AVL树
-
AVL树定义:红黑树是一颗二叉搜索树,特别的是一棵保持高度平衡的二叉搜索树
-
AVL树特点:
-
每个结点的左右子树的高度之差的绝对值(平衡因子)最多为1
-
-
AVL树插入:
-
说明:新增节点的平衡因子是0,新增节点是右节点,父节点平衡因子+1,新增节点是左节点,父节点平衡因子-1
-
插入新增节点后,父节点平衡因子变为0,说明节点插入在较矮的子树上,平衡没被破坏,高度也没变化,直接插入无需做任何处理
-
插入新增节点后,父节点平衡因子变为+1或是-1,说明插入前节点的平衡因子是0,平衡没被破坏,但是高度+1.需要向上调整
-
插入新增节点后,父节点平衡因子变为+2或是-1,说明节点插入在较高的子树上,平衡被破坏,根据下面4中情况调整
-
LL型:右旋
-
LR型:左旋变成LL型,右旋
-
RR:左旋
-
RL:右旋变成RR型,左旋
-
调整后恢复平衡,且高度没有变化
-
-
-
AVL树删除:
-
删除节点有两个孩子节点:中序遍历,找出删除节点的前驱或是后继节点,交换二者的数据,然后删除节点变成下面两种情况中的一种
-
删除节点只有一个孩子节点:孩子节点替代删除的节点,向上调整
-
删除节点无孩子节点:直接删除目标节点,向上调整
-
向上调整:
-
删除后平衡因子不变,不做处理
-
删除左子树的节点,若失去平衡,令t=右子树,若t的左子树高度>t的右子树高度,相当于在右子树的左子树插入节点,执行RL操作,否则执行RR操作
-
删除右子树的节点,若失去平衡,令t=左子树,若t的左子树高度>t的右子树高度,相当于在左子树的左子树插入节点,执行LL操作,否则执行LR操作
-
-
红黑树
-
红黑树定义:红黑树是一颗二叉搜索树,特别的是一棵保持一定平衡的二叉搜索树
-
红黑树的特点:
-
节点是红色或黑色
-
根节点是黑色
-
每个叶节点(NULL节点,无实际意义,只有颜色属性)是黑色
-
每个红色节点的两个子节点都是黑色(即:不能有两个连续的红色节点)
-
从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点
-
-
红黑树的5点性质保证了整颗树中最长路径不大于最短路径的两倍,从而使得整棵树基本保持平衡
-
红黑数的插入:
-
插入节点标记为红色(如果是黑的,就会破坏性质5)
-
插入节点的父节点为黑色,直接插入就行
-
插入节点的父节点为红色:
-
插入节点的叔父节点为红色,将插入节点和叔父节点变为黑色,父节点变为红色,向上调整只到根节点
-
插入节点的叔父节点为黑色:
-
LL型:右旋,变色(不需要向上调整)
-
RL型:右旋变成LL型
-
RR型:左旋,变色(不需要向上调整)
-
LR型:左旋变成RR型
-
-
-
-
红黑树删除:
-
删除节点有两个孩子节点:中序遍历,找出删除节点的前驱或是后继节点,交换二者的数据,不交换颜色属性,然后删除节点变成下面两种情况中的一种
-
删除节点只有一个孩子节点:
-
删除节点是红色节点:直接删除
-
删除节点是黑色节点:
-
孩子节点是红色节点:删除节点后,将孩子节点变黑
-
孩子节点是黑色节点:不存在这种情况,违反性质5
-
-
-
删除节点无孩子节点
-
删除节点是红色:直接删除
-
删除节点是黑色:
-
删除节点是左孩子
-
兄弟节点是红色:父节点和兄弟节点的颜色互换,然后左旋,变成兄弟节点是黑色的情况
-
兄弟节点是黑色:
-
远侄节点是红色(近侄颜色没要求):父节点和兄弟节点的颜色互换,然后左旋,最后把操作前的远侄节点变成黑色,删除掉需要目标节点即可
-
远侄节点是黑色:
-
近侄节点为黑色:
-
父节点为红色:父亲节点改成黑色,将兄弟节点改成红色,然后删目标节点
-
父节点为黑色:将兄弟节点S的颜色改成红色,删除目标节点,以父节点为起点,向上调整
-
-
近侄节点为红色:右旋,交换兄弟节点和近侄节点的颜色,变成远侄为红色节点的情况
-
-
-
-
删除节点是右孩子
-
兄弟节点是红色:父节点和兄弟节点的颜色互换,然后左旋,变成兄弟节点是黑色的情况
-
兄弟节点是黑色:
-
远侄节点是红色:父节点和兄弟节点的颜色互换,然后左旋,最后把操作前的远侄节点变成黑色,删除掉需要目标节点即可
-
远侄节点是黑色:
-
近侄节点为黑色:
-
父节点为红色:父亲节点改成黑色,将兄弟节点改成红色,然后删目标节点
-
父节点为黑色:将兄弟节点S的颜色改成红色,删除目标节点,以父节点为起点,向上调整
-
-
近侄节点为红色:左旋,交换兄弟节点和近侄节点的颜色,变成远侄为红色节点的情况
-
-
-
-
-
-
-
红黑树删除的口诀:先看待删除的节点的颜色,再看兄弟节点的颜色,再看侄子节点的颜色(侄子节点先看远侄子再看近侄子),最后看父亲节点的颜色
RB-tree和iterator之间的关系
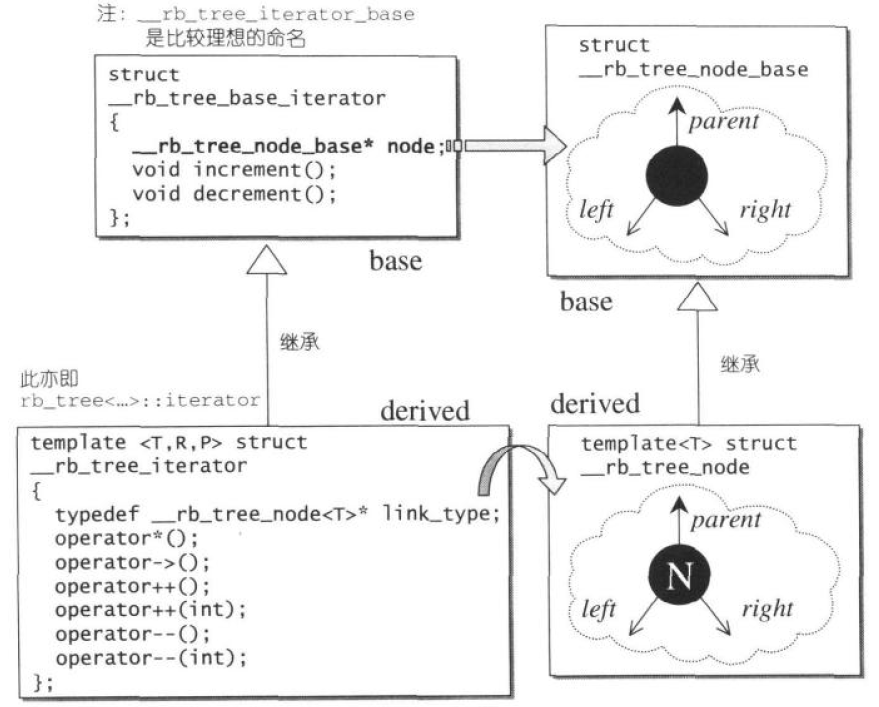
typedef bool __rb_tree_color_type; const __rb_tree_color_type _rb_tree_red = false; const __rb_tree_color_type _rb_tree_black = true; struct __rb_tree_node_base { typedef __rb_tree_color_type color_type; typedef __rb_tree_node_base* base_ptr; color_type color; base_ptr parent; // 指向父节点 bsae_ptr left; // 指向左孩子 base_ptr right; // 指向右孩子 static base_ptr mimimum(base_ptr x) { while(x->left != 0) { x = x->left; } return x; } static base_ptr maximum(base_ptr x) { while(x->right != 0) { x = x->right; } return x; } }
