这两个类所在目录:
hadoop-examples-0.20.2-cdh3u6.jar 中:

代码:
TeraGen.java:
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.hadoop.examples.terasort;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.zip.Checksum;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.io.WritableUtils;
import org.apache.hadoop.mapreduce.Cluster;
import org.apache.hadoop.mapreduce.Counter;
import org.apache.hadoop.mapreduce.InputFormat;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.JobContext;
import org.apache.hadoop.mapreduce.MRJobConfig;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.PureJavaCrc32;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* Generate the official GraySort input data set.
* The user specifies the number of rows and the output directory and this
* class runs a map/reduce program to generate the data.
* The format of the data is:
* <ul>
* <li>(10 bytes key) (constant 2 bytes) (32 bytes rowid)
* (constant 4 bytes) (48 bytes filler) (constant 4 bytes)
* <li>The rowid is the right justified row id as a hex number.
* </ul>
*
* <p>
* To run the program:
* <b>bin/hadoop jar hadoop-*-examples.jar teragen 10000000000 in-dir</b>
*/
public class TeraGen extends Configured implements Tool {
private static final Log LOG = LogFactory.getLog(TeraSort.class);
public static enum Counters {CHECKSUM}
public static final String NUM_ROWS = "mapreduce.terasort.num-rows";
/**
* An input format that assigns ranges of longs to each mapper.
*/
static class RangeInputFormat
extends InputFormat<LongWritable, NullWritable> {
/**
* An input split consisting of a range on numbers.
*/
static class RangeInputSplit extends InputSplit implements Writable {
long firstRow;
long rowCount;
public RangeInputSplit() { }
public RangeInputSplit(long offset, long length) {
firstRow = offset;
rowCount = length;
}
public long getLength() throws IOException {
return 0;
}
public String[] getLocations() throws IOException {
return new String[]{};
}
public void readFields(DataInput in) throws IOException {
firstRow = WritableUtils.readVLong(in);
rowCount = WritableUtils.readVLong(in);
}
public void write(DataOutput out) throws IOException {
WritableUtils.writeVLong(out, firstRow);
WritableUtils.writeVLong(out, rowCount);
}
}
/**
* A record reader that will generate a range of numbers.
*/
static class RangeRecordReader
extends RecordReader<LongWritable, NullWritable> {
long startRow;
long finishedRows;
long totalRows;
LongWritable key = null;
public RangeRecordReader() {
}
public void initialize(InputSplit split, TaskAttemptContext context)
throws IOException, InterruptedException {
startRow = ((RangeInputSplit)split).firstRow;
finishedRows = 0;
totalRows = ((RangeInputSplit)split).rowCount;
}
public void close() throws IOException {
// NOTHING
}
public LongWritable getCurrentKey() {
return key;
}
public NullWritable getCurrentValue() {
return NullWritable.get();
}
public float getProgress() throws IOException {
return finishedRows / (float) totalRows;
}
public boolean nextKeyValue() {
if (key == null) {
key = new LongWritable();
}
if (finishedRows < totalRows) {
key.set(startRow + finishedRows);
finishedRows += 1;
return true;
} else {
return false;
}
}
}
public RecordReader<LongWritable, NullWritable>
createRecordReader(InputSplit split, TaskAttemptContext context)
throws IOException {
return new RangeRecordReader();
}
/**
* Create the desired number of splits, dividing the number of rows
* between the mappers.
*/
public List<InputSplit> getSplits(JobContext job) {
long totalRows = getNumberOfRows(job);
int numSplits = job.getConfiguration().getInt(MRJobConfig.NUM_MAPS, 1);
LOG.info("Generating " + totalRows + " using " + numSplits);
List<InputSplit> splits = new ArrayList<InputSplit>();
long currentRow = 0;
for(int split = 0; split < numSplits; ++split) {
long goal =
(long) Math.ceil(totalRows * (double)(split + 1) / numSplits);
splits.add(new RangeInputSplit(currentRow, goal - currentRow));
currentRow = goal;
}
return splits;
}
}
static long getNumberOfRows(JobContext job) {
return job.getConfiguration().getLong(NUM_ROWS, 0);
}
static void setNumberOfRows(Job job, long numRows) {
job.getConfiguration().setLong(NUM_ROWS, numRows);
}
/**
* The Mapper class that given a row number, will generate the appropriate
* output line.
