由于暂时没有可用的GPU来进行训练,想到了高效利用资本主义过剩的资源 Google Colab
过程如下
1.在笔记电脑上,准备相关数据和代码
2.将数据和代码上传到Google Colaboratory,利用K80进行训练(现在有TPU,暂时还不知道怎么玩 XD )
3.训练结果下载到笔记电脑,利用笔记本电脑 CPU进行图像推理(目标检测)
教程参考自日本友人
https://wakuphas.hatenablog.com/entry/2018/09/19/025941
环境配置
笔记电脑
- Ubuntu18.04
- Anaconda 3-5.0
- Python 3.6.2
- Tensorflow 1.5.0
云服务器
- Google Colaboratory
一.数据准备(在Ubuntu笔记本上)
1)下载darknet
这里有两个版本可以选(第一个为YOLO原作者,第二个为A神版)任选都可 (操作都一样)
我这里使用的第二个
git clone https://github.com/pjreddie/darknet.git
git clone https://github.com/AlexeyAB/darknet.git
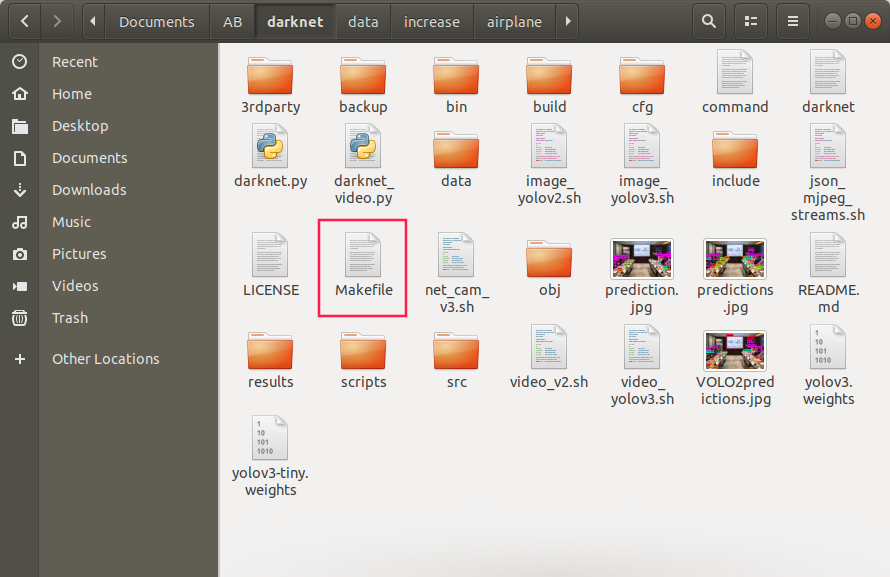
GPU=0 #确保为0 因为笔记本没有GPU CUDNN=0 CUDNN_HALF=0 OPENCV=0 AVX=1 #CPU相关 OPENMP=1 #CPU相关 LIBSO=0
确保Makefile 与上述一样(其实确保GPU=0就行,其他不用改)
2)编译make
$ make
3) 下载已经训练过的官方权重文件(我们这里需要用到YOLOV2的权重,但建议YOLOV3也下)
wget https://pjreddie.com/media/files/yolov2.weights
wget https://pjreddie.com/media/files/yolov3.weights
4) 下载后,将yolov2.weights移动到bin文件夹(其实也可以放在darknet目录下)
$ mkdir bin
$ mv yolov.weights bin/
检查 图像目标测试./darknet的命令是否有效
$ ./darknet detect cfg/yolov2.cfg bin/yolov2.weights data/dog.jpg
目标检测以prediction.jpg的形式存放在darknet目录下
注意 如果 yolov2.weights 没有移动到bin文件夹 而是在darknet目录下,使用一下命令进行目标检测
$ ./darknet detect cfg/yolov2.cfg yolov2.weights data/dog.jpg
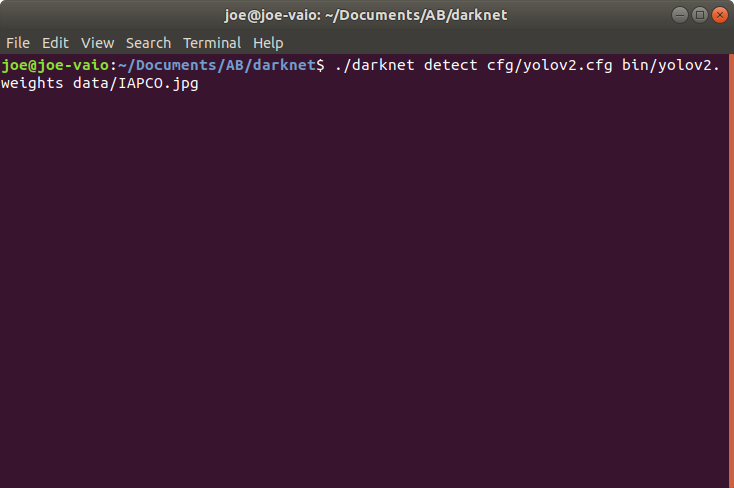
运行结果,花费4596毫秒
2.准备图像训练集
这里使用13张飞机航拍视角的照片作为初始训练集 (你也可以自行准备,不管是爬虫还是既有的数据集)
images_airport.zip - Google云端硬盘
下载ZIP
3.训练集膨胀
通过填充,翻转,旋转图像获得更多的图像数据
通过一个Python脚本实现(脚本保存为increase_img.py 顺利运行需要另外Python依赖库,根据提示,自行pip install xxx安装)
