一、前言
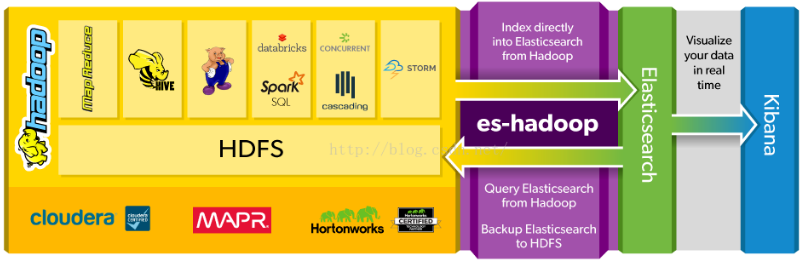
ES-Hadoop 是连接快速查询和大数据分析的桥梁,它能够无间隙的在 Hadoop 和 ElasticSearch 上移动数据。ES Hadoop索引 Hadoop 数据到 Elasticsearch,充分利用其查询速度,大量聚合能力来使它比以往更快,同时可以使用 HDFS 作为 Elasticsearch 长期存档。ES-Hadoop可以本地集成 Hadoop 生态系统上的很多流行组件,比如 Spark、Storm、Hive、Pig、Storm、MapReduce等。
ES-Hadoop 与大数据的关系图
首先需要在机器上配置 SSH 免密登录,此处不再讲解。
二、安装 Hadoop
2.1 Hadoop 的三种模式
Hadoop 主要分为三种安装模式,分别为:单机模式、伪分布式模式和完全分布式模式。下面以伪分布式模式为例。
1)单机(非分布式)模式
这种模式在一台单机上运行,没有分布式文件系统,而是直接读写本地操作系统的文件系统。
2)伪分布式运行模式
这种模式也是在一台单机上运行,但用不同的Java进程模仿分布式运行中的各类结点: (NameNode,DataNode,JobTracker,TaskTracker,SecondaryNameNode)
请注意分布式运行中的这几个结点的区别:
从分布式存储的角度来说,集群中的结点由一个NameNode和若干个DataNode组成,另有一个SecondaryNameNode作为NameNode的备份。
从分布式应用的角度来说,集群中的结点由一个JobTracker和若干个TaskTracker组成,JobTracker负责任务的调度,TaskTracker负责并行执行任务。TaskTracker必须运行在DataNode上,这样便于数据的本地计算。JobTracker和NameNode则无须在同一台机器上。一个机器上,既当 namenode,又当 datanode,或者说既是 jobtracker,又是tasktracker。没有所谓的在多台机器上进行真正的分布式计算,故称为 "伪分布式"。
3)完全分布式模式
真正的分布式,由3个及以上的实体机或者虚拟机组件的机群。
2.2 下载 Hadoop
Apache Hadoop 官方下载地址为:http://apache.org/dist/hadoop/common/,或者访问所有历史版本地址:http://archive.apache.org/dist/hadoop/common/
此处选择 2.9.1 版本,下载并解压,如下:
[root@masternode software]# tar zxvf /usr/software/hadoop-2.9.1.tar.gz -C /opt/hadoop [root@masternode software]# chown -R esuser:esuser /opt/hadoop
2.3 配置 Hadoop
hadoop 包括的配置文件主要有:hadoop-env.sh、core-site.xml、yarn-site.xml、mapred-site.xml、hdfs-site.xml 等均位于 /opt/hadoop/hadoop-2.9.1/etc/hadoop 目录下。
修改 hadoop-env.sh,添加 JAVA_HOME,如下:
[esuser@masternode hadoop]$ vim /opt/hadoop/hadoop-2.9.1/etc/hadoop/hadoop-env.sh export JAVA_HOME=/opt/jdk/jdk1.8.0_16
在集群环境下,即使各结点在 /etc/profile 中都正确地配置了JAVA_HOME,也会报如下错误:
localhost: Error: JAVA_HOME is not set and could not be found.