*/
public static class SortGenMapper
extends Mapper<LongWritable, NullWritable, Text, Text> {
private Text key = new Text();
private Text value = new Text();
private Unsigned16 rand = null;
private Unsigned16 rowId = null;
private Unsigned16 checksum = new Unsigned16();
private Checksum crc32 = new PureJavaCrc32();
private Unsigned16 total = new Unsigned16();
private static final Unsigned16 ONE = new Unsigned16(1);
private byte[] buffer = new byte[TeraInputFormat.KEY_LENGTH +
TeraInputFormat.VALUE_LENGTH];
private Counter checksumCounter;
public void map(LongWritable row, NullWritable ignored,
Context context) throws IOException, InterruptedException {
if (rand == null) {
rowId = new Unsigned16(row.get());
rand = Random16.skipAhead(rowId);
checksumCounter = context.getCounter(Counters.CHECKSUM);
}
Random16.nextRand(rand);
GenSort.generateRecord(buffer, rand, rowId);
key.set(buffer, 0, TeraInputFormat.KEY_LENGTH);
value.set(buffer, TeraInputFormat.KEY_LENGTH,
TeraInputFormat.VALUE_LENGTH);
context.write(key, value);
crc32.reset();
crc32.update(buffer, 0,
TeraInputFormat.KEY_LENGTH + TeraInputFormat.VALUE_LENGTH);
checksum.set(crc32.getValue());
total.add(checksum);
rowId.add(ONE);
}
@Override
public void cleanup(Context context) {
if (checksumCounter != null) {
checksumCounter.increment(total.getLow8());
}
}
}
private static void usage() throws IOException {
System.err.println("teragen <num rows> <output dir>");
}
/**
* Parse a number that optionally has a postfix that denotes a base.
* @param str an string integer with an option base {k,m,b,t}.
* @return the expanded value
*/
private static long parseHumanLong(String str) {
char tail = str.charAt(str.length() - 1);
long base = 1;
switch (tail) {
case 't':
base *= 1000 * 1000 * 1000 * 1000;
break;
case 'b':
base *= 1000 * 1000 * 1000;
break;
case 'm':
base *= 1000 * 1000;
break;
case 'k':
base *= 1000;
break;
default:
}
if (base != 1) {
str = str.substring(0, str.length() - 1);
}
return Long.parseLong(str) * base;
}
/**
* @param args the cli arguments
*/
public int run(String[] args)
throws IOException, InterruptedException, ClassNotFoundException {
Job job = Job.getInstance(getConf());
if (args.length != 2) {
usage();
return 2;
}
setNumberOfRows(job, parseHumanLong(args[0]));
Path outputDir = new Path(args[1]);
if (outputDir.getFileSystem(getConf()).exists(outputDir)) {
throw new IOException("Output directory " + outputDir +
" already exists.");
}
FileOutputFormat.setOutputPath(job, outputDir);
job.setJobName("TeraGen");
job.setJarByClass(TeraGen.class);
job.setMapperClass(SortGenMapper.class);
job.setNumReduceTasks(0);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setInputFormatClass(RangeInputFormat.class);
job.setOutputFormatClass(TeraOutputFormat.class);
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new TeraGen(), args);
System.exit(res);
}
}
TeraGen
TeraSort.java:
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.hadoop.examples.terasort;
import java.io.DataInputStream;
import java.io.IOException;
import java.io.PrintStream;
import java.net.URI;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.hadoop.conf.Configurable;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.JobContext;
import org.apache.hadoop.mapreduce.MRJobConfig;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* Generates the sampled split points, launches the job, and waits for it to
* finish.