import glob import traceback import numpy as np from keras.preprocessing.image import ImageDataGenerator, load_img, img_to_array import os base_path = './' def generate_images(class_name, generator): dir = base_path + class_name + '/' if not os.path.exists(dir + "output"): os.mkdir(dir + "output") savedir = base_path + class_name + '/output/' images = glob.glob(dir + '/*.jpg') print("input files = ", len(images)) for i, image in enumerate(images): image = load_img(image) x = img_to_array(image) x = np.expand_dims(x, axis=0) g = generator.flow(x, save_to_dir=savedir, save_prefix=class_name, save_format='jpg') for j in range(10): g.next() print("output files = ", len(glob.glob(savedir + '/*.jpg'))) if __name__ == '__main__': try: train_datagen = ImageDataGenerator( rotation_range=0., width_shift_range=0., height_shift_range=0., shear_range=0.2, zoom_range=0.2, horizontal_flip=True, vertical_flip=True, rescale=1.0 / 255 ) generate_images('airplane', train_datagen) #generate_images('gorilla', train_datagen) #generate_images('chimpanzee', train_datagen) except Exception as e: traceback.print_exc()
将图像训练集(13张图片)移动到 darknet / data / increase / airplane /
increase_img.py 放置到 darknet / data / increase /
终端运行
python increase_img.py
# 下面为终端输出
# Using TensorFlow backend.
# ('input files = ', 13)
# ('output files = ', 130)
等待一会 发现airplane会多一个output目录
里面就是膨胀的图片 130张
4 对数据集图像进行标注
输入:原始图像
输出:目标对象(飞机)和位置标签(BOX的xy坐标)
这里使用 BBox-Label-Tool 完成此项工作
$ cd data $ git clone https://github.com/puzzledqs/BBox-Label-Tool.git
注意修改脚本
BBox-Label-Tool默认处理”JPEG“,而我们这里是需要对jpg进行处理,所以需要将main.py中所有的JPEG全部替换成 jpg
安装Tkinter依赖库
sudo apt-get install python-tk
使用BBox-Label-Tool运行main.py,一定要用Python2 运行
$ python2 main.py
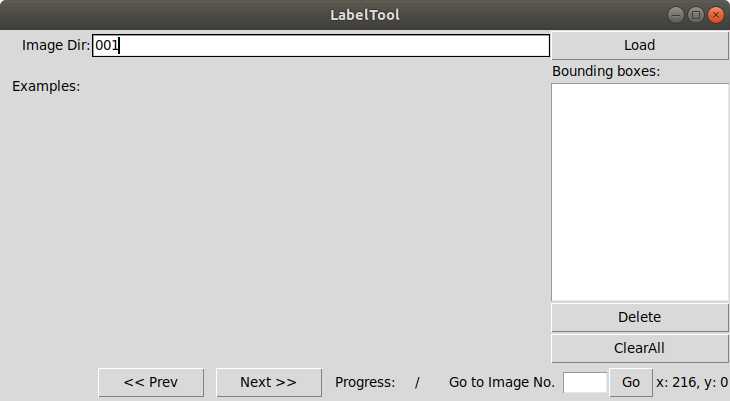
这里的001为image目录下的存放图片的文件夹,点击load

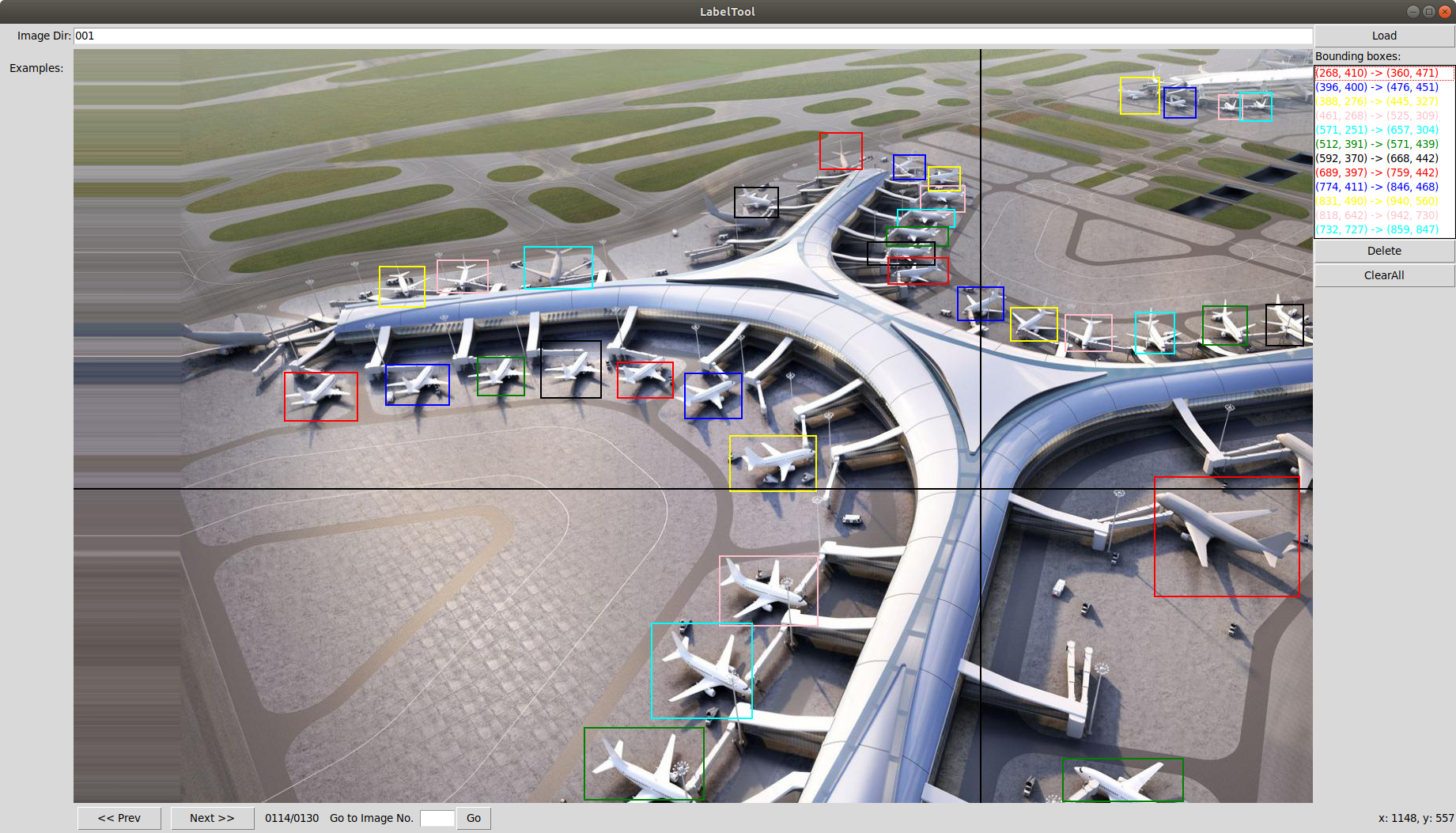
苦力标注做完后 需要将txt标签转换成YOLO所需要的格式 如下
标签号 x_center y_center x_width y_width
下面代码存为convert.py
