Memcache作为内存cache服务器,内存高效管理是其最重要的任务之一,Memcached使用SLAB管理其内存!!
记住 从内存池里面连续的地址 获取一小块内存地址时 需要注意 地址对其问题; 一般 CHUNK_ALIGN_BYTES = 8 or 16
原因和CPU处理内存方式有关,考虑到CPU,一个时钟周期可以读取4个连续的内存单元,即4字节),使用字节对齐将会提高系统的性能(也就是CPU就需要两次。但对齐之后一次就可以了)。
实际上,malloc一般使用当前平台默认的最大内存对齐数对齐内存。比如MSVC在32位下一般是8字节对齐;64位下则是16字节,可以参考:MSVC
当我们需要分配一块具有特定内存对齐的内存块时,在MSVC下应当使用_aligned_malloc;而在gcc下一般使用memalign等函数
看下 memcached 的核心数据结构
/** * Structure for storing items within memcached. */ typedef struct _stritem { //next指针,用于LRU链表 struct _stritem *next; //prev指针,用于LRU链表 struct _stritem *prev; //h_next指针,用于哈希表的冲突链 struct _stritem *h_next; /* hash chain next */ //最后一次访问时间。绝对时间 lru队列里面的item是根据time降序排序的 rel_time_t time; /* least recent access */ //过期失效时间,绝对时间 一个item在两种情况下会过期失效:1.item的exptime时间戳到了。2.用户使用flush_all命令将全部item变成过期失效的 rel_time_t exptime; /* expire time */ //本item存放的数据的长度 nbytes是算上了 字符的,见do_item_alloc外层 参考item_make_header中的 int nbytes; /* size of data */ /* 可以看到,这是因为减少一个item的引用数可能要删除这个item。为什么呢?考虑这样的情景,线程A因为要读一个item而增加了这个item的 引用计数,此时线程B进来了,它要删除这个item。这个删除命令是肯定会执行的,而不是说这个item被别的线程引用了就不执行删除命令。 但又肯定不能马上删除,因为线程A还在使用这个item,此时memcached就采用延迟删除的做法。线程B执行删除命令时减多一次item的引用数, 使得当线程A释放自己对item的引用后,item的引用数变成0。此时item就被释放了(归还给slab分配器)。 */ //本item的引用数 在使用do_item_remove函数向slab归还item时,会先测试这个item的引用数是否等于0。 //引用数可以简单理解为是否有worker线程在使用这个item 记录这个item被引用(被worker线程占用)的总数 unsigned short refcount; //在do_item_link中增加 //新开盘的默认初值为1 //后缀长度, (nkey + *nsuffix + nbytes)中的nsuffix 参考item_make_header中的 uint8_t nsuffix; /* length of flags-and-length string */ //item的属性 是否使用cas,settings.use_cas // item的三种flag: ITEM_SLABBED, ITEM_LINKED,ITEM_CAS uint8_t it_flags; /* ITEM_* above */ //该item是从哪个slabclass获取得到 uint8_t slabs_clsid;/* which slab class we're in */ //键值的长度 实际上真实用到的内存是nkey+1,见do_item_alloc 参考item_make_header中的 uint8_t nkey; /* key length, w/terminating null and padding */ /* this odd type prevents type-punning issues when we do * the little shuffle to save space when not using CAS. */ union { //ITEM_set_cas 只有在开启settings.use_cas才有用 //ITEM_set_cas get_cas_id ITEM_get_cas 每次读取完数据部分后,存储到item中后,stored的时候都会调用do_store_item自增 uint64_t cas; //参考process_update_command中的req_cas_id,实际是从客户端的set等命令中获取到的 char end; } data[]; //+ DATA 这后面的就是实际数据 (nkey + *nsuffix + nbytes) 参考item_make_header /* if it_flags & ITEM_CAS we have 8 bytes CAS */ /* then null-terminated key */ /* then " flags length " (no terminating null) */ /* then data with terminating (no terminating null; it's binary!) */ } item;
主要由 item的属性说明信息和item的数据部分组成,属性信息解释如上,数据部分包括cas,key和真实的value信息


转载自https://blog.csdn.net/unix21/article/details/8572529
http://blog.csdn.net/luotuo44/article/details/42913549