* <p>
* To run the program:
* <b>bin/hadoop jar hadoop-*-examples.jar terasort in-dir out-dir</b>
*/
public class TeraSort extends Configured implements Tool {
private static final Log LOG = LogFactory.getLog(TeraSort.class);
static String SIMPLE_PARTITIONER = "mapreduce.terasort.simplepartitioner";
static String OUTPUT_REPLICATION = "mapreduce.terasort.output.replication";
/**
* A partitioner that splits text keys into roughly equal partitions
* in a global sorted order.
*/
static class TotalOrderPartitioner extends Partitioner<Text,Text>
implements Configurable {
private TrieNode trie;
private Text[] splitPoints;
private Configuration conf;
/**
* A generic trie node
*/
static abstract class TrieNode {
private int level;
TrieNode(int level) {
this.level = level;
}
abstract int findPartition(Text key);
abstract void print(PrintStream strm) throws IOException;
int getLevel() {
return level;
}
}
/**
* An inner trie node that contains 256 children based on the next
* character.
*/
static class InnerTrieNode extends TrieNode {
private TrieNode[] child = new TrieNode[256];
InnerTrieNode(int level) {
super(level);
}
int findPartition(Text key) {
int level = getLevel();
if (key.getLength() <= level) {
return child[0].findPartition(key);
}
return child[key.getBytes()[level] & 0xff].findPartition(key);
}
void setChild(int idx, TrieNode child) {
this.child[idx] = child;
}
void print(PrintStream strm) throws IOException {
for(int ch=0; ch < 256; ++ch) {
for(int i = 0; i < 2*getLevel(); ++i) {
strm.print(' ');
}
strm.print(ch);
strm.println(" ->");
if (child[ch] != null) {
child[ch].print(strm);
}
}
}
}
/**
* A leaf trie node that does string compares to figure out where the given
* key belongs between lower..upper.
*/
static class LeafTrieNode extends TrieNode {
int lower;
int upper;
Text[] splitPoints;
LeafTrieNode(int level, Text[] splitPoints, int lower, int upper) {
super(level);
this.splitPoints = splitPoints;
this.lower = lower;
this.upper = upper;
}
int findPartition(Text key) {
for(int i=lower; i<upper; ++i) {
if (splitPoints[i].compareTo(key) > 0) {
return i;
}
}
return upper;
}
void print(PrintStream strm) throws IOException {
for(int i = 0; i < 2*getLevel(); ++i) {
strm.print(' ');
}
strm.print(lower);
strm.print(", ");
strm.println(upper);
}
}
/**
* Read the cut points from the given sequence file.
* @param fs the file system
* @param p the path to read
* @param job the job config
* @return the strings to split the partitions on
* @throws IOException
*/
private static Text[] readPartitions(FileSystem fs, Path p,
Configuration conf) throws IOException {
int reduces = conf.getInt(MRJobConfig.NUM_REDUCES, 1);
Text[] result = new Text[reduces - 1];
DataInputStream reader = fs.open(p);
for(int i=0; i < reduces - 1; ++i) {
result[i] = new Text();
result[i].readFields(reader);
}
reader.close();
return result;
}
/**
* Given a sorted set of cut points, build a trie that will find the correct
* partition quickly.