# -*- coding: utf-8 -*- """ Created on Wed Dec 9 14:55:43 2015 This script is to convert the txt annotation files to appropriate format needed by YOLO @author: Guanghan Ning Email: gnxr9@mail.missouri.edu """ import os from os import walk, getcwd from PIL import Image classes = ["stopsign"] def convert(size, box): dw = 1./size[0] dh = 1./size[1] x = (box[0] + box[1])/2.0 y = (box[2] + box[3])/2.0 w = box[1] - box[0] h = box[3] - box[2] x = x*dw w = w*dw y = y*dh h = h*dh return (x,y,w,h) """-------------------------------------------------------------------""" """ Configure Paths""" mypath = "labels/stopsign_original/" outpath = "labels/stopsign/" cls = "stopsign" if cls not in classes: exit(0) cls_id = classes.index(cls) wd = getcwd() list_file = open('%s/%s_list.txt'%(wd, cls), 'w') """ Get input text file list """ txt_name_list = [] for (dirpath, dirnames, filenames) in walk(mypath): txt_name_list.extend(filenames) break print(txt_name_list) """ Process """ for txt_name in txt_name_list: # txt_file = open("Labels/stop_sign/001.txt", "r") """ Open input text files """ txt_path = mypath + txt_name print(" Input:" + txt_path) txt_file = open(txt_path, "r") lines = txt_file.read().split(' ') #for ubuntu, use " " instead of " " """ Open output text files """ txt_outpath = outpath + txt_name print("Output:" + txt_outpath) txt_outfile = open(txt_outpath, "w") # 2桁以上のtxtは無視 modified 2018.9.16 num_lines = sum(1 for line in open(mypath + txt_name)) print("##### num lines", num_lines, "#####") if num_lines >= 10: continue """ Convert the data to YOLO format """ ct = 0 for line in lines: #print('length of line is: ') #print(lines, "aa") #print(len(line), "bb") #print(' ') if(len(line) >= 