template <class Value> struct __rb_tree_node : public __rb_tree_node_base { typedef __rb_tree_node<Value>* link_type; Value value_field; }
RB-tree迭代器
struct __rb_tree_base_iterator { typedef __rb_tree_node_base::base_ptr base_ptr; typedef bidirectional_iterator_tag iterator_category; typedef ptrdiff_t difference_type; base_ptr node; // 指向容器中的数据 // 找出当前节点的下一个节点,理解成在二叉搜索树中的处理 void increment() { // 当前节点的右节点存在,就寻找右节点中最小的值(一直向左走,走到底就是最小值) if(node->right != 0) { node = node->right; while(node->left != 0) { node = node->left; } } else { // 当前节点的右节点不存在,就寻找第一个父节点且父节点的右孩子不是自己的节点,就是下一个节点 base_ptr y = node->parent; while(node == y->right) { node = y; y = node->parent; } if(node->right != y) { node = y; } } } // 寻找当前节点的前一个节点,理解成在二叉搜索树中的处理 void decrement() { // 特殊设计,链表为空时,有一个门卫节点,三个指针全部指向自己,且颜色为红,单独处理 if(node->color == __rb_tree_red && node->parent->parent == node) { node = node->right; } else if(node->left != 0) { // 当前节点存在左节点,寻找左节点中的最大值(一直向右走,走到底就是最大值) node = node->left; while(node->right != 0) { node = node->right; } } else { // 当前节点的左节点不存在,就寻找第一个父节点且父节点的左孩子不是自己的节点,就是上一个节点 base_ptr y = node->parent; while(node == y->left) { node = y; y = node->parent; } node = y; } } }
template <class Value, class Ref, class Ptr> struct __rb_tree_iterator : public __rb_tree_base_iterator { typedef Value value_type; typedef Ref reference; typedef Ptr pointer; typedef __rb_tree_iterator<Value, Value&, Value*> iterator; typedef __rb_tree_iterator<Value, const Value&, const Value*> const_iterator; typedef __rb_tree_iterator<Value, Ref, Ptr> self; typedef __rb_tree_node<Value>* link_type; __rb_tree_iterator() {} __rb_tree_iterator(link_type x) { node = x} __rb_tree_iterator(const iterator& it) { node = it.node} reference operator*() const { return link_type(node)->value_field; } pointer operator->() const { return &(operaotr*()); } self& operator++() { increment(); return *this; } self operator++(int) { self temp = *this; increment(); return temp; } self& operator--() { decrement(); return *this; } self operator--(int) { self temp = *this; decrement(); return temp; } }
RB-tree数据结构
template <class Key, class Value, class KeyOfValue, class Compare, class Alloc = alloc> class rb_tree { protect: typedef void* void_pointer; typedef __rb_tree_node_base* base_ptr; typedef __rb_tree_node<Value> tr_tree_node; typedef simple_alloc<rb_tree_node, Alloc> rb_tree_node_allocator; typedef __rb_tree_color_type color_type; public: typedef Key key_type; typedef Value value_type; typedef const value_type* const_pointer; typedef value_type& reference; typedef