爬取小说网站章节和小说语音播放(文章末-->获取源码)
爬去小说网站说干就干!!
现在来了,撸起袖子开始就是干!!
百度搜索一下 "小说网站" ,好第一行就你了,目标-->"起点小说"

点击进去复制改小说的网址为:起点小说("https://www.qidian.com/")
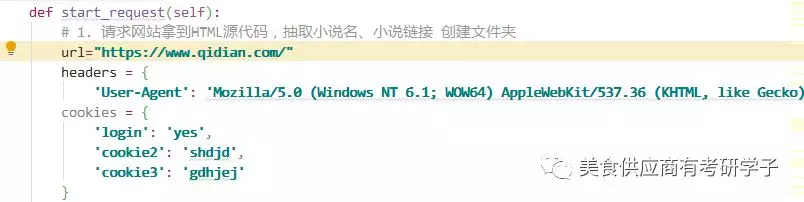
1,获取网站的骨架-"html"下面你的是伪造浏览器向该小说网站发送请求的面具-->hearder:{....}
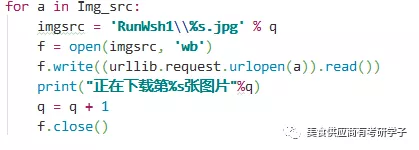
下面为了让读者更好的理解我就以一个最简单你的批量图片下载来讲这个步骤吧,,源码会放在后面
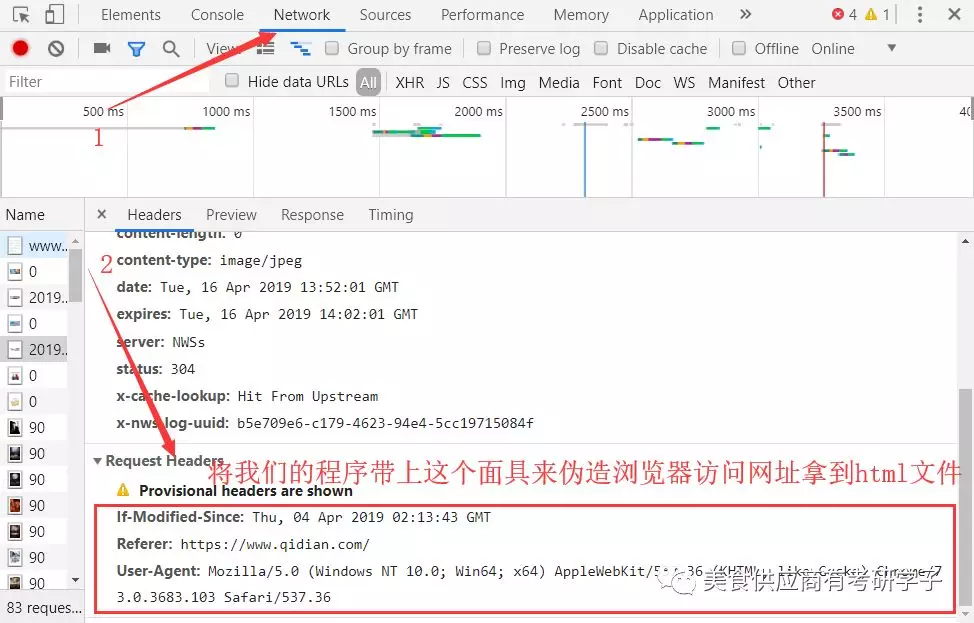
然后让我们获取的html文件z整理成xml文件,,为了后面的方便定位标签属性.

有人就会问了,我整理好了怎么去获取改文件的超链接呢对吧,别慌这就讲来;
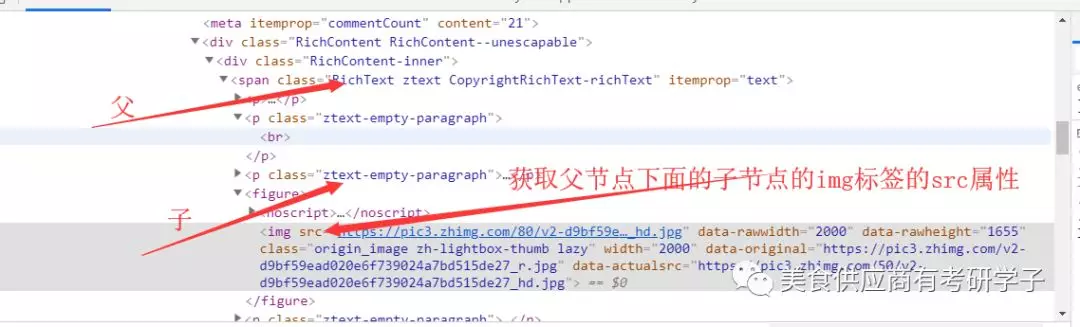
看到网站的结构是这样的那么对应的爬取的路线就有了,

上面形成的xml对应的属性结构去查询他的对应的节点,这样我们就很容易会爬取到对应的图片的连接对吧....

这个是上面文件爬取到的图片(一部分):

把获取到的连接上面的代码会进行自动的下载,,这样就很容易会完成网站上的批量图片下载...你们也可以百度网盘下载:
起点的小说源代码附加
1 import requests 2 3 from lxml import etree 4 5 import os 6 7 8 9 # 设计模式 -- 面向对象 10 11 class Spider(object): 12 13 def start_request(self): 14 15 # 1. 请求网站拿到HTML源代码,抽取小说名、小说链接 创建文件夹 16 17 response = requests.get("https://www.qidian.com/all") 18 19 xml = etree.HTML(response.text) # 整理成xml文档对象 20 21 Bigtit_list = xml.xpath('//div[@class="book-mid-info"]/h4/a/text()') # 抽取小说名 22 23 Bigsrc_list = xml.xpath('//div[@class="book-mid-info"]/h4/a/@href') # 抽取小说链接 24 25 for Bigtit, Bigsrc in zip(Bigtit_list, Bigsrc_list): 26 27 if os.path.exists(Bigtit) == False: 28 29 os.mkdir(Bigtit) 30 31 self.next_file(Bigtit, Bigsrc) 32 33 34 35 def next_file(self, Bigtit, Bigsrc): 36 37 # 2. 请求小说拿到HTML源代码,抽取章名、章链接 38 39 response = requests.get("http:" + Bigsrc) 40 41 xml = etree.HTML(response.text) # 整理成xml文档对象 42 43 Littit_list = xml.xpath('//ul[@class="cf"]/li/a/text()') # 抽取章名 44 45 Litsrc_list = xml.xpath('//ul[@class="cf"]/li/a/@href') # 抽取章链接 46 47 for Littit, Litsrc in zip(Littit_list, Litsrc_list): 48 49 self.finally_file(Bigtit, Littit, Litsrc) 50 51 52 53 def finally_file(self, Bigtit, Littit, Litsrc): 54 55 # 3. 请求文章拿到HTML源代码,抽取文章内容,保存数据 56 57 response = requests.get("http:" + Litsrc) 58 59 xml = etree.HTML(response.text) # 整理成xml文档对象 60 61 content = " ".join(xml.xpath('//div[@class="read-content j_readContent"]/p/text()')) 62 63 fileName = Bigtit + "\" + Littit + ".txt" 64 65 print("正在保存小说文件:" + fileName) 66 67 with open(fileName, "w", encoding="utf-8") as f: 68 69 f.write(content) 70 71 72 73 74 75 spider = Spider() 76 77 spider.start_request() 78 79 :
扫码公众号回复“爬取小说网站”、“语音播报”获取源码
