参考资料:自己debug
首先,我报错的问题的文本是:RuntimeError: CUDA error: device-side assert triggered以及
Assertion `input_val >= zero && input_val <= one` failed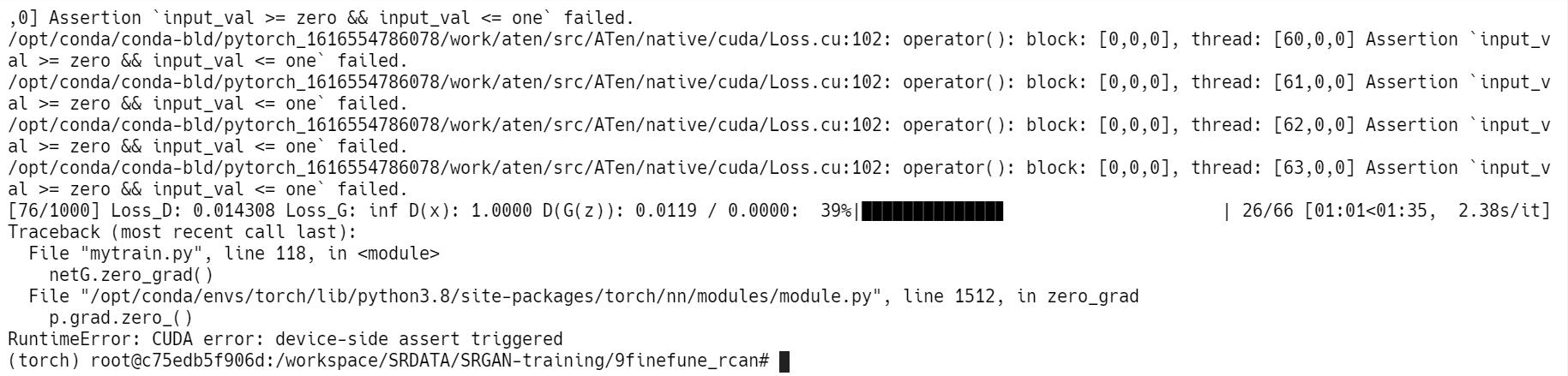
把这两个文本放在前面以便搜索引擎检索。下面说一下我的解决方案,因为问题解决过程中我没有逐步截图,所以有些步骤只能文字描述。
RCAN是超分辨率恢复领域的一个深度残差网络,但是它的代码却是很旧的了,基于EDSR和Pytorch<1.2的框架。所以我就将它的model移植到了自己的框架下,结果在训练过程中突然报了上面这个错误。
并且,这个报错不是在网络训练一开始就发生的,而是训着训着突然报错。这让我百思不得解,思考历程如下:
首先,根据报错的文字描述,是在源代码的 /src/ATen/native/cuda/Loss.cu:102,打开github上pytorch的源码,找到这一部分: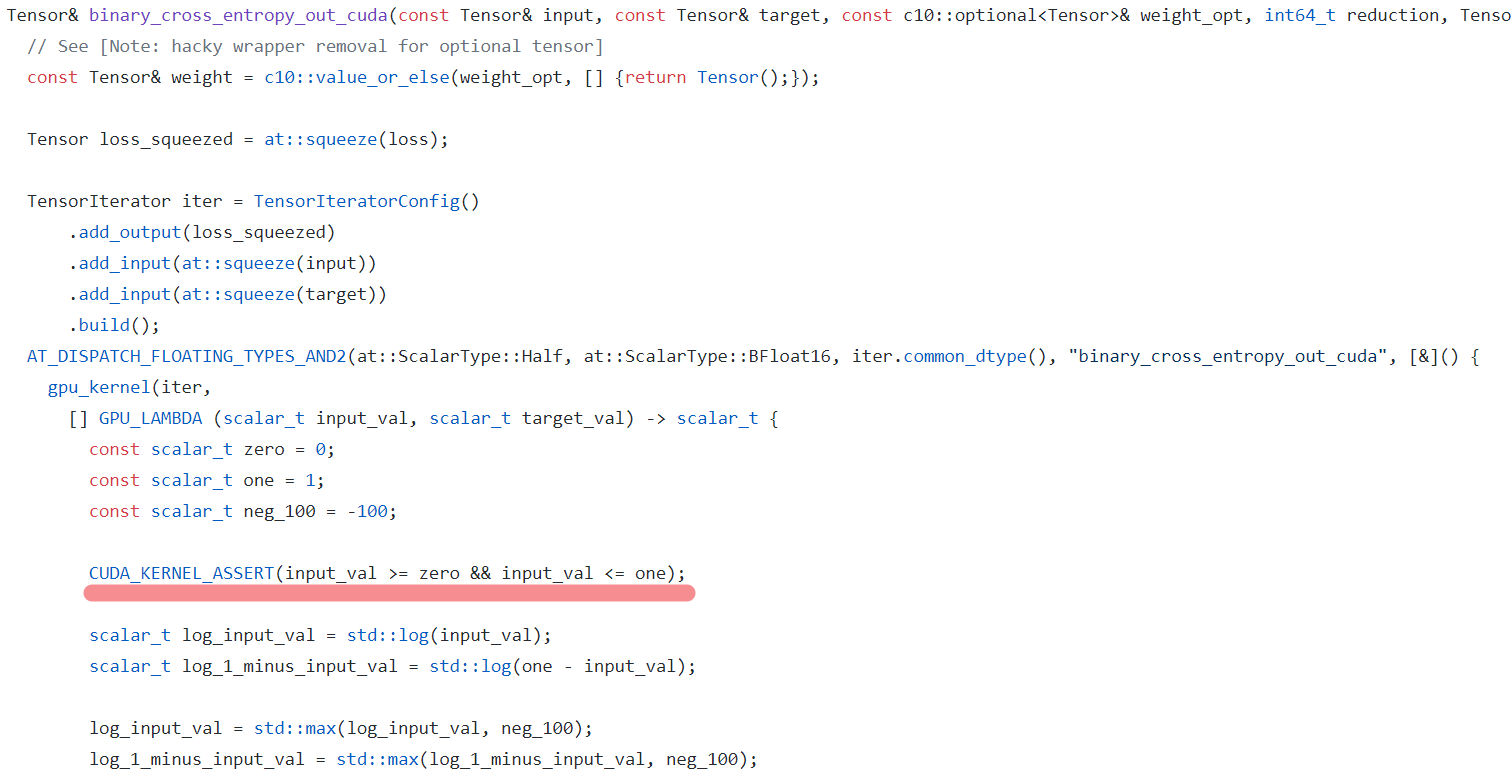
原来如此,这个断言原来是发生在binary_cross_entropy_out_cuda()内,也就是在使用nn.BCELoss的时候报了错。
回顾一下我的源码,我是让output和target进行一个BCELoss。但是,在我的model(记为modelB)内,最后一层是sigmoid,也就是说,我的网络保证了输出值一定是在[0, 1]之间的!!那么,凭什么说我的值不在这个区间?是Pytorch犯病了吗?
Well,没有别的办法,我在源码中添加了print语句打印model的输出,看看它是否真的按照预期输出值均在[0, 1]。一看吓一跳,一开始的时候,输出值十分正常,并且都在[0, 1]之间。但是到达某一个时间节点,网络的输出突然就变成满屏的nan也就是无穷值!这就奇了怪了,因为众所周知,卷积神经网络里面的操作都是“有限的”,当输入有限的时候输出一定是有限的。等等,当输入有限的时候。我想当然地认为这个输入是有限的,但是输入值到底是不是这样呢。(此处输入是modelA的输出)
有了这种想法,我又打印了modelA(其实就是RCAN)的输出,结果发现和modelB一样,在某个时间节点,输出值突然变成了nan。
问题找到了,但好像又陷入了僵局。RCAN也是一个卷积神经网络啊,里面也没有log这种会产生无穷量的操作,那么问题到底出在了哪里?
