1.1体系结构简单介绍
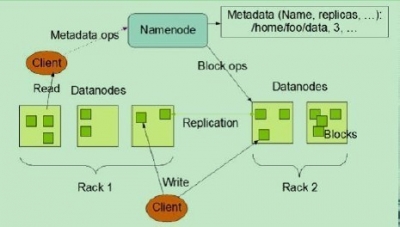
HDFS是一个主/从(Mater/Slave)体系结构。从终于用户的角度来看,它就像传统的文件系统一样,能够通过文件夹路径对文件运行CRUD(Create、Read、Update和Delete)操作。但因为分布式存储的性质,HDFS集群拥有一个NameNode和一些DataNode。NameNode管理文件系统的元数据,DataNode存储实际的数据。
client通过同NameNode和DataNodes的交互訪问文件系统。
client联系NameNode以获取文件的元数据,而真正的文件I/O操作是直接和DataNode进行交互的。 下图为HDFS整体结构示意图
1.1.1 NameNode
NameNode能够看作是分布式文件系统中的管理者。主要负责管理文件系统的命名空间、集群配置信息和存储块的复制等。NameNode会将文件系统的Meta-data存储在内存中,这些信息主要包含了文件信息、每个文件相应的文件块的信息和每个文件块在DataNode的信息等。
l Masterl 管理HDFS的名称空间l 管理数据块映射信息l 配置副本策略l 处理client读写请求
1.1.2 Secondary namenode
并不是NameNode的热备; 辅助NameNode,分担其工作量; 定期合并fsimage和fsedits,推送给NameNode; 在紧急情况下。可辅助恢复NameNode。
1.1.3 DataNode
DataNode是文件存储的基本单元,它将Block存储在本地文件系统中,保存了Block的Meta-data,同一时候周期性地将全部存在的Block信息发送给NameNode。
Slavel 存储实际的数据块 运行数据块读/写
1.1.4 Client
文件切分 与NameNode交互,获取文件位置信息; 与DataNode交互。读取或者写入数据; 管理HDFS。 訪问HDFS。
1.1.5 文件写入
1) Client向NameNode发起文件写入的请求。 2) NameNode依据文件大小和文件块配置情况。返回给Client它所管理部分DataNode的信息。 3) Client将文件划分为多个Block,依据DataNode的地址信息,按顺序写入到每个DataNode块中。
1.1.6 文件读取
1) Client向NameNode发起文件读取的请求。 2) NameNode返回文件存储的DataNode的信息。
3) Client读取文件信息。
HDFS典型的部署是在一个专门的机器上执行NameNode,集群中的其它机器各执行一个DataNode;也能够在执行NameNode的机器上同一时候执行DataNode,或者一台机器上执行多个DataNode。一个集群仅仅有一个NameNode的设计大大简化了系统架构。
1.2长处
1.2.1 处理超大文件
这里的超大文件一般是指百MB、设置数百TB大小的文件。眼下在实际应用中,HDFS已经能用来存储管理PB级的数据了。
1.2.2 流式的訪问数据
HDFS的设计建立在很多其它地响应"一次写入、多次读写"任务的基础上。
这意味着一个数据集一旦由数据源生成。就会被复制分发到不同的存储节点中,然后响应各种各样的数据分析任务请求。
在多数情况下,分析任务都会涉及数据集中的大部分数据,也就是说,对HDFS来说。请求读取整个数据集要比读取一条记录更加高效。
1.2.3 执行于便宜的商用机器集群上
hadoop设计对硬件需求比較低。仅仅须执行在低廉的商用硬件集群上,而无需昂贵的高可用性机器上。便宜的商用机也就意味着大型集群中出现节点故障情况的概率很高。这就要求设计HDFS时要充分考虑数据的可靠性,安全性及高可用性。
1.3 缺点
1.3.1 不适合低延迟数据訪问
假设要处理一些用户要求时间比較短的低延迟应用请求。则HDFS不适合。HDFS是为了处理大型数据集分析任务的,主要是为达到高的数据吞吐量而设计的,这就可能要求以高延迟作为代价。
改进策略:
对于那些有低延时要求的应用程序,HBase是一个更好的选择。
通过上层数据管理项目来尽可能地弥补这个不足。在性能上有了非常大的提升,它的口号就是goes real time。
使用缓存或多master设计能够降低client的数据请求压力,以降低延时。还有就是对HDFS系统内部的改动,这就得权衡大吞吐量与低延时了,HDFS不是万能的银弹。
1.3.2 无法高效存储大量小文件
由于Namenode把文件系统的元数据放置在内存中,所以文件系统所能容纳的文件数目是由Namenode的内存大小来决定。一般来说,每个文件、目录和Block须要占领150字节左右的空间。所以。假设你有100万个文件,每个占领一个Block,你就至少须要300MB内存。当前来说,数百万的文件还是可行的,当扩展到数十亿时。对于当前的硬件水平来说就没法实现了。另一个问题就是,由于Map task的数量是由splits来决定的。所以用MR处理大量的小文件时。就会产生过多的Maptask。线程管理开销将会添加作业时间。
举个样例。处理10000M的文件,若每一个split为1M。那就会有10000个Maptasks,会有非常大的线程开销;若每一个split为100M。则仅仅有100个Maptasks。每一个Maptask将会有很多其它的事情做,而线程的管理开销也将减小非常多。
改进策略:
要想让HDFS能处理好小文件。有不少方法。
利用SequenceFile、MapFile、Har等方式归档小文件,这种方法的原理就是把小文件归档起来管理,HBase就是基于此的。
对于这样的方法,假设想找回原来的小文件内容,那就必须得知道与归档文件的映射关系。横向扩展,一个Hadoop集群能管理的小文件有限,那就把几个Hadoop集群拖在一个虚拟server后面。形成一个大的Hadoop集群。google也是这么干过的。多Master设计,这个作用显而易见了。正在研发中的GFS II也要改为分布式多Master设计,还支持Master的Failover。并且Block大小改为1M。有意要调优处理小文件啊。
附带个Alibaba DFS的设计,也是多Master设计。它把Metadata的映射存储和管理分开了,由多个Metadata存储节点和一个查询Master节点组成。
1.3.3 不支持多用户写入及随意改动文件
在HDFS的一个文件里仅仅有一个写入者,并且写操作仅仅能在文件末尾完毕。即仅仅能运行追加操作。
眼下HDFS还不支持多个用户对同一文件的写操作,以及在文件任何位置进行改动。