Map:java.util.Map接口
*Map称为查找表,该数据结构体现的样子是一个“多行两列”的表格,左列
*称为key,右列称为value
*Map总是根据key查找对应的value
*存储元素也要求key-value成对存入
*常用的实现类:java.util.HashMap 散列表
* HashMap是基于散列算法实现的Map,是当今世界上最快的查询结构、
若只获取value值,则用get()
删除的remove()方法是成对删除,且返回值是被删除的value值
package map;
import java.util.HashMap;
import java.util.Map;
/**
* java.util.Map接口
*Map成为查找表,该数据结构体现的样子是一个“多行两列”的表格,左列
*称为key,右列称为value
*Map总是根据key查找对应的value
*存储元素也要求key-value成对存入
*常用的实现类:java.util.HashMap 散列表
* HashMap是基于散列算法实现的Map,是当今世界上最快的查询结构
* @author TEDU
*
*/
public class MapDemo1 {
public static void main(String[] args) {
Map<String,Integer> map=new HashMap<String,Integer>();
map.put("数学", 100);
map.put("物理", 97);
map.put("化学", 99);
map.put("英语", 20);
map.put("语文", 98);
Integer a=map.put("生物", 97);
System.out.println(a);
System.out.println(map);
//{物理=97, 生物=97, 数学=100, 化学=99, 语文=98, 英语=20}
//map的输出顺序与存入顺序不一样,
/*
* 如果向map中存入的键值对的key值已经存在map中,则不会再继续加入
* 而是替代之前的value值。如果向map中加入的键值对已经存在,用value
* 接收返回值,则返回值为替代的value值,如果之前没有这个元素,则返回null。
*
* 对于value是包装类的情况,不能直接用基本类型接收返回值,因为会触发
* 自动拆箱特性:
* int n=map.put("语文",99);
* 下面的代码编译后会改为:
* int n=map.put("语文",99).inValue();
*
* 若key在Map中不存在,则返回值为null,若拆箱则会引发空指针异常
*/
//多少行
int size=map.size();
System.out.println(size);
//查看数学的成绩
Integer math=map.get("数学");
System.out.println("数学"+math);
/*
* 删除元素
* 删除当前map中给定key值对应的这组键值对
* 返回值为该key所对应的value。若给定的key在key中不存在
* 则返回null
*/
Integer an=map.remove("数学");
System.out.println(an);
//containsKey()与containsValue()判断是否含有指定的key和value
boolean key=map.containsKey("化学");
System.out.println("是否含有key:"+key);
boolean value=map.containsValue(98);
System.out.println("是否含有value:"+value);} }
Map的遍历:
3种方法,分别是:
1.遍历所有的键值对
2.遍历所有的key值
3.遍历所有的value值
package map;
/**
* Map的三种遍历
* 1:遍历所有的key
* 2:遍历所有的key-value对
* 3:遍历所有的value(相对不常用)
*
*/
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
import java.util.Map.Entry;
import java.util.Set;
public class MapDemo03 {
public static void main(String[] args) {
Map<String,Integer> map=new HashMap<String,Integer>();
map.put("数学", 100);
map.put("物理", 97);
map.put("化学", 99);
map.put("英语", 20);
map.put("语文", 98);
System.out.println(map);
/*
* 遍历所有的key值
* Set keySet()
* 将当前Map中所有的key存入一个集合后返回
* 遍历这个set集合等于遍历多有的key
*/
Set<String>keySet=map.keySet();
for(String key:keySet){
System.out.println("key:"+key);
}
/*
* 遍历每一组键值对
* 在Map接口中定义可一个内部接口
* java.util.Map.Entry
* Entry的没一个实例表示当前map中的
* 一组键值对,提供了两个常用的方法:
* K getKey() :获取key值
* V getValue():获取value值
* 不同的Map实现类都实现了Entry,并用实现类的
* 每一个实例表示一个具体的键值对。
*
* Set<Entry> entrySet()
* 刚方法会将Map中所有的键值对存入一个集合后返回
*/
Set<Entry<String,Integer>>entrySet=map.entrySet();
for(Entry <String,Integer>e:entrySet){
Integer value=e.getValue();
String key=e.getKey();
System.out.println(key+":"+value);
}
/*
* 遍历所有的value
* Collection values()
* 将当前Map中所有的value以一个集合的形式返回
* 因为set集合中不能有重复元素,故不叫valueSet
*/
Collection <Integer>values=map.values();
for(Integer e:values){
System.out.println(e);
}
}
}
Map特点的缘由:
1,为什么用了一维数组:数组存储区间是连续的,占用内存严重,故空间复杂的很大。但数组的二分查找时间复杂度小,为O(1);数组的特点是:寻址容易,插入和删除困难
2,为什么用了链表:链表存储区间离散,占用内存比较宽松,故空间复杂度很小,但时间复杂度很大,达O(N)。链表的特点是:寻址困难,插入和删除容易
而HashMap是两者的结合,用一维数组存放散列地址,以便更快速的遍历;用链表存放地址值,以便更快的插入和删除!
