Github项目地址 :https://github.com/comeony/personal-project/tree/master/Cplusplus
PSP 表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 60 |
| · Estimate | · 估计这个任务需要多少时间 | 60 | 60 |
| Development | 开发 | 300 | 600 |
| · Analysis | · 需求分析 (包括学习新技术) | 300 | 400 |
| · Design Spec | · 生成设计文档 | 30 | 30 |
| · Design Review | · 设计复审 | 30 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 20 |
| · Design | · 具体设计 | 60 | 120 |
| · Coding | · 具体编码 | 120 | 150 |
| · Code Review | · 代码复审 | 120 | 300 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 180 | 240 |
| Reporting | 报告 | 60 | 80 |
| · Test Repor | · 测试报告 | 20 | 20 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 20 |
| 合计 | 1410 | 2140 |
环境
- 操作系统 :Windows 10
- IDE : Visual Studio Community 2017
- 开发语言 :C++
解题思路
-
统计文件中的字符:这个功能利用文件流读取计数即可。代码详见:CharNum.cpp
-
统计文件中的有效行数:行数的标志就是换行符(‘ ’),考虑到空白符的问题,不能简单的计算换行符的数量。我的方法是先让flag=0,遇到非空白符就让flag=1,读到换行符之后看flag是否为1就可以了,flag==1则行数加一。之后都将flag=0用于判断下一行。代码详见:LineNum.cpp
-
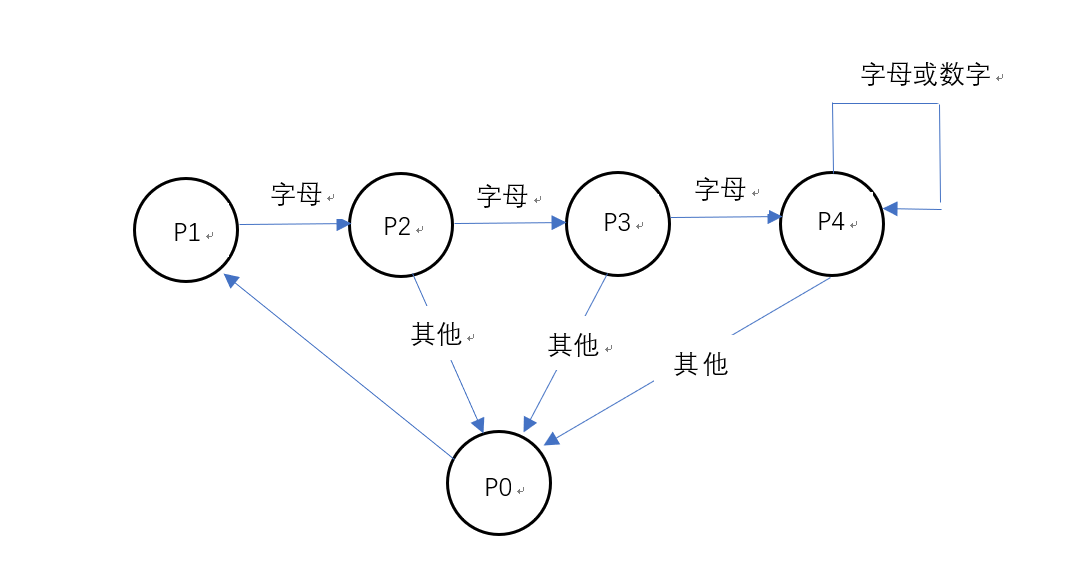
