因为采用Apache Tika解析网页文件时产生乱码问题,所以后来仔细看了一下Apache Tika源码
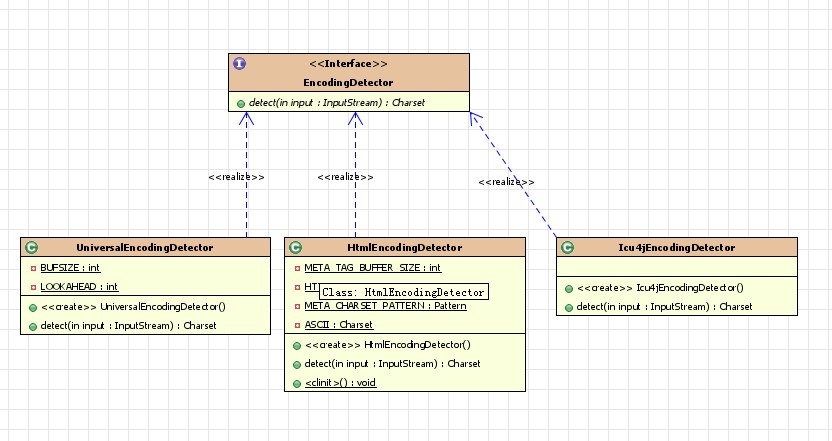
先浏览一下tika编码识别的相关接口和类的UML模型
下面是编码识别接口,EncodingDetector.java
public interface EncodingDetector { /** * Detects the character encoding of the given text document, or * <code>null</code> if the encoding of the document can not be detected. * <p> * If the document input stream is not available, then the first * argument may be <code>null</code>. Otherwise the detector may * read bytes from the start of the stream to help in encoding detection. * The given stream is guaranteed to support the * {@link InputStream#markSupported() mark feature} and the detector * is expected to {@link InputStream#mark(int) mark} the stream before * reading any bytes from it, and to {@link InputStream#reset() reset} * the stream before returning. The stream must not be closed by the * detector. * <p> * The given input metadata is only read, not modified, by the detector. * * @param input text document input stream, or <code>null</code> * @param metadata input metadata for the document * @return detected character encoding, or <code>null</code> * @throws IOException if the document input stream could not be read */ Charset detect(InputStream input, Metadata metadata) throws IOException; }
编码识别接口EncodingDetector的实现类有三,分别是HtmlEncodingDetector,UniversalEncodingDetector,和Icu4jEncodingDetector
从三者的名称基本可以看出他们的功能或所用的组件,Tika默认的网页编码识别是存在问题的,当解析网页文件时,在网页的html元素里面编码有误的时候就会产生乱码。
HtmlEncodingDetector类的源码如下:
public class HtmlEncodingDetector implements EncodingDetector { // TIKA-357 - use bigger buffer for meta tag sniffing (was 4K) private static final int META_TAG_BUFFER_SIZE = 8192; private static final Pattern HTTP_EQUIV_PATTERN = Pattern.compile( "(?is)<meta\\s+http-equiv\\s*=\\s*['\\\"]\\s*" + "Content-Type['\\\"]\\s+content\\s*=\\s*['\\\"]" + "([^'\\\"]+)['\\\"]"); private static final Pattern META_CHARSET_PATTERN = Pattern.compile( "(?is)<meta\\s+charset\\s*=\\s*['\\\"]([^'\\\"]+)['\\\"]"); private static final Charset ASCII = Charset.forName("US-ASCII"); public Charset detect(InputStream input, Metadata metadata) throws IOException { if (input == null) { return null; } // Read enough of the text stream to capture possible meta tags input.mark(META_TAG_BUFFER_SIZE); byte[] buffer = new byte[META_TAG_BUFFER_SIZE]; int n = 0; int m = input.read(buffer); while (m != -1 && n < buffer.length) { n += m; m = input.read(buffer, n, buffer.length - n); } input.reset(); // Interpret the head as ASCII and try to spot a meta tag with // a possible character encoding hint String charset = null; String head = ASCII.decode(ByteBuffer.wrap(buffer, 0, n)).toString(); Matcher equiv = HTTP_EQUIV_PATTERN.matcher(head); if (equiv.find()) { MediaType type = MediaType.parse(equiv.group(1)); if (type != null) { charset = type.getParameters().get("charset"); } } if (charset == null) { // TIKA-892: HTML5 meta charset tag Matcher meta = META_CHARSET_PATTERN.matcher(head); if (meta.find()) { charset = meta.group(1); } } if (charset != null) { try { return CharsetUtils.forName(charset); } catch (Exception e) { // ignore } } return null; } }
如果需要正确的编码,需要改写
public Charset detect(InputStream input, Metadata metadata)方法
接下来分析另外一个重要的实现类UniversalEncodingDetector,从它的名称基本可以猜测到时采用的juniversalchardet组件,其代码如下:
public class UniversalEncodingDetector implements EncodingDetector { private static final int BUFSIZE = 1024; private static final int LOOKAHEAD = 16 * BUFSIZE; public Charset detect(InputStream input, Metadata metadata) throws IOException { if (input == null) { return null; } input.mark(LOOKAHEAD); try { UniversalEncodingListener listener = new UniversalEncodingListener(metadata); byte[] b = new byte[BUFSIZE]; int n = 0; int m = input.read(b); while (m != -1 && n < LOOKAHEAD && !listener.isDone()) { n += m; listener.handleData(b, 0, m); m = input.read(b, 0, Math.min(b.length, LOOKAHEAD - n)); } return listener.dataEnd(); } catch (IOException e) { throw e; } catch (Exception e) { // if juniversalchardet is not available return null; } finally { input.reset(); } } }
这里编码识别 是通过UniversalEncodingListener类,该类实现了CharsetListener接口,该接口是juniversalchardet组件的接口,代码如下:
