slice
Slice(切片)代表变长的序列,序列中每个元素都有相同的类型。一个slice类型一般写作[]T,其中T代表slice中元素的类型;slice的语法和数组很像,只是没有固定长度而已。
一个slice由三个部分构成:指针、长度和容量。指针指向第一个slice元素对应的底层数组元素的地址,要注意的是slice的第一个元素并不一定就是数组的第一个元素。长度对应slice中元素的数目;长度不能超过容量,容量一般是从slice的开始位置到底层数据的结尾位置。内置的len和cap函数分别返回slice的长度和容量。
slice的切片操作s[i:j],其中0 ≤ i≤ j≤ cap(s),用于创建一个新的slice,引用s的从第i个元素开始到第j-1个元素的子序列。新的slice将只有j-i个元素。如果i位置的索引被省略的话将使用0代替,如果j位置的索引被省略的话将使用len(s)代替。
slice唯一合法的比较操作是和nil比较,例如:
if summer == nil { /* ... */ }
一个零值的slice等于nil。一个nil值的slice并没有底层数组。一个nil值的slice的长度和容量都是0,但是也有非nil值的slice的长度和容量也是0的,例如[]int{}或make([]int, 3)[3:]
内置的make函数创建一个指定元素类型、长度和容量的slice。容量部分可以省略,在这种情况下,容量将等于长度。
make([]T, len) make([]T, len, cap) // same as make([]T, cap)[:len]
每次调用appendint函数,必须先检测slice底层数组是否有足够的容量来保存新添加的元素。如果有足够空间的话,直接扩展slice(依然在原有的底层数组之上),将新添加的y元素复制到新扩展的空间,并返回slice。因此,输入的x和输出的z共享相同的底层数组。
如果没有足够的增长空间的话,appendInt函数则会先分配一个足够大的slice用于保存新的结果,先将输入的x复制到新的空间,然后添加y元素。结果z和输入的x引用的将是不同的底层数组
func main() { var x, y []int for i := 0; i < 10; i++ { y = appendInt(x, i) fmt.Printf("%d cap=%d %v ", i, cap(y), y) x = y } }
0 cap=1 [0] 1 cap=2 [0 1] 2 cap=4 [0 1 2] 3 cap=4 [0 1 2 3] 4 cap=8 [0 1 2 3 4] 5 cap=8 [0 1 2 3 4 5] 6 cap=8 [0 1 2 3 4 5 6] 7 cap=8 [0 1 2 3 4 5 6 7] 8 cap=16 [0 1 2 3 4 5 6 7 8] 9 cap=16 [0 1 2 3 4 5 6 7 8 9]
内置的append函数可能使用比appendInt更复杂的内存扩展策略。因此,通常我们并不知道append调用是否导致了内存的重新分配,因此我们也不能确认新的slice和原始的slice是否引用的是相同的底层数组空间。同样,我们不能确认在原先的slice上的操作是否会影响到新的slice。因此,通常是将append返回的结果直接赋值给输入的slice变量:
runes = append(runes, r)
Slice内存修改
一个slice可以用来模拟一个stack。最初给定的空slice对应一个空的stack,然后可以使用append函数将新的值压入stack:
stack = append(stack, v) // push v
stack的顶部位置对应slice的最后一个元素:
top := stack[len(stack)-1] // top of stack
通过收缩stack可以弹出栈顶的元素
stack = stack[:len(stack)-1] // pop
要删除slice中间的某个元素并保存原有的元素顺序,可以通过内置的copy函数将后面的子slice向前依次移动一位完成:
func remove(slice []int, i int) []int { copy(slice[i:], slice[i+1:]) return slice[:len(slice)-1] } func main() { s := []int{5, 6, 7, 8, 9} fmt.Println(remove(s, 2)) // "[5 6 8 9]" }
- 内置的copy函数可以方便地将一个slice复制另一个相同类型的slice。copy函数的第一个参数是要复制的目标slice,第二个参数是源slice,目标和源的位置顺序和