我灵光一闪突然想到,RCAN的网络结构里面,貌似有一些网络层时不需要训练和优化的。但是在我的源码里,优化器的代码是这样的:
optimizerG = optim.Adam(netG.parameters())
也就是将RCAN网络中的所有参数都交给了OptimizerG给hook住了。那么,会不会是优化器优化了一些固定的不该优化的网络参数,导致网络异常。翻看RCAN的源码,找到蛛丝马迹,源码中有这样一段:
def make_optimizer(args, my_model): trainable = filter(lambda x: x.requires_grad, my_model.parameters()) if args.optimizer == 'SGD': optimizer_function = optim.SGD kwargs = {'momentum': args.momentum} elif args.optimizer == 'ADAM': optimizer_function = optim.Adam kwargs = { 'betas': (args.beta1, args.beta2), 'eps': args.epsilon } elif args.optimizer == 'RMSprop': optimizer_function = optim.RMSprop kwargs = {'eps': args.epsilon} kwargs['lr'] = args.lr kwargs['weight_decay'] = args.weight_decay return optimizer_function(trainable, **kwargs)
真该死,RCAN的源码好像在这里的第一行过滤了需要训练的参数和不需要训练的参数。而我的代码却没有干这件事。那么,我就直接用原作者的代码把,试一试:

咳,训练效果非常不理想。但是却再也没有报过同样的错误,看来,问题已经被解决!!!
总结一下:
1. 在Pytorch进行BCELoss的时候,需要输入值都在[0, 1]之间,如果你的网络的最后一层不是sigmoid,你需要把BCELoss换成BCEWithLogitsLoss,这样损失函数会替你做Sigmoid的操作。
2. 神经网络的输入和输出一般都是有限量,如果你确认你的网络是好的,不妨查看一下网络的输入是不是已经变成了nan
3. 神经网络的一些网络层是不需要训练的,此时你需要告诉优化器这件事,不然optim会做出一些蠢事让输出值变成nan