* @param splits the list of cut points
* @param lower the lower bound of partitions 0..numPartitions-1
* @param upper the upper bound of partitions 0..numPartitions-1
* @param prefix the prefix that we have already checked against
* @param maxDepth the maximum depth we will build a trie for
* @return the trie node that will divide the splits correctly
*/
private static TrieNode buildTrie(Text[] splits, int lower, int upper,
Text prefix, int maxDepth) {
int depth = prefix.getLength();
if (depth >= maxDepth || lower == upper) {
return new LeafTrieNode(depth, splits, lower, upper);
}
InnerTrieNode result = new InnerTrieNode(depth);
Text trial = new Text(prefix);
// append an extra byte on to the prefix
trial.append(new byte[1], 0, 1);
int currentBound = lower;
for(int ch = 0; ch < 255; ++ch) {
trial.getBytes()[depth] = (byte) (ch + 1);
lower = currentBound;
while (currentBound < upper) {
if (splits[currentBound].compareTo(trial) >= 0) {
break;
}
currentBound += 1;
}
trial.getBytes()[depth] = (byte) ch;
result.child[ch] = buildTrie(splits, lower, currentBound, trial,
maxDepth);
}
// pick up the rest
trial.getBytes()[depth] = (byte) 255;
result.child[255] = buildTrie(splits, currentBound, upper, trial,
maxDepth);
return result;
}
public void setConf(Configuration conf) {
try {
FileSystem fs = FileSystem.getLocal(conf);
this.conf = conf;
Path partFile = new Path(TeraInputFormat.PARTITION_FILENAME);
splitPoints = readPartitions(fs, partFile, conf);
trie = buildTrie(splitPoints, 0, splitPoints.length, new Text(), 2);
} catch (IOException ie) {
throw new IllegalArgumentException("can't read partitions file", ie);
}
}
public Configuration getConf() {
return conf;
}
public TotalOrderPartitioner() {
}
public int getPartition(Text key, Text value, int numPartitions) {
return trie.findPartition(key);
}
}
/**
* A total order partitioner that assigns keys based on their first
* PREFIX_LENGTH bytes, assuming a flat distribution.
*/
public static class SimplePartitioner extends Partitioner<Text, Text>
implements Configurable {
int prefixesPerReduce;
private static final int PREFIX_LENGTH = 3;
private Configuration conf = null;
public void setConf(Configuration conf) {
this.conf = conf;
prefixesPerReduce = (int) Math.ceil((1 << (8 * PREFIX_LENGTH)) /
(float) conf.getInt(MRJobConfig.NUM_REDUCES, 1));
}
public Configuration getConf() {
return conf;
}
@Override
public int getPartition(Text key, Text value, int numPartitions) {
byte[] bytes = key.getBytes();
int len = Math.min(PREFIX_LENGTH, key.getLength());
int prefix = 0;
for(int i=0; i < len; ++i) {
prefix = (prefix << 8) | (0xff & bytes[i]);
}
