配右边的每一条记录: 但是只有条件满足的情况下记录才会被保留, 否则不保留.
基本语法: 左表 [inner] join 右表 on 左表.字段 = 右表.字段;

如果内连接不使用on条件: 没有条件就会变成交叉连接(笛卡尔积)

内连接可以使用where代替on

连接查询中可能因为每个都有同名字段: 查询结果中会同名: 通常需要对字段使用别名(为了简便,还会对表使用别名);

三、外连接
外连接: outer join,与内连接相似, 从左表(主表)找出每一条记录与右表(从表)中的每一条记录进行匹配: 匹配成功则保留, 匹配不成功也保留(从表对应的字段全部置空)
外连接分为两种: 左外连接(left join)和右外连接(right join)
左右外连接: 左表或者右表是主表(外连接记录数肯定不会少于主表记录数)
左外连接: left join

右外连接

右连接转换成左连接

不管是左连接还是右连接: 左表的数据字段一定在左边,右表的在右边
外连接必须使用on作为条件: 而且不能使用where替代.

四、自然连接
自然连接: natural join, 是一种自动匹配条件的连接
自动匹配条件: 找两张表同名字段
自然连接包含自然内连接和自然外连接
自然内连接
左表 natural join 右表;
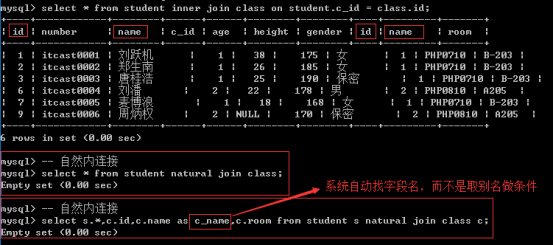
自然连接匹配字段之后会自动合并字段

自然外连接
左表 natural left/right join 右表;

内连接和外连接完全可以模拟自然连接: 使用关键字using作为连接条件
左表 inner join 右边 using(字段列表); -- 字段列表就是两张表的同名字段

正是因为内连接和外连接都可以使用using关键字代替on作为连接条件: 完全可以模拟自然连接: 因此真正使用的只有内连接和外连接.
多表连接: A join B on 条件 left join C on 条件...
子查询
在一条查询语句(select) 中又出现了另外一条查询语句(嵌套出现): 把这种查询语句的内部也出现了查询语句叫做子查询.
子查询分类
位置分类: 根据子查询所在select语句中出现的位置
- From子查询: 子查询语句跟在from之后
- Where子查询: 子查询在where条件内部
- Exists子查询: 子查询出现在exists里面
子查询返回结果分类: 根据子查询得到的结果进行分类
- 标量子查询: 子查询返回的结果是一行一列
- 列子查询: 子查询返回的结果是一列多行
- 行子查询: 子查询返回的结果是一行多列(多行)
- 表子查询: 子查询返回的结果是多行多列
一、标量子查询
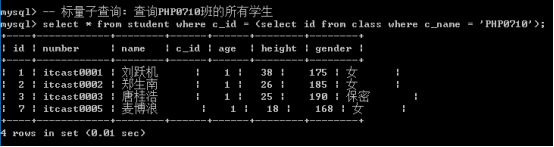
需求: 知道班级名字(PHP0710),找出所有该班学生
1、从学生表查询数据
select * from student where c_id = ?;
2、求出班级id
select id from class where c_name = ‘PHP0710’;
解决方案: 将两个步骤合并: 问号占位符就是需要下面select语句的执行结果.
二、列子查询
需求: 求出所有已经在读的学生(已经分配到班级在上课的)
1、获取学生数据
select * from student where c_id in ?;
2、获取所有的班级id
select id from class; -- 一列多行

In表示在某个指定的集合中: any,some,all
- any: = any, 表示数据等于any集合中的任意一个即可.
- some: some与any完全一样
- all: 表示全部

not in, not any, not some,not all的区别

三、行子查询
需求: 找出所有学生中年龄最大,且身高最高的学生.
1、确定数据源
select * from student where (age,height) = ?;
2、求出最大的年龄和最大的身高
select max(age),max(height) from student;
行子查询: 需要构造行元素: 由多个字段构成的元素, 上面的age和height就构成了一个行元素(age,height) = 值(两个内容构成)

四、表子查询
需求: 找出每个班的年龄最大一个学生
1、确定数据源
select * from student group by c_id order by age desc;
问题相当明显: 先分组,取出每组的第一个, 取出所有结果之后按照年龄排序
解决方案: 在group by先排序
2、先将数据源排序:
select * from student order by age desc;
3、对已经排序的数据进行group by操作
select * from ? Group by c_id;

五、exists子查询
判断一个内容是否存在: 本身返回的结果是0或者1, exists都是接where
where exists(子查询);