2): #if((len(line) >= 2) and (li < 10)): ct = ct + 1 #print(line + "cc") elems = line.split(' ') #print(elems) xmin = elems[0] xmax = elems[2] ymin = elems[1] ymax = elems[3] # img_path = str('%s/images/%s/%s.jpg'%(wd, cls, os.path.splitext(txt_name)[0])) #t = magic.from_file(img_path) #wh= re.search('(d+) x (d+)', t).groups() im=Image.open(img_path) w= int(im.size[0]) h= int(im.size[1]) #w = int(xmax) - int(xmin) #h = int(ymax) - int(ymin) # print(xmin) #print(w, h) b = (float(xmin), float(xmax), float(ymin), float(ymax)) bb = convert((w,h), b) print(bb) txt_outfile.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + ' ') """ Save those images with bb into list""" if(ct != 0): list_file.write('%s/images/%s/%s.jpg '%(wd, cls, os.path.splitext(txt_name)[0])) list_file.close()
将convert.py保存在 darknet / data / convert / 下
将convert.py ,图像训练集与标签 按下面目录关系进行放置
************ darknet/data/convert/ |- images |- stopsign |- airport00.jpg |- airport01.jpg … |- labels |- stopsign |- stopsign_original |- airport00.txt |- airport01.txt … |- convert.py ************
然后运行 convert.py
$ python convert.py
# 成功运行完毕的如下图
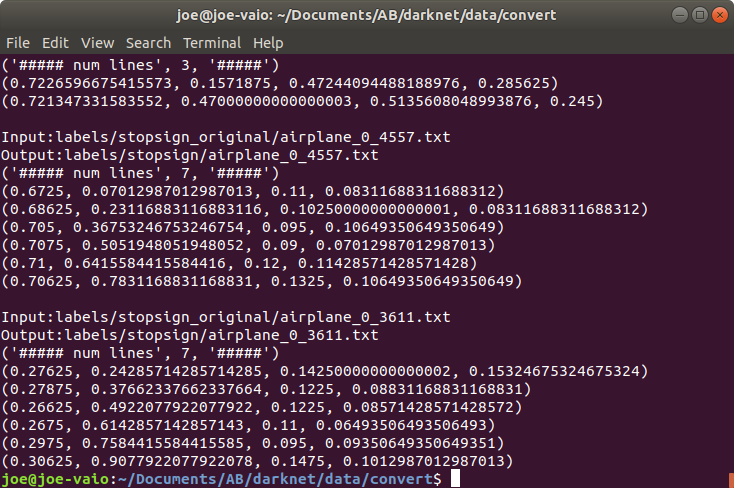
可以进入stopsign目录进行查看txt,格式下同即为成功,因为只是用了一个标签号,此时0对应飞机
0 0.347736625514 0.552884615385 0.0617283950617 0.0865384615385 0 0.438271604938 0.747596153846 0.0864197530864 0.0817307692308 0 0.69341563786 0.545673076923 0.0864197530864 0.110576923077 0 0.83950617284 0.447115384615 0.082304526749 0.0865384615385
接着将data/convert/labels/stopsign/airplane****.txt等 复制到 darknet/data/labels/
将data/convert/images/stopsign/airplane_****.jpg等 复制到 darknet/data/images/ (没有就新建)
注意:原本darknet/data/labels/文件夹内有很多像32_0.png的字母类图像,建议保持原样不要移动,否则会出现错误。