return prefix / prefixesPerReduce;
}
}
public static boolean getUseSimplePartitioner(JobContext job) {
return job.getConfiguration().getBoolean(SIMPLE_PARTITIONER, false);
}
public static void setUseSimplePartitioner(Job job, boolean value) {
job.getConfiguration().setBoolean(SIMPLE_PARTITIONER, value);
}
public static int getOutputReplication(JobContext job) {
return job.getConfiguration().getInt(OUTPUT_REPLICATION, 1);
}
public static void setOutputReplication(Job job, int value) {
job.getConfiguration().setInt(OUTPUT_REPLICATION, value);
}
public int run(String[] args) throws Exception {
LOG.info("starting");
Job job = Job.getInstance(getConf());
Path inputDir = new Path(args[0]);
Path outputDir = new Path(args[1]);
boolean useSimplePartitioner = getUseSimplePartitioner(job);
TeraInputFormat.setInputPaths(job, inputDir);
FileOutputFormat.setOutputPath(job, outputDir);
job.setJobName("TeraSort");
job.setJarByClass(TeraSort.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setInputFormatClass(TeraInputFormat.class);
job.setOutputFormatClass(TeraOutputFormat.class);
if (useSimplePartitioner) {
job.setPartitionerClass(SimplePartitioner.class);
} else {
long start = System.currentTimeMillis();
Path partitionFile = new Path(outputDir,
TeraInputFormat.PARTITION_FILENAME);
URI partitionUri = new URI(partitionFile.toString() +
"#" + TeraInputFormat.PARTITION_FILENAME);
try {
TeraInputFormat.writePartitionFile(job, partitionFile);
} catch (Throwable e) {
LOG.error(e.getMessage());
return -1;
}
job.addCacheFile(partitionUri);
long end = System.currentTimeMillis();
System.out.println("Spent " + (end - start) + "ms computing partitions.");
job.setPartitionerClass(TotalOrderPartitioner.class);
}
job.getConfiguration().setInt("dfs.replication", getOutputReplication(job));
TeraOutputFormat.setFinalSync(job, true);
int ret = job.waitForCompletion(true) ? 0 : 1;
LOG.info("done");
return ret;
}
/**
* @param args
*/
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new TeraSort(), args);
System.exit(res);
}
}
TeraSort
作用:
TeraGen.java:用于产生数据
TeraSort.java:用于对数据排序
命令:
1. 产生数据:
bin/hadoop jar hadoop-examples-0.20.2-cdh3u6.jar teragen 10000000 /terasort/input1GB
teragen后的数值单位是行数;因为每行100个字节,所以如果要产生1G的数据量,则这个数值应为1G/100=10000000(7个0)
2. 排序:
bin/hadoop jar hadoop-examples-0.20.2-cdh3u6.jar terasort /terasort/input1GB /terasort/output1GB
生成数据示例:
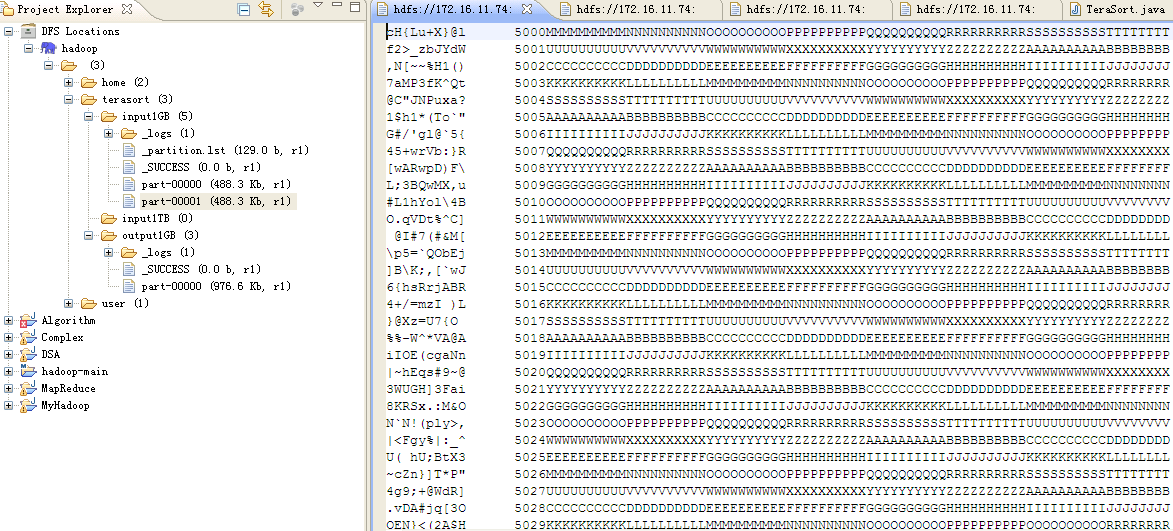
数据构成:
每行记录由3段组成:
前10个字节:随机binary code的十个字符,为key
中间10个字节:行id
后面80个字节:8段,每段10字节相同随机大写字母
TeraSort原理:
参考:
1. http://blog.csdn.net/leafy1980/article/details/6633828
2. http://dongxicheng.org/mapreduce/hadoop-terasort-analyse/