这题里想读取index.php只能一行一行的读,通过控制line参数的值。如下:


正常的writeup都是写个爬虫,但我觉得burp肯定有自带这种功能,不用重造轮子。经过学习后发现以下步骤可以实现。
1. 抓包,发到intruder,给line添加$
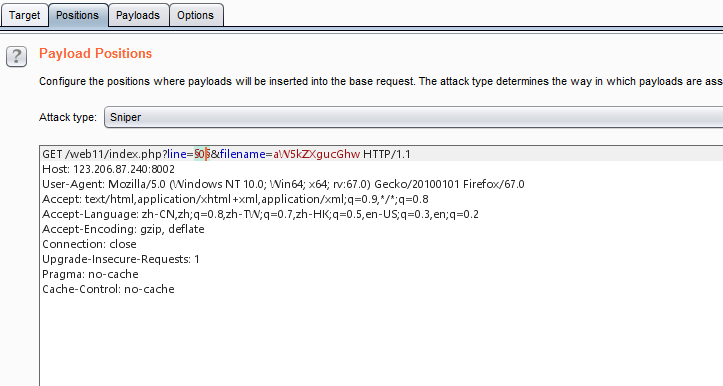
2.payloads当然设成number
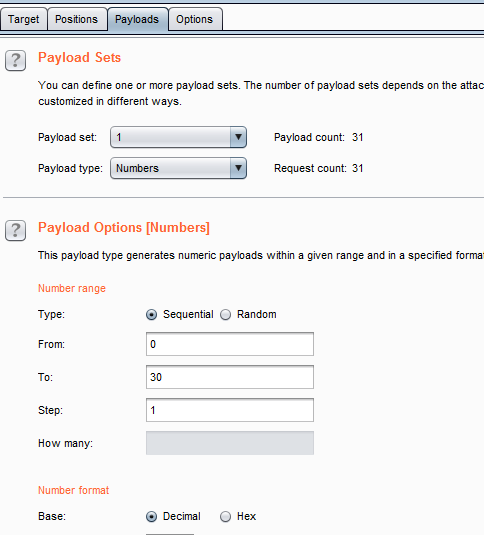
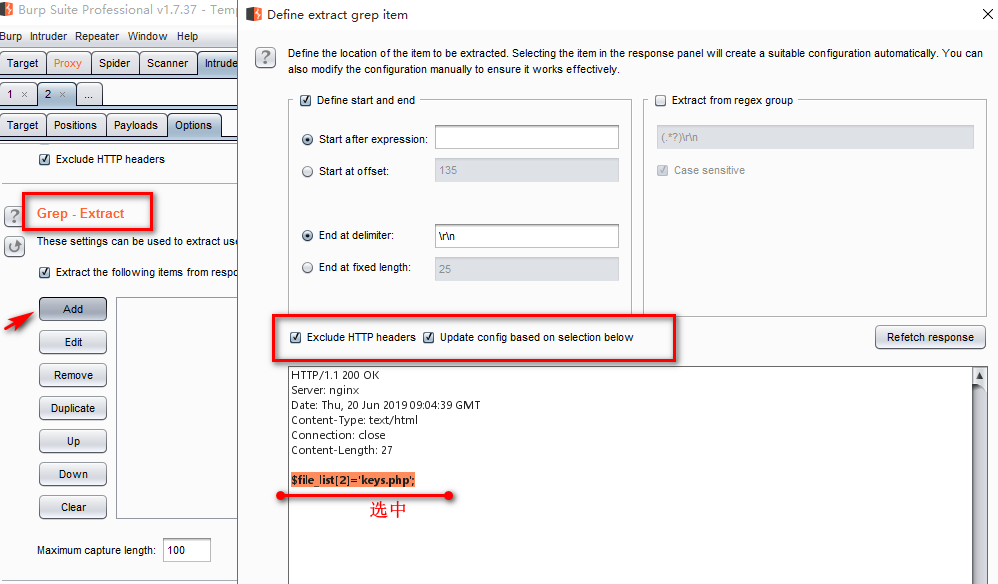
3. 重点:在options里的Grep- Extract里,点击add,勾选exclude HTTP headers(排除请求头),另一个是默认勾选,然后下面选中你需要的内容,上面的start和end就会自动设置好。
4.然后点击最上面的开始攻击,攻击结果就会单独显示咱们筛选的内容:

5.这样还没完,因为通常咱们需要把那一列保存到一个文件后续编辑。点击最上面的save->result table
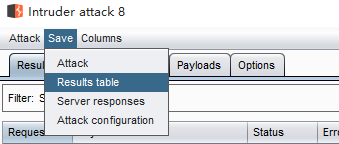
在下面勾选竖行的名字,点击save。我这里名字是 。这样就会输出一个文件,只包括这个列。

--------------------------------
end