本次文件放置目录关系如下
************ darknet/data/ |- images |- airport00.jpg |- airport01.jpg … |- labels |- airport00.txt |- airport01.txt … |- 32_0.png ... ************
5 划分训练数据和测试数据
在darknet/data中保存名字为process.py的脚本(复制下面)
# modified 2018.9.16 import glob, os # Current directory current_dir = os.path.dirname(os.path.abspath(__file__)) # Directory where the data will reside, relative to 'darknet.exe' path_data = 'images/' # Percentage of images to be used for the test set percentage_test = 20; # Create and/or truncate train.txt and test.txt file_train = open(path_data + '/train.txt', 'w') file_test = open(path_data + '/test.txt', 'w') # Populate train.txt and test.txt counter = 1 index_test = round(100 / percentage_test) for pathAndFilename in glob.iglob(os.path.join(path_data, "*.jpg")): title, ext = os.path.splitext(os.path.basename(pathAndFilename)) if counter == index_test: counter = 1 file_test.write("data/" + path_data + title + '.jpg' + " ") else: file_train.write("data/" + path_data + title + '.jpg' + " ") counter = counter + 1 print("ok")
然后运行脚本对图像数据集进行训练/验证集划分,生成test.txt , train.txt在data/images
$ python process.py
# 成功会打印 'ok'
6 设置学习参数
准备以下两点
- 在darknet/data/images/上创建类列表obj.names 内容只写一行 airplane
- 在darknet/data/中创建名为names.list的文件,与保存飞机的obj.names相同,只有一行airplane
参考下面网站写法
https://github.com/ecthros/labelReader/blob/master/data/obj.names
参数设定
指定目标种类数和数据的位置(用vim写入并创建可读文件 obj.data 放在darknet/cfg/下)
$ sudo vi obj.data
保存内容
classes=1 train = data/images/train.txt valid = data/images/test.txt labels = data/images/obj.names backup = backup/
classes#这次目标种类只有一个 就是airplane
train#进行训练权重
valid#进行测试
labels # class list
backup#存储权重的位置
接着编辑模型。根据要使用的模型为基础进行编辑
这次是yolov2-voc.cfg.
