scrapy是python中数据抓取的框架。简单的逻辑如下所示
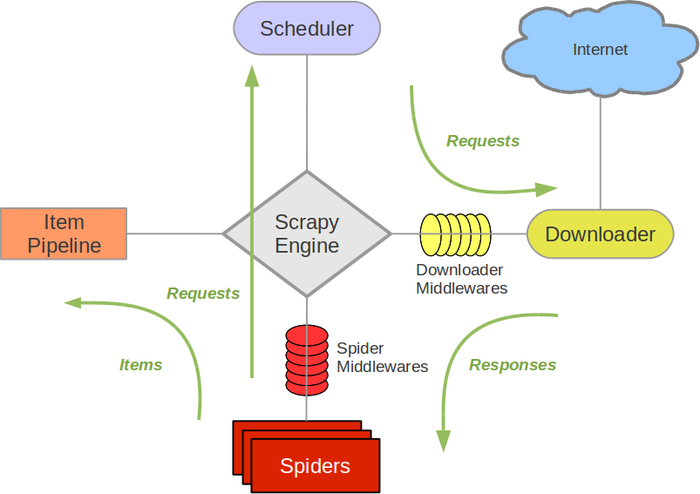
scrapy的结构如图所示,包括scrapy engine、scheduler、downloader、spider、item pipeline。
scrapy engine:引擎,是负责scheduler、downloader、spider、item pipeline之间的消息的传递等等
scheduler:调度器,是负责接受scrapy engine 的request请求,并将request进行整理排列,入队,等待scrapy engine来请求时,交给引擎
downloader:下载器,是用来下载scrapy engine的请求,并将response返回给spider。
spider:爬虫,是将downloader的response,由spider分析并提取item所要抓取的数据,并将所要跟进的url再次交给scrapy engine,再次进入scheduler。
item pipeline:项目管道,是将spider中提取到的数据,进行处理,存储。
还有两个:
download middlewares:下载中间件,是一个可以扩展的下载功能的组件,介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应
spider middlewares:spider的中间件:是一个可以扩展和操作引擎和spider中间通信的功能组件(比如进入spider的response,和从spider传出去的request),介于Scrapy引擎和蜘蛛之间的钩子框架,主要工作是处理蜘蛛的响应输入和请求输出
这俩当前还没有试过~
经过:
1.scrapy engine获取到spider要获取的第一个url
2.scrapy engine将要获取的url给scheduler,并将url入队,整理,并将处理好的request请求返回
3.scrapy engine将处理好的request给downloader,通过downloader下载数据,如果下载失败,会将下载失败的结果告诉scrapy engine,然后会让scrapy engine等会再次请求下载。
4.scrapy engine获取到downloader下载的数据,并且将数据给spider,经由spider进行数据处理,spider将需要跟进的request交给scrapy engine,将处理的结果返回给item pipeline
5.item pipeline将spider反悔的结果进行去重,持久化,写入数据库等操作。
只有当scheduler中没有任何request了,整个过程才会停止。