统计文件的单词总数:在这之前应该先对字符进行处理,由于题目要求大写看成小写,所以应该先把大写字母转换后小写,当然这个很简单。主要是判别单词,利用有穷自动机能有效的解决这个问题。代码详见:WordNum.cpp状态转换图如下:
-
统计文件中各单词的出现次数,并且输出频率最高的10个:用第三点的方法来判别单词,通过map<string,int>可以有效的记录单词的频率,再将map复制到vector后,进行sort排序即可,按顺输出即可。代码详见:Word_Fre.cpp
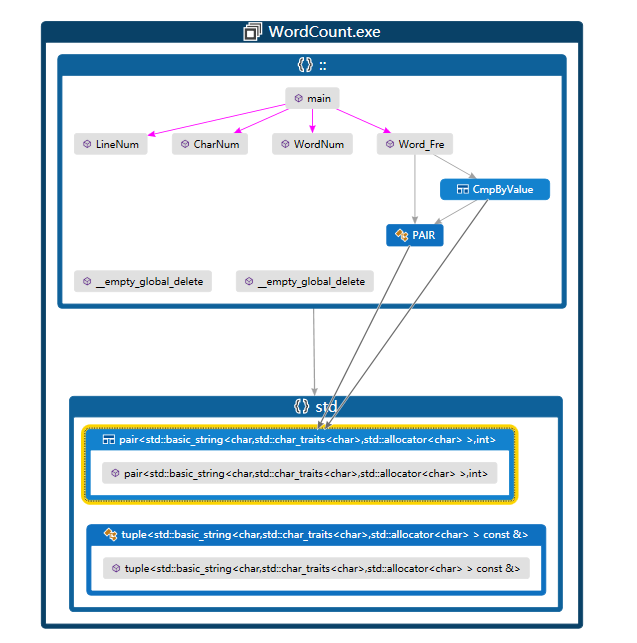
具体设计
为了独立每个功能,我将上述对应的4个功能分别封装到不同的cpp文件中,同时在main()函数中调用调用这个4个函数。
函数关系如下
关键代码
判别单词及统计单词频率(模拟有穷自动机)
设置一个flag变量,通过flag从0到4的变换来模拟自动机的4个状态。初始状态为flag=0
设置一个string类型的变量word来记录读到的单词,初始状态word=“”为空。
-
一开始flag=0(表示位于P0状态),读到一个字母,就让flag=1(表示进入P1状态),同时把word +=char(表示把这个字母连接到word后)
-
当flag=1(表示此时为状态P1)时,读到一个字母,就让flag=2(表示进入P2状态),同时把word +=char(表示把这个字母连接到word后),如果读到的不是字母就将flag=0(回归状态P0),同时把Word清空。
-
当flag=2和flag=3与上面类似,就不重复了
-
当flag=4时,读到字母或者数字就在这个状态停留,同时把word +=char,如果读到是其他字符就将flag=0(回归状态P0),map[word]++(储存到map中)同时把Word清空。
代码如下:
for (; (ch = fgetc(file)) != EOF;) //Determine the word and insert map { if ('A' <= ch && ch <= 'Z') ch = ch + 32; if (flag == 0) { if (ch >= 'a'&&ch <= 'z') { flag = 1; word = word + ch; } } else if (flag == 1) { if (ch >= 'a'&&ch <= 'z') { flag = 2; word = word + ch; } else { flag = 0; word = ""; } } else if (flag == 2) { if (ch >= 'a'&&ch <= 'z') { flag = 3; word = word + ch; } else { flag = 0; word = ""; } } else if (flag == 3) { if (ch >= 'a'&&ch <= 'z') { flag = 4; word = word + ch; } else { flag = 0; word = ""; } } else if (flag == 4) { if (ch >= 'a'&&ch <= 'z' || (ch >= '0'&&ch <= '9')) { word = word + ch; } else { Word_Num_map[word]++; word = ""; flag = 0; } } }
单词频率排序
排序用sort函数,但是我们发现map不能直接用sort,于是现将map复制到vector,在用sort排序,如何大于10个单词就输出前10个,反之全部输出。
具体代码如下:
struct CmpByValue { //排序用的
bool operator()(const PAIR& lhs, const PAIR& rhs) {
return lhs.second > rhs.second;
}
};
map<string, int> Word_Num_map; //定义map
typedef pair<string, int> PAIR;
vector <PAIR> Word_Num_vec(Word_Num_map.begin(), Word_Num_map.end()); //map复制
sort(Word_Num_vec.begin(), Word_Num_vec.end(), CmpByValue()); //排序
分析与改进
测试文本
aaa123123 df aa df
123aaa AAaa123123 ffff
FFff qqq7789 123 dddd
DDdd dddd fffff sadqwe
/
abcabc ABCabc
8888
fff