因为稍后使用的darkflow当前不支持yolov3 , 因此采用yolov2。
$ cd darknet/cfg/ $ cp yolov2-voc.cfg yolo-obj.cfg
# 把yolov2-voc.cfg复制并命名为yolo-obj.cfg
手动或者vim编辑 yolo-obj.cfg
第3行:batch=64。每个学习阶段使用的图像的张数。也可以注释掉并打开第6行。 第4行:subdivisions=8。批次除以8,作细分。也可以注释掉并打开第7行。 第244行:改classes=1。本次训练只有airplane一个类型。 第237行:filters=30。filters=(classes+coords+1)*5 必须符合这个设定 coords=4
顺利完成以上步骤的话,现在可以随时训练。
在第一次训练时,因为在读取适当的权重作为初始值读入,则较容易收敛
将以下内容保存/下载到darknet /
yolov2的初始值文件
https://pjreddie.com/media/files/darknet19_448.conv.23
yolov3的初始值文件
https://pjreddie.com/media/files/darknet53.conv.74
浏览器下载较慢,建议复制到迅雷下载
测试初始权重的模型推理效果
可以执行以下操作
$ ./darknet detector train cfg/obj.data cfg/yolo-obj.cfg darknet19_448.conv.23
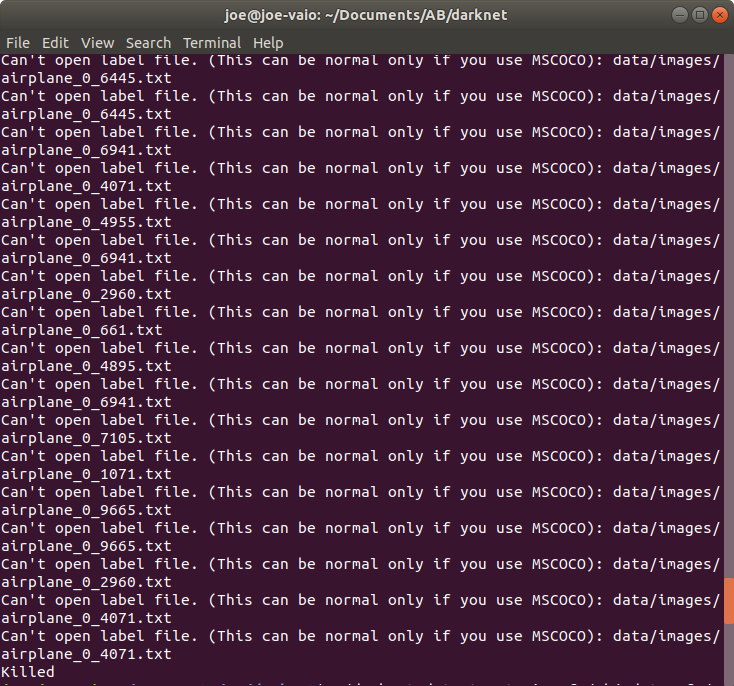
报错Can't open label file. (This can be normal only if you use MSCOCO)
很奇怪,原因是少了对应的label文件
于是把data/labels/airplane_*****.txt等文件复制到 data/images/下

再次执行
$ ./darknet detector train cfg/obj.data cfg/yolo-obj.cfg darknet19_448.conv.23
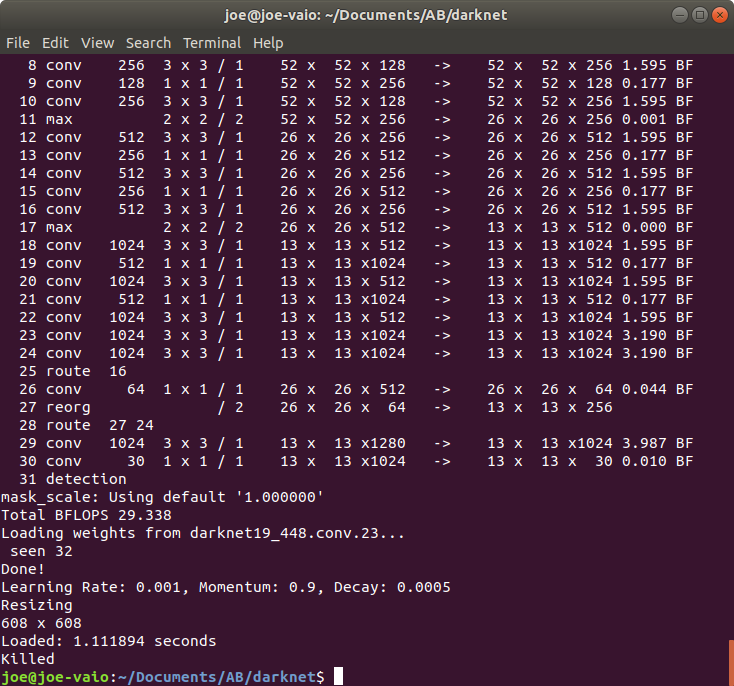
成功运行,killed是因为设定的配置文件yolo-obj.cfg batch等设定 cpu无法承受负荷
假设训练能够顺利进行,漫长的等待后 当训练完成 ,权重weights文件保存在darknet / backup中
设定重量输出间隔:
注意:如果你用的是原版darknet 就可以在examples里面找到,我这里是用的AB版detector.c在darknet/ src / detector.c 内容不一样 还没弄清楚怎么修改
权重文件默认为
1000epochs之前每隔100epochs输出
1000epochs以后每隔10000epochs输出
1000-10000之间比较有宽度,所以设定1000epochs以后每100epochs可以详细输出
darknet / examples / detector.c改写第138行,如下所示。
#默认每10000个时期输出一次 if(i%10000 == 0 ||(i <1000 && i%100 == 0)){
改为