插入数据流程:
在Memcached中插入数据主要分为以下几个流程:ps 已经使用的item 使用hashtable+list 维护
1.哈希查找是否存在相同键值
2.根据item大小选择slab class
3.从过期item或空闲链表中分配item
4.加入LRU链表及哈希表
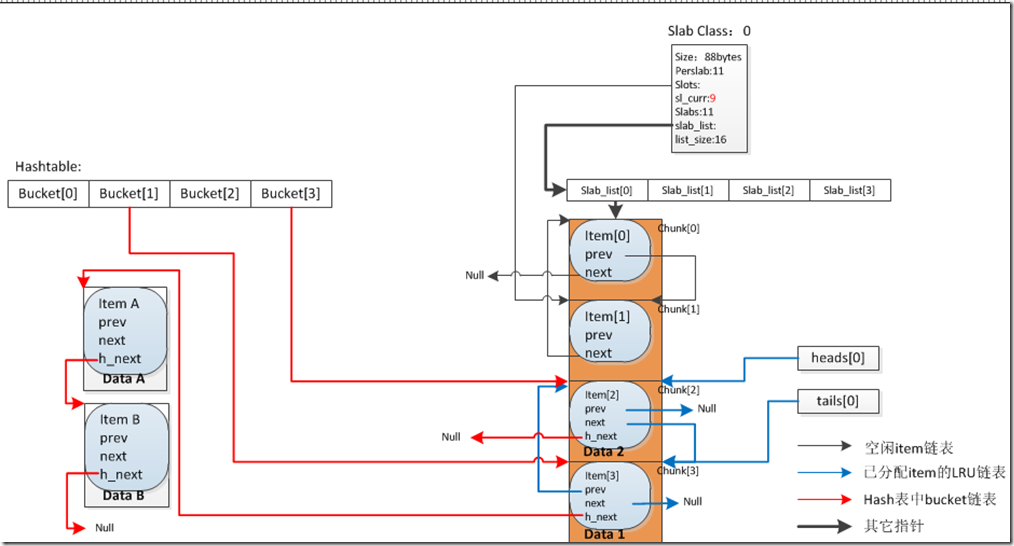
我们以插入一个名为Data1的键值数据进行说明。首先系统将根据Data1的key去查询哈希表,是否存在相同的键值数据,如果数据相同,只执行更新操作;如果key相同但value不同,对原item执行删除操作,并继续执行。
data1 + item 部分所需内存 < 88bytes,因此我们选择管理88bytes的slab class。首先判断该slab的LRU链表尾部tails所指是否存在超时过期节点,此时LRU链表为空,tails指向null,并无过期节点。
然后再判断该slab class中slots指针维护的空闲链表,此时空闲链表中存在空闲chunk。Memcached将空闲链表的头节点chunk取出,并将Data1的数据保存到该chunk中。此时空闲chunk双向链表如图浅黑色指针部分。
接着通过hash映射确定该item对应于哈希表中bucket[1]中,因为之前该哈希表中bucket[1]已经挂载了2个数据item,因此我们将Data1的item添加到bucket[1]中的单链表的表头。此时哈希表如图红色指针部分。
我们把该item加入该slab class的LRU链表,此时该item将作为该slab class第一个被使用的item。LRU链表如图蓝色指针部分。
最后我们修改该slab class中的属性,因为一个chunk已经被使用,因此我们将该slab class中的sl_curr当前可用chunk修改为11914。

再添加一个具体数据
完成了上述插入操作后,我们再尝试添加一个新的Data2数据,data2 + item 部分所需内存依旧小于88bytes。
首先依旧是进行哈希查找是否存在相同键值,略过不谈。
同样是选择管理88bytes的slab class,判断该slab的LRU链表尾部tails所指是否存在超时过期节点。此时LRU链表只有之前储存Data1的item节点,tails即指向它,该item节点并未过期。
此时该slab class的空闲链表中依旧存在空闲chunk,我们再次从该slots维护的空闲双向链表中取出表头的88bytes的chunk,并将Data2的数据保存到该chunk中。
通过hash映射确定该item对应于哈希表中bucket[3]中,因为之前中bucket[3]中并未挂载任何item,因此我们将Data2的item添加到bucket[3]中的单链表的表头。
我们把该item加入该slab class的LRU链表的表头。此时Data2所对应的item位于LRU链表的第一个节点,Data1对应的item位于LRU链表的第二个节点。
最后将该slab class中的sl_curr当前可用chunk修改为11913。
删除数据流程:
关于删除数据item部分的操作大致为添加操作的逆操作,主要流程为:
1.通过哈希表获取该键值数据item
2.从哈希表中移除该item节点
3.从LRU链表中移该item节点
4.清空item数据并将该chunk重新添加到空闲chunk链表