CPU性能分析
-
采用VS自带的CPU性能分析
-
选用的测试文本如上
-
在测试之前将main()函数循环10000次
-
总时间消耗了30.978s
结果如下:
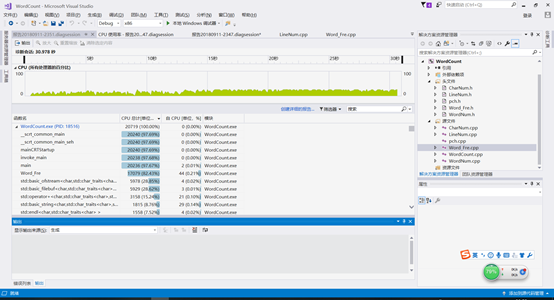
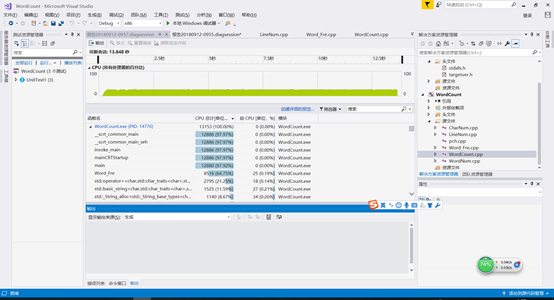
- 可以看到主要耗时在Word_Fre.cpp,具体发现主要耗费在文件打开和输出,我们将输出函数改为fprintf同时改进优化了有穷自动机,可以看到性能有不错的提升,时间降到了13.848s
单元测试
设定了3个单元测试,分别测试3个模块,如下
| 测试名 | 单元测试内容 | 测试模块 | 结果 |
|---|---|---|---|
| UnitTestCharNum | 统计字符数量 | CharNum.cpp | 通过 |
| UnitTestLineNum | 统计行数量 | LineNum.cpp | 通过 |
| UnitTestWordNum | 统计单词数量 | WordNum.cpp | 通过 |
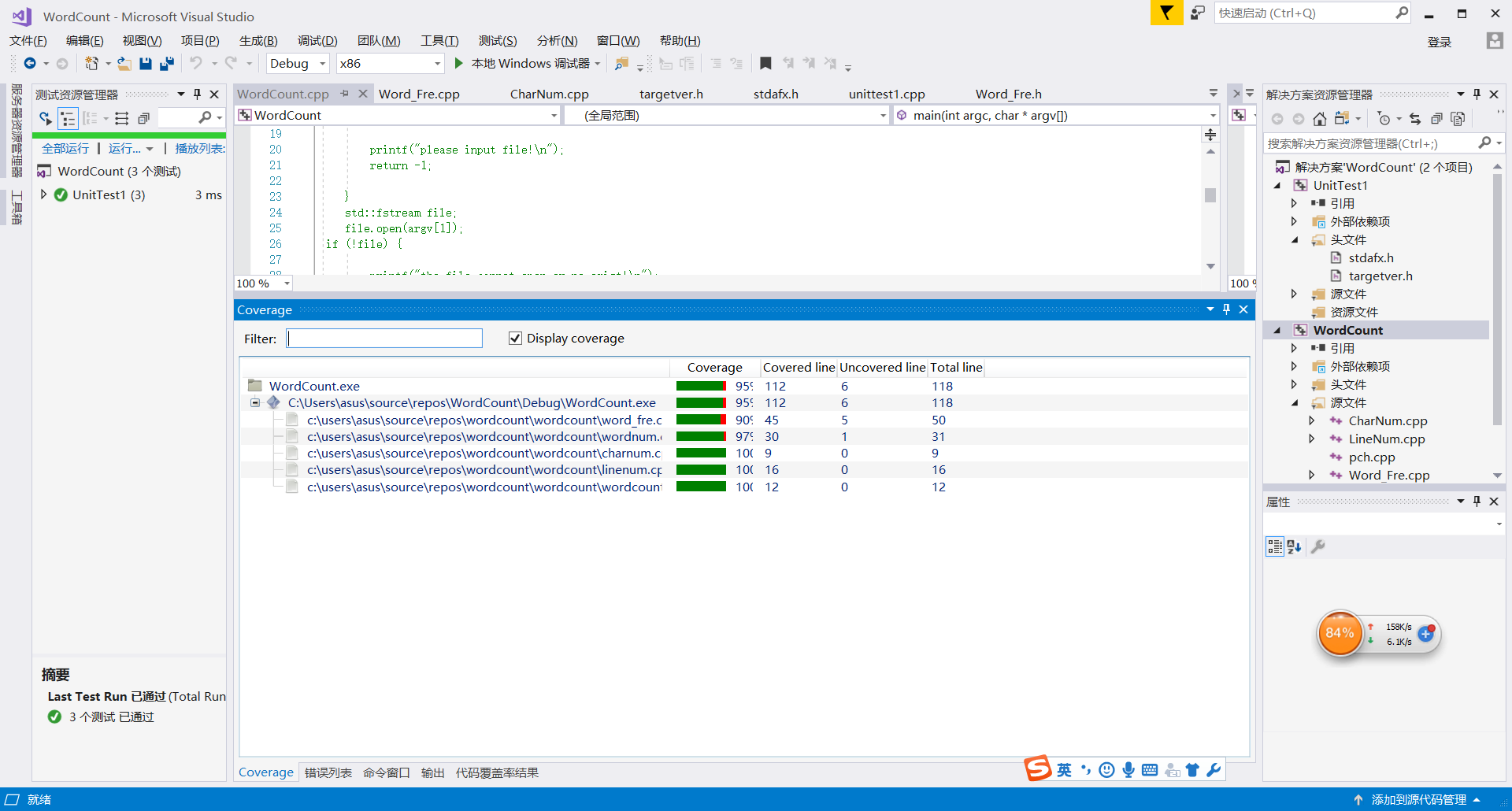
代码覆盖率
- 代码不能全覆盖的主要出现在WordNum.cpp和Word_Fre.cpp中,主要是因为自动机和输出if else的判断。
异常处理
- 输入文件为空异常提醒
- 输入文件不能打开或不存在提醒
if (argv[1] == NULL)
{
printf("please input file!
");
return -1;
}
std::fstream file;
file.open(argv[1]);
if (!file) {
printf("the file cannot open or no exist!
");
return -1;
}
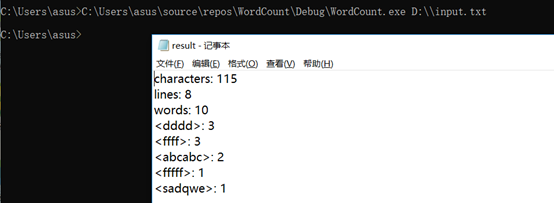
整体运行结果
总结和感想
- 先构思在下笔写代码,效率会提高很多
- 空想和实践还是有很大差距的,刚拿到题目的时候感觉这题不难,但是动笔的时候才发现有太多知识欠缺,又自学了map和vector
- 第一次学习git,感受到了github的好处。
- 本次收获最大的是写代码更有条理,体会了一次软件工程的设计开发流程
- 本次仍有很多不足,要注重提高效率