const value_type& const_reference; typedef rb_tree_node* link_type; typedef size_t size_type; typedef ptrdiff_t difference_type; protect: link_type get_node() { return rb_tree_node_allocator::allocate(); } void put_node(link_type p) { rb_tree_node_allocator::dealocate(p); } link_type create_node(const value_type& x) { link_type tmp = get_node(); construct(&tmp->value_field, x); return tmp; } void destroy_node(link_type p) { destroy(&p->value_field) put_node(p) } protected: size_type node_count; // 记录节点总个数 link_type header; // 门卫节点 Compare key_compare; // 比较key值大小的函数 link_type& root() const { return (link_type&)header->parent; } link_type& leftmost() const { return (link_type&)header->left; } link_type& rightmost() const { return (link_type&)header->right; } static link_type minimun(link_type x) { return (link_type) __rb_tree_node_base::minimun(x); } static link_type maximun(link_type x) { return (link_type) __rb_tree_node_base::maximun(x); } public: typedef __rb_tree_iterator<value_type, reference, pointer> iterator; private: void init() { header = get_node(); color(header) = __rb_tree_red; // 初始化时都指向自己 root() = 0; leftmost() = header; rightmost() = header; } public: rb_tree(const Compare& comp = Compare()) : node_count(0), key_compare(comp) { init(); } // 不可插入相同的key,否则失败 pair<iterator, bool> insert_unique(const value_type& x); // 可以插入相同的key pair<iterator, bool> insert_equal(const value_type& x); // 查找 iterator find(const Key& k) { link_type y = header; link_type x = root(); while(x != 0) { if(!kwy_compare(key(x), k)) { y = x; x = left(x); } else { x = right(x); } } iterator j = iterator(y); return (j == end() || key_compare(k, key(j.node))) ? end() : j; } }
set
-
底层是红黑树
-
set中的元素只有key,没有value
-
set中不允许存在两个相同的元素
multiset
-
mutliset和set基本类似,唯一的不同是set不允许重复,mutliset允许重复
-
set使用insert_unique,mutliset使用insert_equal
map
-
底层是红黑树
-
map中的元素是键值对
-
map中不允许存在两个相同的元素
-
键值对pair的定义:
template <class T1, class T2> struct pair { typedef T1 first_type; typedef T2 second_type; T1 first; T2 second; pair() : first(T1()), seocond(T2()) {} pair(const T1& a, const T2& b) : first(a), second(b) {} }
multimap
-
mutlimap和map基本类似,唯一的不同是map不允许key重复,mutlimap允许重复
-
map使用insert_unique,mutlimap使用insert_equal
hashtable
-
以空间换时间
-
用一个足够大的vector保存所有的数据,为了使得所有数据都可以对应数组中唯一的一个下标,因此使用一个映射函数,将数据映射成下标,然后存储到vector中
-
如果映射的下标处已经存在数据,就发生“碰撞”,需要使用其他方法进行规避,如:
-
线性探测
-
二次探测
-
开链
-
-
如果映射的下标处没有数据,直接存储
-
-
hashtable中的数据除以vector的大小叫负载系数,如果负载系数超过一定值,就需要扩大vector
-
线性探测:如果映射出的下标已经存储了数据,那么将下标加1,进行存储,如果还是已经存储了数据,那么再加1,依次往后...
-
二次探测:如果映射出的下标已经存储了数据,那么将下标加1^2,进行存储,如果还是已经存储了数据,那么再加2^2,依次往后...