package org.mozilla.universalchardet; public interface CharsetListener { public void report(String charset); }
该接口待实现的只有void report(String charset)方法
UniversalEncodingListener类持有私有成员
private final UniversalDetector detector = new UniversalDetector(this);
这里的this即为其本身,我们可以猜测到detector对象是通过回调CharsetListener接口的void report(String charset)方法传回编码类型字符串的
可以看到UniversalDetector类里面自带的测试代码:
public static void main(String[] args) throws Exception { if (args.length != 1) { System.out.println("USAGE: java UniversalDetector filename"); return; } UniversalDetector detector = new UniversalDetector( new CharsetListener() { public void report(String name) { System.out.println("charset = " + name); } } ); byte[] buf = new byte[4096]; java.io.FileInputStream fis = new java.io.FileInputStream(args[0]); int nread; while ((nread = fis.read(buf)) > 0 && !detector.isDone()) { detector.handleData(buf, 0, nread); } detector.dataEnd(); }
如果我们的程序采用UniversalEncodingDetector类来识别文件编码,代码怎么实现呢?下面是调用方法:
public static void main(String[] args) throws IOException, TikaException { // TODO Auto-generated method stub File file=new File("[文件路径]"); InputStream stream=null; try { stream=new FileInputStream(file); EncodingDetector detector=new UniversalEncodingDetector(); Charset charset = detector.detect(new BufferedInputStream(stream), new Metadata()); System.out.println("编码:"+charset.name()); } finally { if (stream != null) stream.close(); } }
第三个类是Icu4jEncodingDetector,从名称可以看出是采用的IBM的Icu4j组件,代码如下:
public class Icu4jEncodingDetector implements EncodingDetector { public Charset detect(InputStream input, Metadata metadata) throws IOException { if (input == null) { return null; } CharsetDetector detector = new CharsetDetector(); String incomingCharset = metadata.get(Metadata.CONTENT_ENCODING); String incomingType = metadata.get(Metadata.CONTENT_TYPE); if (incomingCharset == null && incomingType != null) { // TIKA-341: Use charset in content-type MediaType mt = MediaType.parse(incomingType); if (mt != null) { incomingCharset = mt.getParameters().get("charset"); } } if (incomingCharset != null) { detector.setDeclaredEncoding(CharsetUtils.clean(incomingCharset)); } // TIKA-341 without enabling input filtering (stripping of tags) // short HTML tests don't work well detector.enableInputFilter(true); detector.setText(input); for (CharsetMatch match : detector.detectAll()) { try { return CharsetUtils.forName(match.getName()); } catch (Exception e) { // ignore } } return null; } }
最关键的类是CharsetDetector,这里暂不进一步分析这个类了
下面转帖网上的一篇博文
《使用ICU4J探测文档编码》
http://blog.csdn.net/cnhome/article/details/6973343
曾经使用过这个东东,还是不错的,中国人的一篇论文,最早的时候好像是在哪个开源浏览器里。
网页源码的编码探测一般有两种方式,一种是通过分析网页源码中Meta信息,比如contentType,来取得编码,但是某些网页不的contentType中不含任何编码信息,这时需要通过第二种方式进行探测,第二种是使用统计学和启发式方法对网页源码进行编码探测。ICU4J就是基于第二种方式的类库。由IBM提供。
下面的例子演示了一个简单的探测过程。
package com.huilan.dig.contoller; import java.io.IOException; import java.io.InputStream; import com.ibm.icu.text.CharsetDetector; import com.ibm.icu.text.CharsetMatch; /** * 本类使用ICU4J包进行文档编码获取 * */ public class EncodeDetector { /** * 获取编码 * @throws IOException * @throws Exception */ public static String getEncode(byte[] data,String url){ CharsetDetector detector = new CharsetDetector(); detector.setText(data); CharsetMatch match = detector.detect(); String encoding = match.getName(); System.out.println("The Content in " + match.getName()); CharsetMatch[] matches = detector.detectAll(); System.out.println("All possibilities"); for (CharsetMatch m : matches) { System.out.println("CharsetName:" + m.getName() + " Confidence:" + m.getConfidence()); } return encoding; } public static String getEncode(InputStream data,String url) throws IOException{ CharsetDetector detector = new CharsetDetector(); detector.setText(data); CharsetMatch match = detector.detect(); String encoding = match.getName(); System.out.println("The Content in " + match.getName()); CharsetMatch[] matches = detector.detectAll(); System.out.println("All possibilities"); for (CharsetMatch m : matches) { System.out.println("CharsetName:" + m.getName() + " Confidence:" + m.getConfidence()); } return encoding; } }