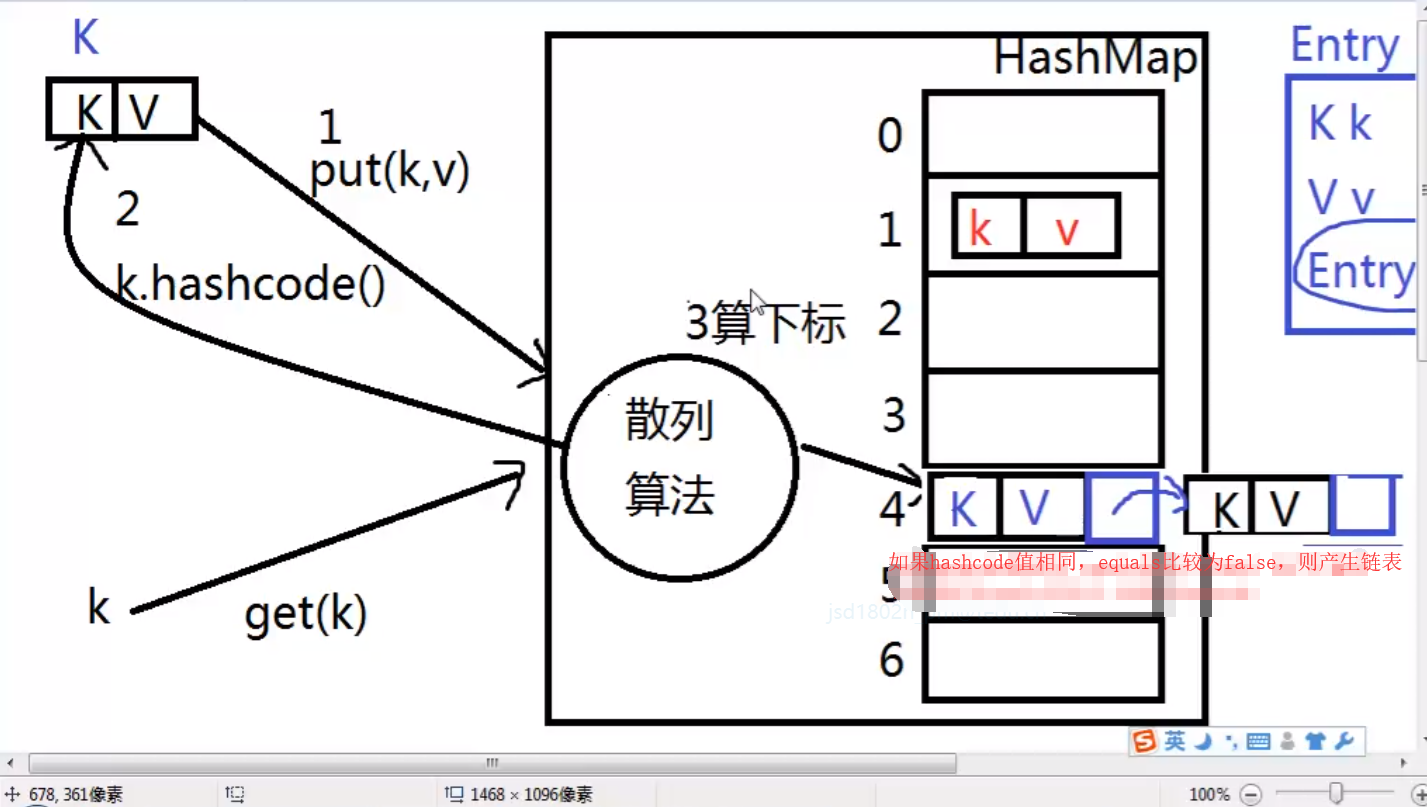
如果两个对象相等(equal),它们的hashcode一定相同;
如果两个对象有相同的hashcode,它们不一定相等(equal);

当Map存入的数据存入超过3/4时,Map会进行重新散列rehash,因为散列算法计算元素下标与key值和数组的长度有关,
这样可以有效的避免数组扩容后元素丢失。
package map;
/**
* HashMap内部由数组保存键值对,存储元素时根据key的hashcode值
* 计算数组下标,并将键值对存入,获取时也根据该值计算数组下标,并将键值对存入,
* 获取时也根据该值找到该元素。所以HashMap根据这个方式避免了查找
* 元素时对数组的遍历操作,所以其不受元素的多少而影响查询性能。
*
* 由于key的hashcode决定这键值对HasMap中数组 下标位置,而equals
* 方法决定着key是否重复。所以这两个方法要妥善重写,
* 当遇到两个key的shascode值一样。但是equals比
* 较不为true的情况时,会出现链表。链表会降低查询性能。应尽量避免
*
* hashcode与equals方法时定义在Object中的,所有类都具有
* ,java提供的类需要重写equals或hashcode是
* 必须遵循一下原则:
* 1:成对重写,当我们需要重写一个类的equals方法时
* 就应当连同重写hashcode方法。
* 2:一致性,当两个对象equals比较为true时,hashcode值应该相等
* ,反之虽然不是必须的,但是应当保证当两个对象hashcode方法返回值相等
* 时,equals方法比较为true。否则会在HashMap中出现链表
* 3:稳定性,当参与equals比较的属性没有发生变化的情况下,多
* 次调用hashcode方法返回的数字不应当有变化
* @author TEDU
*
*/
public class Key {
private int x;
private int y;
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + x;
result = prime * result + y;
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Key other = (Key) obj;
if (x != other.x)
return false;
if (y != other.y)
return false;
return true;
}
}