-
开链:如果映射出的下标已经存储了数据,那么直接将数据头插到该下标指向的链表中,即同一链表中的下标值都相同(类似deque的底层数据存储结构)
hashtable的各种结构定义
-
节点定义
template <class Value> struct __hashtable_node { __hashtable_node* next; Value val; };
- 迭代器定义
template <class Value, class Key, class HashFcn, class ExtractKey, class EqualKey, class Alloc> struct __hashtable_iterator { typedef hashtable<Value, Key, HashFcn, ExtractKey, EqualKey, Alloc> hashtable; typedef __hashtable_iterator<Value, Key, HashFcn, ExtractKey, EqualKey, Alloc> iterator; typedef __hashtable_node<Value> node; typedef forward_iterator_tag iterator_category; typedef Value value_type; typedef ptrdiff_t difference_type; typedef size_t size_type; typedef value& reference; typedef value* pointer; node* cur; hashtable* ht; __hashtable_iterator(node* n, hashtable* tab) : cur(n), ht(tab){} __hashtable_iterator() {} reference operator*() const { return cur->val; } pointer operator->() const { return &(operator*()); } iterator& operator++() { const node* old = cur; cur = cur->next; if(!cur) { size_type bucket = ht->bkt_num(old->val); while(!cur && ++bucket < ht->buckets.size()) { cur = ht->buckets[bucket]; } } return *this; } iterator& operator++(int) { iterator tmp = *this; ++*this; return tmp; } bool operator==(const iterator& it) const { return cur == it.cur; } bool operator!=(const iterator& it) const { return cur != it.cur; } }
- hashtable定义
template <class Value, class Key, class HashFcn, class ExtractKey, class EqualKey, class Alloc> class hashtable { public: typedef HashFcn hasher; typedef EqualKey key_equal; typedef size_t size_type; private: hasher hash; key_equal equals; ExtractKey get_key; typedef __hashtable_node<Value> node; typedef simple_alloc<node, Alloc> node_allocator; vector<node*, Alloc> buckets; size_type num_elements; public: size_type bucket_count() const { return buckets.size(); } } /* Value:节点值类型 Key:节点的键值类型 HashFcn:仿函数,计算hash值 ExtractKey:仿函数,提取key值 EqualKey:仿函数,判别键值是否相同的方法 Alloc:空间配置器 */
node* new_node(const value_type& obj) { node* n = node_allocator::allocate(); n->next = 0; construct(&n->val, obj); return n; } void delete_node(node* n) { destroy(&n->val); node_allocator::deallocate(n); } hashtable(size_type n, const HashFcn hf, const EqualKey eql) : hash(hf), equals(eql), get_key(ExtractKey()), num_elements(0) { initialize_buckets(n); } void initialize_buckets(size_type n) { const size_type n_buckets = next_size(n); buckets.reserve(n_buckets); buckets.insert(buckets.end(), n_buckets, (node*)0); num_elements = 0; } size_type next_size(size_type n) const { // 有一个大小为28的数组,里面全部是质数。下面函数是取出数组里面最接近n的质数。 return __stl_next_prime(n); }
