前言
在数据排序的算法中,不同数据规模应当使用合适的排序算法才能达到最好的效果,如小规模的数据排序,可以使用冒泡排序、插入排序,选择排序,他们的时间复杂度都为O(n2),大规模的数据排序就可以使用归并排序和快速排序,时间复杂度为O(nlogn)。今天我们就来看一下归并排序和快速排序。
正文
归并排序的原理
核心思想(分治思想):
排序数组,将数组从中间分成前后两部分,对前后两部分分别排序,然后合在一起,这个数组就是有序的。
归并排序的性能分析
1.归并排序是一个稳定的排序算法:在合并的过程中,如果A[p...q]和A[q+1...r]之间中有相同的元素,先把A[p...q]中的元素放入tmp数组。这样就保证了值相同的元素,在合并前后的先后顺序不变。
2.归并排序的时间复杂度是O(nlogn):在解决递归问题时,我们得出一个结论:递归问题可以写成递推公式,递归代码的时间复杂度也可以写成递推公式
我们假设对n个元素进行归并排序需要的时间是T(n),那分解成两个子数组排序的时间都是T(n/2),套用结论可以得到归并排序的时间复杂度的计算公式就是:
T(1) = C; n=1 时,只需要常量级的执行时间,所以表示为 C。
T(n) = 2*T(n/2) + n; n>1
再次将这个公式分解:
T(n) = 2*T(n/2) + n
= 2*(2*T(n/4) + n/2) + n = 4*T(n/4) + 2*n
= 4*(2*T(n/8) + n/4) + 2*n = 8*T(n/8) + 3*n
= 8*(2*T(n/16) + n/8) + 3*n = 16*T(n/16) + 4*n
......
= 2^k * T(n/2^k) + k * n
......
我们可以得到T(n)=2^kT(n/2^k)+kn.当T(n/2^k)=T(1)时,也就是n/2^k=1,我们将得到k=log2n,问你将k带入公式得到
T(n)=Cn+nlog2n
用大O标记法来表示为T(n) 就等于 O(nlogn)
而且时间复杂度是非常稳定的:最好情况,最坏情况,还是平均情况,时间复杂度都是O(nlogn)
3、归并排序的空间复杂度为O(n)
归并排序的致命缺点:归并排序不是原地排序算法(在合并两个有序数组时,需要借助额外的存储空间)
递归代码的空间复杂度并不能像时间复杂度那样累加、尽管每次合并操作都需要申请额外的内存空间,但在合并完成之后、临时开辟的内存空间就被释放掉了、临时内存空间最大也不会超过 n 个数据的大小
快速排序的原理
如果要排序数组中下标从p到r之间的一组数据,我们选择p到r之间的任意一个数据作为pivot(分区点),遍历数据,见小于pivot的放在右边,大于pivot放在左边。这样数组就分成了三部分,用递归排序下标从 p 到 q-1 之间的数据和下标从 q+1.到r之间的数据,直到区间缩小为1,说明数据都有序
快速排序的时间复杂度为O(1):在排序过程中,假如遇到需要移动数据的,我们可以之间用交换的思想
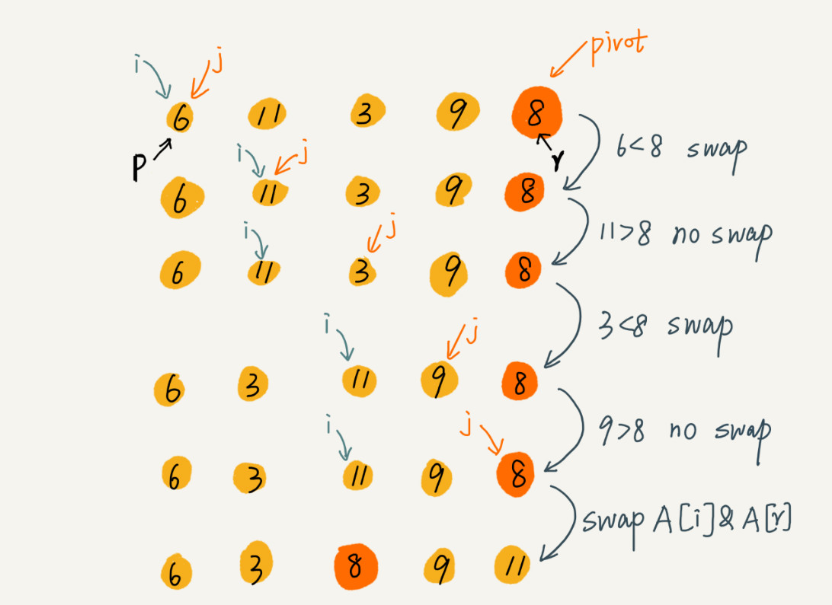
(图片来源于网络,侵删)
空间复杂度为O(1)
快速排序和归并排序的区别?
看图:
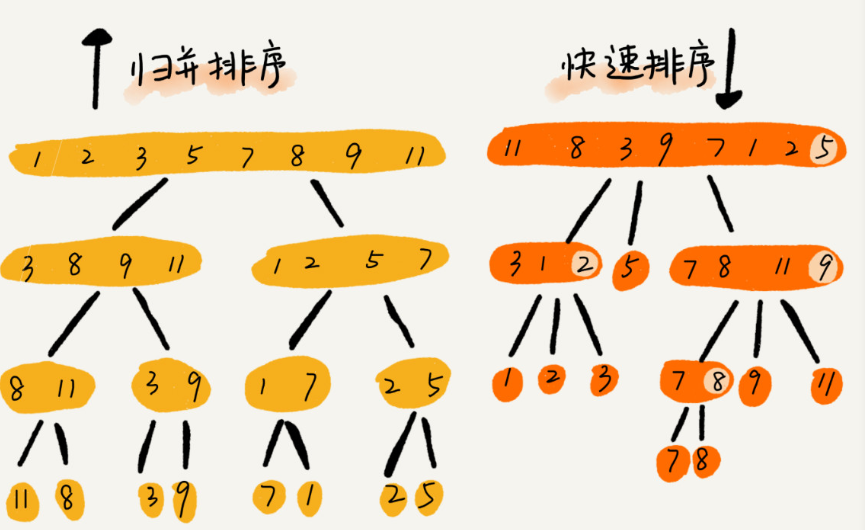
(图片来源于网络,侵删)
处理过程的差异:
递归排序:先处理子问题再合并
快速排序:先分区,再处理子问题
归并排序虽然稳定,是时间复杂度为O(nlogn)的排序算法,但是它不是原地排序算法,合并过程中需要额外的空间。
快速排序的性能分析
递归代码的时间复杂度,如果每次分区操作,都能正好将数组分为两个大小相等的两个小区间,那快速排序的递推公式和递推排序是相同的,所以,快排的时间复杂度为O(nlogn)
但是,每次都分得那么均匀是非常难实现的。
T(n)在大部分情况下的时间复杂度都可以做到O(nlogn),只有在极端情况下才会退化为O(n2).
后记
递归和快排都是分治的思想,代码都通过递归来实现,过程非常相似。归并排序时间复杂度都非常稳定为O(nlogn),但是每次合并的时候都需要额外的空间,空间复杂度非常高为是O(n),快速排序算法虽然最坏时间复杂度为O(n2),但是平均时间复杂度为O(nlogn),最坏的情况我们也可以避免。
相关文章
数据结构与算法学习笔记之如何分析一个排序算法?
以上内容为个人的学习笔记,仅作为学习交流之用。

欢迎大家关注公众号,不定时干货,只做有价值的输出