注:本文是人工智能研究网的学习笔记
sklearn.feature_extaction模块提供了从原始数据如文本,图像等中抽取能够被机器学习算法直接处理的特征向量。
Feature extraction和Feature selection是不同的:前者将任意的数据变换成机器学习算法可用的数值型特征;后者是一个作用于特征空间上的机器学习技术,是对特征空间的再次变换。

- Loading Features From Dicts
- Features hashing
- Text Feature Extraction
- Image Feature Extraction
Loading Features From Dicts
DictVectorizer类可以用来把标准Python dict对象表示的特征数组转换成Numpy/Scipy的表示形式,以便于scikit-learn estimators的使用。
尽管速度不是很快,Python的dict使用起来还是相当方便的,而且还可以稀疏存储(absent feature need not be stored);字典的形式便于将特征的取值和名称一一对应起来。
DictVectorizer实现了one-of-K或者叫“one-hot”编码对标称型特征。标称型特征(Categorical feature)是“attribute-value”pairs,其中value是属性的可能的取值列表,必须是有限的离散的没有大小顺序的。(e.g 男女,话题类别)
下面的例子中,‘city’是一个categorical attribute而‘temperature’是一个典型的numerical feature。
measurements = [
{'city': 'Dubai', 'temperature': 33.0},
{'city': 'London', 'temperature': 12.0},
{'city': 'San Fransisco', 'temperature': 18.0},
]
from sklearn.feature_extraction import DictVectorizer
vec = DictVectorizer()
print(vec.fit_transform(measurements).toarray())
print(vec.get_feature_names())

Features hashing
Features hashing是一个高速的,低存储的向量化的类。
一般的vectorizer是为训练过程中遇到的特征构建一个hash table,而FeatureHasher类则直接对特征应用一个hash函数来决定特征在样本矩阵中的列索引。这样的做法使得计算速度提升并且节省了内存,the hasher无法记住输入特征的样子,而且不逊在你想变换操作:inverse_transform。
因为哈希函数可能会导致本来不相关的特征之间发生冲突,所以使用了有符号的hash函数。对一个特征,其hash值的符号决定了被存储到输出矩阵中的值的符号。通过这种方式就能够消除特征hash映射时发生的冲突而不是累计冲突。而且任意输出的值的期望均值是0.
如果non_negative=True被传入构造函数,将会取绝对值。这样会发生一些冲突(collision)但是哈希特征映射的输出就可以被传入到一些只能接受非负特征的学习器对象比如:
sklearn.naive_bayes.MultinomialNB分类器和sklearn.feature_selection.chi2特征选择器。
Features hashing接受参数类型可以使:mappings(字典或者其变体容器)或者(feature,value)对,或者strings。这取决于构造器参数:input_type。
Mapping被看做是由(feature,value)构成的一个列表,而单个字符串隐式的等于1,所以['feat1', 'feat2', 'feat3']被解释成(feature,value)的列表:[('feat1', 1), ('feat2',2), ('feat3', 3)]。 如果一个特征在一个样本中出现了多次,相关联的值就会累加起来:(比如('feat', 2)和('feat', 3.5)会累计起来成为('feat', 5.5))。
FeatureHasher的输出通常是CSR格式的scipy.sparse matrix。
Feature hashing 可被用于文档分类中去,但是与text.CountVectorizer不同,FeatureHasher不做单词切分或其他的预处理操作,除了Unicode-to-UTF-8编码以外。
Text Feature Extraction
- The Bag of Words represention 词袋模型
- Sparsity
- Common Vectorizer usage
- TF-idf term weighting
- Decoding text files
- Limitations of the Bag of Words represention 词袋模型的局限性
- Vertorizing a large text corpus with the hashing trick
- Performing out-of-core scaling with HashingVectorizer
- Customizing the vectorizer classes
The Bag of Words represention

Sparsity

Common Vectorizer usage
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer(min_df=1)
print(vectorizer)
corpus = [
'This is the first documents.',
'This is the second documents.',
'And the third document.',
'Is this the first documents?',
]
X = vectorizer.fit_transform(corpus)
print(X)
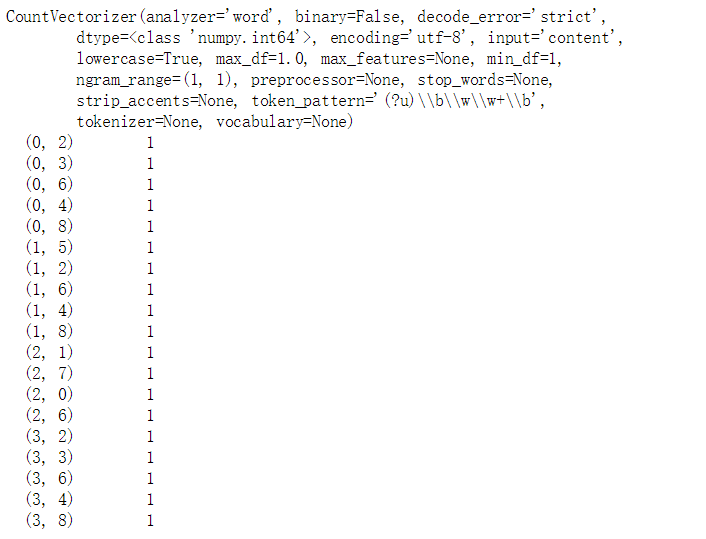
在默认的设置中,提取的字符串长度至少要有两个字符,低于两个字符的会被忽略,比如'a'
analyze = vectorizer.build_analyzer()
analyze('This is a text document to analyze.') == (['this', 'is', 'text', 'document', 'to', 'analyze'])

在fit阶段被analyser发现的每一个词语(term)都会被分配一个独特的整数索引(unique interger index), 该索引对应于特征向量矩阵中的一列,全部小写化。
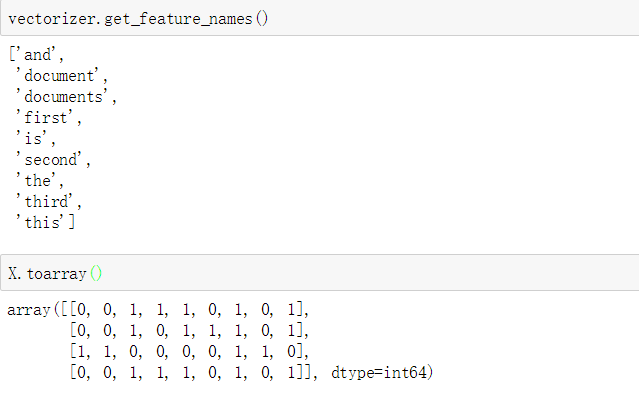
使用下面的方法获取某一个词语在矩阵中的第几列。

因此,在训练语料中没有见到过的单词将会被未来的转换方法完全忽略。