分组
关键词: group by 列名
作用: 对源数据,按照指定的列,进行分组操作.
sql语法结构: select... from ... where ... group by 字段 order by ...
--统计各个部门的平均工资?
人工操作思路:
① 确定分组的依据,对原表数据进行分组.[group by 分组]
② 对每个组进行统计操作(平均值)[组函数 统计]
SQL书写步骤
① 确定分组依据,进行分组操作: group by department_id
② 对分组后的每组,统计salary的平均值. avg(salary);
③ 组合SQL
select avg(salary), department_id
from employees
group by department_id;案例2:
-- 统计各个职位的人数和职位名称信息?
SQL思路:
1. 确定分组依据,进行分组操作: group by job_id
2. 对分组后的每组数据,统计人数: count(employee_id)
3. 组合SQL
select count(employee_id),job_id
from employees
group by job_id;总结: sql执行顺序
select... from ... where ... group by 字段 order by ...
执行顺序:
from 确定表
where 对数据进行条件过滤操作. [符合where条件的数据]
group by 对满足where条件之后的数据进行分组操作. [数据变成组数据]
select 选择要展示的信息
order by 排序group by 语法规则
1. group by 在 where 之后执行的
2. select 后可以写分组 group by 所依据的字段(列)
3. select 组函数统计字段.分组过滤
关键词: having 条件
作用: 对分组之后的组数据进行过滤.
语法结构: select ... from .. where .. group by ... having 组数据判断条件 order by ...
-- 统计平均工资超过8000的部门id和平均工资?
错误:
select department_id,avg(salary)
from employees
where avg(salary)>8000
group by department_id;
正确:
思路:
1. 分组 group by department_id
2. 分组后的组数据进行过滤 having avg(salary)>8000
3. 组函数统计展示 avg(salary)
4. 组合SQL
select avg(salary),department_id
from employees
group by department_id
having avg(salary)>8000;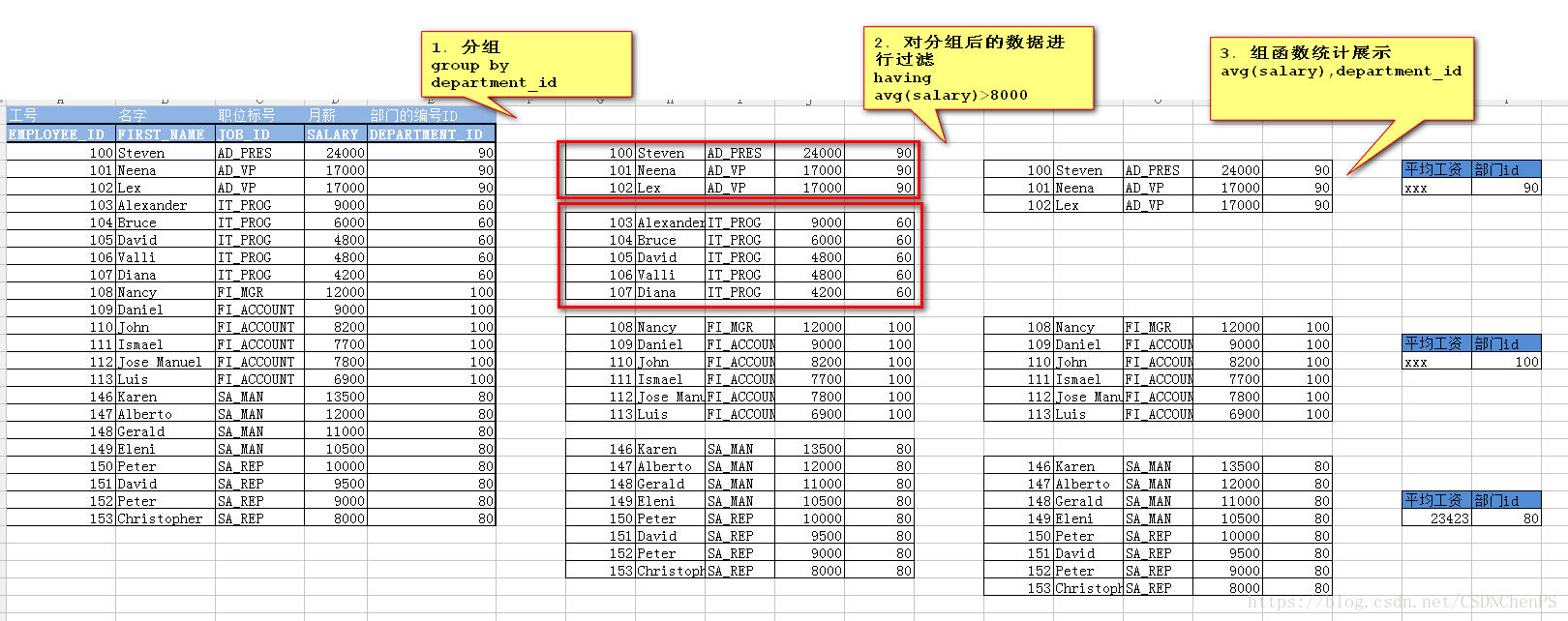
重点说明:
-- 统计80,90,100 部门的总工资,部门id?
思路1:
1. 分组 group by department_id
2. 分组后的数据过滤: having department_id in (80,90,100)
3. 对满足having的组,组函数统计 sum(salary)
select sum(salary),department_id
from employees
group by department_id
having department_id in (80,90,100);
思路2:
1. 使用where关键字,对原表数据进行过滤操作 where department_id in (80,90,100)
2. 根据部门id进行分组: group by department_id
3. 对每个组统计总工资, 部门id
select sum(salary),department_id
from employees
where department_id in (80,90,100)
group by department_id;
结论:
1. where 是在分组之前对数据进行过滤操作
2. having 是在分组之后,对组进行过滤操作
3. 如果where和having同时都能满足查询需求,优先使用where.SQL执行顺序总结
sql语法规则:select ... from .. where .. group by ... having 组数据判断条件 order by ...
sql执行顺序
from 确定表 where 对数据进行过滤 (分组之前) group by 分组 having 分组之后的数据进行过滤 select 选择要展示信息(组函数统计,分组依据字段,xxx) order by 排序