#每100个刻度重写一次 if(i%100 == 0 ||(i <1000 && i%100 == 0)){
然后在darknet/下 运行编译
$ make
7.将darknet文件夹压缩为zip
由于GPU在Colab 上使用,请打开darknet / Makefile并将其更改为GPU = 1
此时,不要在笔记本电脑上运行make(因为没有GPU,会发生错误)
为了在Colab中运行,需要上传到google drive,因此,对这个darknet文件夹进行压缩。
$ cd ../
$ zip -r darknet.zip darknet
其实这里可以直接右键darknet文件夹 compress操作 更快(但不知道有没有影响)
二.在Colab上进行训练
1)将zip文件上传到google drive
用自己的Google帐户登陆Drive。将zip文件上传到适当的目录
2)打开google colaboratory
https://github.com/clemente620/wakuphas/blob/master/AI/Scripts/darknet_airport%20.ipynb
将其另存为.ipynb 并将其上传到google drive
右键单击Drive 并选择“Open with application” - >“ Google Colaboratory ”。
从Runtime选项卡中选择Change Runtime Type,然后选择Python 3和GPU。
注意Makefile文件中GPU一定要打开 也就是 写成GPU=1
可以通过colab命令操作进行修改
先用cat 查看文本 并复制
!cat darknet/Makefile
修改为GPU=1,复制全文 粘贴到下面<>中
%%writefile darknet/Makefile
<修改后的内容进行原文覆盖>
基本上,通过按照darknet_airport.ipynb中的指示执行单元格,完成以下过程
I)Colab的环境搭建
Ⅱ)上传zip到“Colab”
Iii)执行make编译
Ⅳ)用./daknet命令进行训练
V)输出权重文件
2.5. Colab的注意事项
因为是免费的,所以有各种各样的规则,不过,12小时规则是最应该注意的点。
GPU连接后最大可以连续运行12小时,不过超过12小时后,上传的数据和输出的文件,甚至连搭建的环境都会重置
所以每次都需要对ipynb文件进行环境搭建。
几个小时后GPU本身也可以使用,但由于删除的数据无法恢复,请右键单击以经常下载重量文件等。
3. 将输出权重文件下载到笔记本电脑
使用./darknet命令学习时,首先读取准备的初始值,但即使它被中断一次,它也可以从权重文件重新开始.weights作为初始值输出。
#使用准备好的初始值的情况
$ ./darknet detector train cfg/obj.data cfg/yolo-obj.cfg darknet19_448.conv.23 > train_log.txt
#读取所输出的权重yolo-obj_xxx .weights时
$ ./darknet detector train cfg/obj.data cfg/yolo-obj.cfg backup/yolo-obj_XXX.weights > train_log.txt