在hadoop-env.sh中,再显示地重新声明一遍JAVA_HOME
修改 /etc/profile 系统环境变量,添加 Hadoop 变量,如下:
[root@masternode hadoop-2.9.1]# vim /etc/profile
添加 Hadoop_HOME,如下:
#Hadoop variables export HADOOP_HOME=/opt/hadoop/hadoop-2.9.1 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
是配置文件生效(只对当前 Bash 生效),如下:
[root@masternode hadoop-2.9.1]# source /etc/profile
修改 core-site.xml,添加如下配置:
<configuration> <property> <name>hadoop.tmp.dir</name> <value>/opt/hadoop/hadoop-2.9.1/hdfs/tmp</value> </property> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration>
属性名 fs.default.name 已经废弃,使用新的 fs.defaultFS 来代替。fs.defaultFS 保存了 NameNode 的位置,HDFS 和 MapReduce 组件都需要使用到。
修改 mapred-site.xml,如下:
先从模板复制一份配置文件
[esuser@masternode hadoop]$ cp /opt/hadoop/hadoop-2.9.1/etc/hadoop/mapred-site.xml.template /opt/hadoop/hadoop-2.9.1/etc/hadoop/mapred-site.xml
再添加如下配置
<configuration> <property> <name>mapred.job.tracker</name> <value>localhost:9010</value> </property> </configuration>
变量 mapred.job.tracker 保存了 JobTracker 的位置,MapReduce 组件需要知道这个位置。
修改 hdfs-site.xml,添加如下配置,如下:
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
变量 dfs.replication 制定了每个 HDFS 数据文件的副本次数,默认为 3,此处修改为 1。
#并在hdfs-site.xml添加: #name: <property> <name>dfs.namenode.name.dir</name> <value>file://${hadoop.tmp.dir}/dfs/name</value> #专门针对name的路径设置,不放在默认的路径下,可以指定我们的默认物理磁盘 <description>确定本地文件系统上DFS名称节点的位置应该存储名称表(fsimage)。 如果这是一个以逗号分隔的列表的目录,然后名称表被复制到所有的目录中,以实现冗余。</description> </property> #data: <property> <name>dfs.datanode.data.dir</name> <value>file://${hadoop.tmp.dir}/dfs/data</value> <description>确定本地文件系统上DFS数据节点的位置应该存储它的块。如果这是逗号分隔的目录列表,然后数据将被存储在所有命名目录,通常在不同的设备上。目录应该被标记与HDFS对应的存储类型([SSD] / [磁盘] / [存档] / [RAM_DISK])存储政策。 如果目录不存在,则默认存储类型为DISK没有明确标记的存储类型。 不存在的目录将如果本地文件系统权限允许,则创建它。</description> </property>
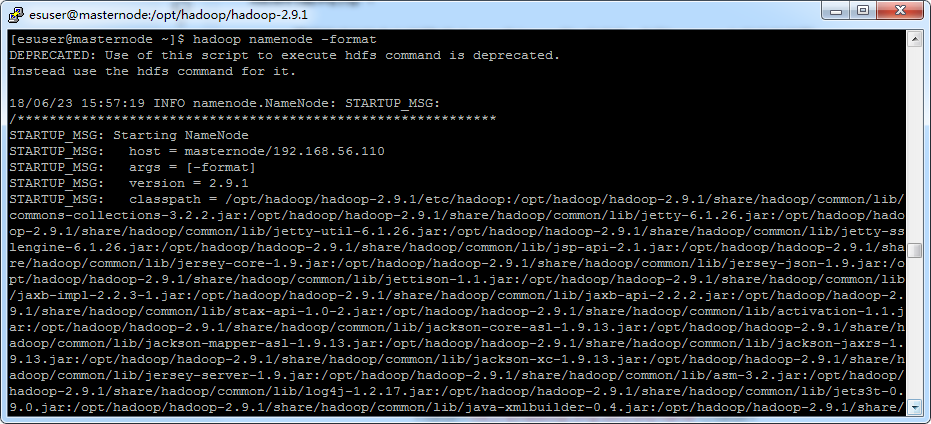
启动 Hadoop 之前,首先格式化 namenode,如下:
[esuser@masternode ~]$ hadoop namenode -format
显示如下:
2.4 启动 Hadoop
执行 start-all.sh 脚本和先执行 star-dfs.sh 再执行 start-yarn.sh 是一样的。
格式化完成之后,启动 Hadoop,命令如下:
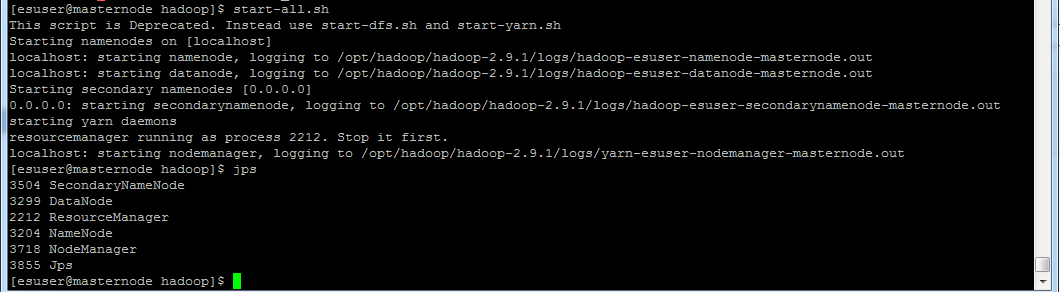
[esuser@masternode hadoop]$ start-all.sh This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh Starting namenodes on [localhost] localhost: starting namenode, logging to /opt/hadoop/hadoop-2.9.1/logs/hadoop-esuser-namenode-masternode.out localhost: starting datanode, logging to /opt/hadoop/hadoop-2.9.1/logs/hadoop-esuser-datanode-masternode.out Starting secondary namenodes [0.0.0.0] 0.0.0.0: starting secondarynamenode, logging to /opt/hadoop/hadoop-2.9.1/logs/hadoop-esuser-secondarynamenode-masternode.out starting yarn daemons resourcemanager running as process 2212. Stop it first. localhost: starting nodemanager, logging to /opt/hadoop/hadoop-2.9.1/logs/yarn-esuser-nodemanager-masternode.out