// 插入数据不允许重复 pair<iterator, bool>insert_unique(const value_type& obj) { resize(num_elements + 1); // 判断表格vector是否需要重建,如果需要就重建 return insert_unique_noresize(obj); // 插入键值,不允许重复 } void resize(size_type num_elements_hint) { const size_type old_n = buckets.size(); if(num_elements_hint > old_n) { vector<node*, Alloc> tmp(n, (node*)0); for(size_type bucket = 0; bucket < old_n; ++bucket) { node* first = buckets[bucket]; /* 感觉没有必要遍历链表,直接移动链表头结点就行 */ while(first) { size_type new_bucket = bkt_num(first->val, n); buckets[bucket] = first->next; first->next = tmp[new_bucket]; tmp[new_bucket] = first; first = buckets[bucket]; } } buckets.swap(tmp); } } pair<iterator, bool> insert_unique_noresize(const value_type& obj) { const size_type n = bke_num(obj); node* first = buckets[n]; for(node* cur = first; cur; cur = cur->next) { if(equals(get_key(cur->val), get_key(obj))) { return pair<iterator, bool>(iterator(cur, this), false); } } node* tmp = new_node(obj); tmp->next = first; bucklet[n] = tmp; ++num_elements; return pair<iterator, bool>(iterator(tmp, this), true); }
// 插入数据允许重复 iterator insert_equal(const value_type& obj) { resize(num_elements + 1); // 判断表格vector是否需要重建,如果需要就重建 return insert_equal_noresize(obj); // 插入键值,允许重复 } iterator insert_equal_noresize(const value_type& obj) { const size_type n = bke_num(obj); node* first = buckets[n]; for(node* cur = first; cur; cur = cur->next) { if(equals(get_key(cur->val), get_key(obj))) { // 如果有key相同的节点,将新节点插入在相同节点的后面 node* tmp = new_node(obj); tmp->next = cur->next; cur->next = tmp; ++num_elements; return iterator(tmp, this); } } node* tmp = new_node(obj); tmp->next = first; bucklet[n] = tmp; ++num_elements; return iterator(tmp, this); }
// 映射函数 size_type bkt_num(const value_type& obj, size_t n) const { return bkt_num_key(get_key(obj), n); } size_type bkt_num(const value_type& obj) const { return bkt_num_key(get_key(obj)); } size_type bkt_num_key(const key_type& key) const { return bkt_num_key(get_key(obj), buckets.size()); } // 最底层干活的函数 size_type bkt_num_key(const key_type& key, size_t n) const { // STL为所有的基础类型都定义了hash函数 return hash(key) % n; }
-
使用方式和set完全相同
-
底层使用hashtable
-
hashset中的元素只有key,没有value
-
hashset中不允许存在key相同的数据
hash_mutliset
-
和hash_set完全相同,唯一的不同是允许存在相同key的数据
-
底层使用hashtable
hash_map
-
使用方式和map完全相同
-
底层使用hashtable
-
map中不允许存在两个相同的元素
-
存储的是键值对
hash_mutlimap
-
和hash_map完全相同,唯一的不同是允许存在相同key 的数据
-
底层使用hashtable
自定义的类作为map和hash_map的key需要注意的几点
-
自定义类做map的key
-
必须从重载
operator<
-
-
自定义类做hash_map的key
-
提供equals()
-
提供hashcode()
-