dst = src赋值语句是一致
如果删除元素后不用保持原来顺序的话,我们可以简单的用最后一个元素覆盖被删除的元素:
func remove(slice []int, i int) []int { slice[i] = slice[len(slice)-1] return slice[:len(slice)-1] } func main() { s := []int{5, 6, 7, 8, 9} fmt.Println(remove(s, 2)) // "[5 6 9 8] }
map
散列表是个用途比较广泛的结构,是一个拥有键值对的无序集合,这个集合中 键的值是唯一的;
Go语言中,一个map就是一个散列表的引用,map类型可以写为map[K]V,其中K和V分别对应key和value。map中所有的key都有相同的类型,所有的value也有着相同的类型,但是key和value之间可以是不同的数据类型。其中K对应的key必须是支持==比较运算符的数据类型,所以map可以通过测试key是否相等来判断是否已经存在。虽然浮点数类型也是支持相等运算符比较的,但是将浮点数用做key类型则是一个坏的想法,对于V对应的value数据类型则没有任何的限制。
内置的make函数可以创建一个map:
ages := make(map[string]int) // mapping from strings to ints
也可以使用如下方式初始化
ages := map[string]int{ "alice": 31, "charlie": 34, }
这相当于:
ages := make(map[string]int) ages["alice"] = 31 ages["charlie"] = 34
所以,另一种创建空的map的表达式是
map[string]int{}
Map中的元素通过key对应的下标语法访问:
ages["alice"] = 32 fmt.Println(ages["alice"]) // "32"
使用内置的delete函数可以删除元素:
delete(ages, "alice") // remove element ages["alice"]
Map的迭代顺序是不确定的,并且不同的哈希函数实现可能导致不同的遍历顺序。在实践中,遍历的顺序是随机的,每一次遍历的顺序都不相同。这是故意的,每次都使用随机的遍历顺序可以强制要求程序不会依赖具体的哈希函数实现。如果要按顺序遍历key/value对,我们必须显式地对key进行排序,可以使用sort包的Strings函数对字符串slice进行排序
import "sort" var names []string for name := range ages { names = append(names, name) } sort.Strings(names) for _, name := range names { fmt.Printf("%s %d ", name, ages[name]) }
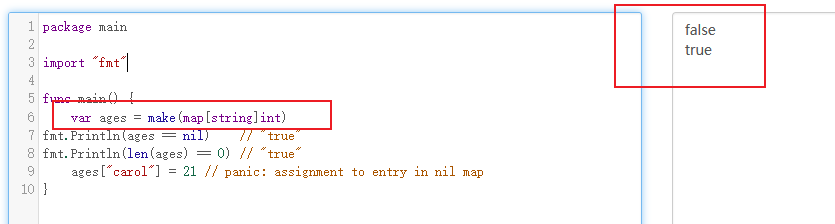
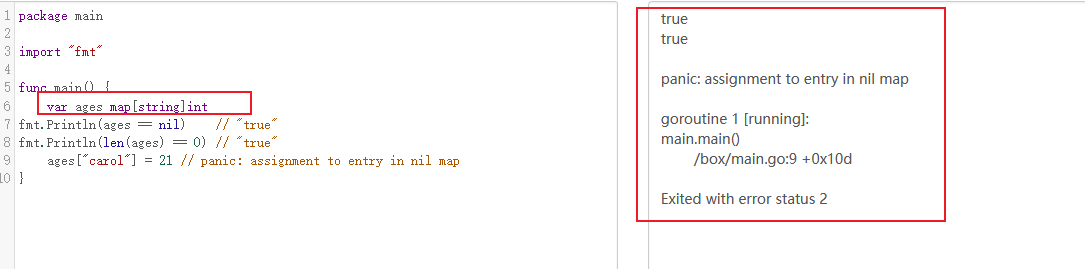
map类型的零值是nil,也就是没有引用任何哈希表
var ages map[string]int fmt.Println(ages == nil) // "true" fmt.Println(len(ages) == 0) // "true"
map上的大部分操作,包括查找、删除、len和range循环都可以安全工作在nil值的map上,它们的行为和一个空的map类似。但是向一个nil值的map存入元素将导致一个panic异常:
在向map存数据前必须先创建map。
通过key作为索引下标来访问map将产生一个value。如果key在map中是存在的,那么将得到与key对应的value;如果key不存在,那么将得到value对应类型的零值,正如我们前面看到的ages["bob"]那样。这个规则很实用,但是有时候可能需要知道对应的元素是否真的是在map之中。例如,如果元素类型是一个数字,你可能需要区分一个已经存在的0,和不存在而返回零值的0,可以像下面这样测试:
age, ok := ages["bob"] if !ok { /* "bob" is not a key in this map; age == 0. */ }
在这种场景下,map的下标语法将产生两个值;第二个是一个布尔值,用于报告元素是否真的存在。布尔变量一般命名为ok,特别适合马上用于if条件判断部分。