使用 jps 命令查看 JVM 进程,如下:
[esuser@masternode hadoop]$ jps 3504 SecondaryNameNode 3299 DataNode 2212 ResourceManager 3204 NameNode 3718 NodeManager 3855 Jps
正常情况下会看到 NameNode、Nodemanager、ResourceManager、DataNode 和 SecondaryNameNode,就说明已经启动成功了。
三、安装 ES-Hadoop
ES-Hadoop 所有版本下载地址:https://www.elastic.co/downloads/past-releases,找到 ES-Hadoop 5.6.0 版本下载,需要与 Elasticsearch 5.6.0 的版本相互对应一致,下载并解压到 /opt 目录下。
ES-Hadoop是一个 jar 包,工作在 hadoop 这边,ES 这边不需要安装。
在 /etc/profile 中添加环境变量:
#ESHADOOP_HOME variables
export ESHADOOP_HOME=/opt/elasticsearch-hadoop-5.6.0
export CLASSPATH=$CLASSPATH:$ESHADOOP_HOME/dist
四、从 HDFS 到 Elasticsearch
首先将 blog.json 上传到 HDFS,使用如下命令:
hadoop fs -put blog.json /work
#或者
hdfs dfs -put blog.json /work
blog.json 的内容为:
{"id":"1","title":"git简介","posttime":"2016-06-11","content":"svn与git的最主要区别..."}
{"id":"2","title":"ava中泛型的介绍与简单使用","posttime":"2016-06-12","content":"基本操作:CRUD ..."}
{"id":"3","title":"SQL基本操作","posttime":"2016-06-13","content":"svn与git的最主要区别..."}
{"id":"4","title":"Hibernate框架基础","posttime":"2016-06-14","content":"Hibernate框架基础..."}
{"id":"5","title":"Shell基本知识","posttime":"2016-06-15","content":"Shell是什么..."}
编写程序:
package com.es.hd; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.BytesWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.elasticsearch.hadoop.mr.EsOutputFormat; import java.io.IOException; public class HdfsToES { public static class MyMapper extends Mapper<Object, Text, NullWritable, BytesWritable> { public void map(Object key, Text value, Mapper<Object, Text, NullWritable, BytesWritable>.Context context) throws IOException, InterruptedException { byte[] line = value.toString().trim().getBytes(); BytesWritable blog = new BytesWritable(line); context.write(NullWritable.get(), blog); } } public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration conf = new Configuration(); conf.setBoolean("mapred.map.tasks.speculative.execution", false); conf.setBoolean("mapred.reduce.tasks.speculative.execution", false); conf.set("es.nodes", "192.168.56.110:9200"); conf.set("es.resource", "blog/cnblogs"); conf.set("es.mapping.id", "id"); conf.set("es.input.json", "yes"); Job job = Job.getInstance(conf, "hadoop es write test"); job.setMapperClass(HdfsToES.MyMapper.class); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(EsOutputFormat.class); job.setMapOutputKeyClass(NullWritable.class); job.setMapOutputValueClass(BytesWritable.class); FileInputFormat.setInputPaths(job, new Path("hdfs://localhost:9000//work/blog.json")); job.waitForCompletion(true); } }