输出日志到train_log.txt。 下载并在笔记本电脑上打开它。
注意每几行出现的以下内容。
-- 937: 34.240753, 37.657242 avg, 0.000771 rate, 5.082382 seconds, 59968 images --
第一个数字是迭代次数。 通常需要2000次。 随着avg前的数量减少,准确度会增加。
如果avg的数字不减少,就停止学习。
将Colab上的权重文件darknet/backup/***.weights下载到本地的笔记本电脑上。
我这边的情况是,train_log.txt的avg值和epoch数之间的关系如下。
(extractor.sh和plot.py将下载到darkflow /。将根据您的train_log.txt存在的路径将extractor.sh 重写修改)
$ sh extractor.sh # epochavg.txt输出
$ python plot.py
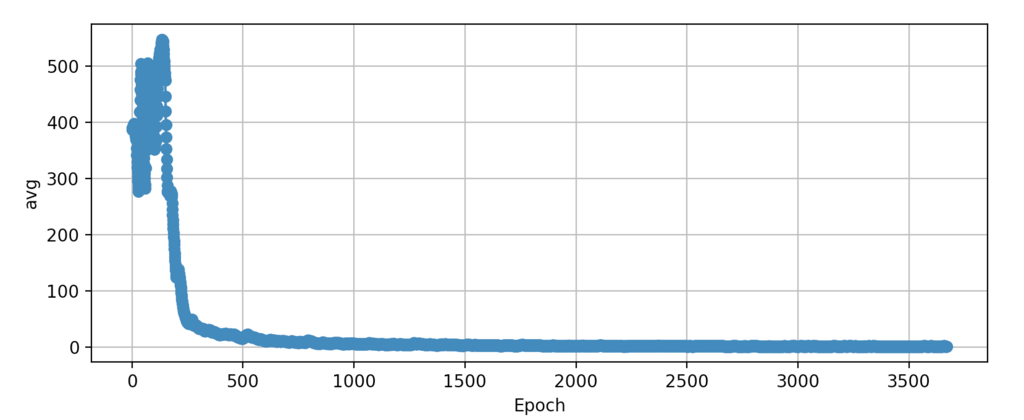
因为自2000次epochs以后几乎没有增加或减少,所以我们可以在那里停止,不过,但为了保险期间,总共迭代了3600次。
虽然最终的avg在2左右
使用训练的权重进行检测 语句
sudo ./darknet detector test cfg/obj.data cfg/yolo-obj.cfg yolo-obj_2000.weights data/airplane_0_3611.jpg
三. 在笔记本电脑上进行推理(测试)
1. 安装darkflow
$ git clone https://github.com/thtrieu/darkflow.git $ cd darkflow $ python3 setup.py build_ext --inplace
2. 创建一个Python程序
https://github.com/wakuphas/wakuphas/blob/master/AI/Scripts/detect.py
把这个detect.py放入darkflow /
根据需要可以进行的改动部分:
第6行:写入文件的路径。
第11行:描述想要识别的图像路径。
第21行:指定检测的种类名称(标注名称)。
第35行:显示大于0.1的置信度(confidence)
3.加载weights文件并进行对象检测
准备下面的四条
- Colab训练和输出的weights被放置于darkflow/backup中。
- 在学习中使用的darknet/cfg/ yoloobj.cfg拷贝到darkflow/cfg中,改为batch=1, subdivisions=1并保存
- 在darkflow /中创建labels_airplane.txt并写入1行 "airplane" 保存
- 将test_airplane.jpg作为确认用图像保存在darkflow/中
运行detect.py
$ python detect.py

以上显示推理(目标检测)成功
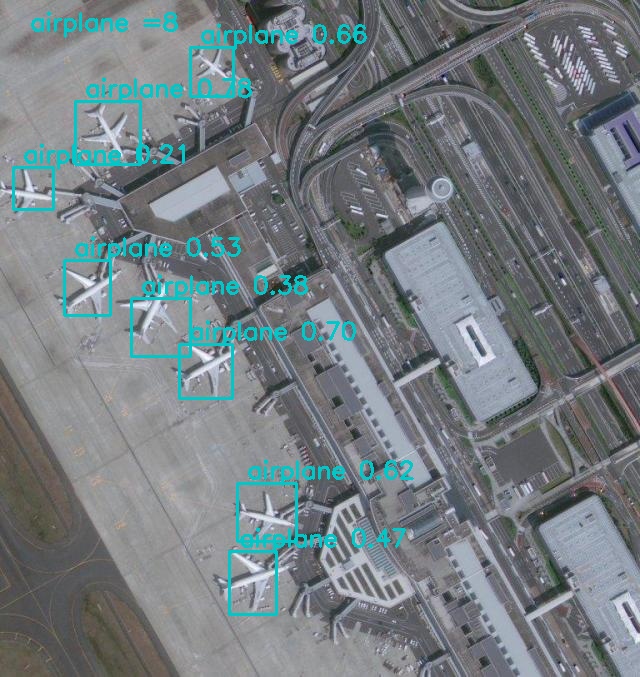
可以使用esc按钮退出
最终结论 colab 不适合中国玩家 经常runtime disconnected 需要按键精灵脚本重连 很烦 用来试玩TPU还行
(如果你在美国,网络较稳定还是可以玩玩的)