五、从 Elasticsearch 到 HDFS
5.1 读取索引到 HDFS
读取 Elasticsearch 一个类型中的全部数据到 HDFS,这里读取索引为 blog 类型为 cnblogs 的所有文档,如下:
package com.es.hd; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.io.Writable; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.elasticsearch.hadoop.mr.EsInputFormat; import java.io.IOException; public class EsToHDFS { public static class MyMapper extends Mapper<Writable, Writable, NullWritable, Text> { @Override protected void map(Writable key, Writable value, Context context) throws IOException, InterruptedException { Text text = new Text(); text.set(value.toString()); context.write(NullWritable.get(), text); } } public static void main(String[] args) throws Exception { Configuration configuration = new Configuration(); configuration.set("es.nodes", "192.168.56.110:9200"); configuration.set("es.resource", "blog/cnblogs"); configuration.set("es.output.json", "true"); Job job = Job.getInstance(configuration, "hadoop es write test"); job.setMapperClass(MyMapper.class); job.setNumReduceTasks(1); job.setMapOutputKeyClass(NullWritable.class); job.setMapOutputValueClass(Text.class); job.setInputFormatClass(EsInputFormat.class); FileOutputFormat.setOutputPath(job, new Path("hdfs://localhost:9000/work/blog_cnblogs")); job.waitForCompletion(true); } }
5.2 查询 Elasticsearch 写入 HDFS
可以穿入查询条件对 Elastticsearch 中的文档进行搜索,再把文档查询结果写入 HDFS。这里查询 title 中含有关键词 git 的文档,如下:
package com.es.hd; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.io.Writable; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.elasticsearch.hadoop.mr.EsInputFormat; import java.io.IOException; public class EsQueryToHDFS { public static class MyMapper extends Mapper<Writable, Writable, Text, Text> { @Override protected void map(Writable key, Writable value, Context context) throws IOException, InterruptedException { context.write(new Text(key.toString()), new Text(value.toString())); } } public static void main(String[] args) throws Exception { Configuration configuration = new Configuration(); configuration.set("es.nodes", "192.168.56.110:9200"); configuration.set("es.resource", "blog/cnblogs"); configuration.set("es.output.json", "true"); configuration.set("es.query", "?q=title:git"); Job job = Job.getInstance(configuration, "query es to HDFS"); job.setMapperClass(MyMapper.class); job.setNumReduceTasks(1); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); job.setInputFormatClass(EsInputFormat.class); FileOutputFormat.setOutputPath(job, new Path("hdfs://localhost:9000/work/es_query_to_HDFS")); job.waitForCompletion(true); } }