目录
- 前言
- 一、BeautifulSoup的基本语法
- 二、爬取网页图片
- 扩展学习
- 后记
前言
本章同样是解析一个网页的结构信息
在上章内容中(python网络爬虫之解析网页的正则表达式(爬取4k动漫图片)[三])我们知道了可以使用re正则表达式来解析一个网页。
但是这样的一个解析方式可能对大部分没有正则表达式的人来说就比较困难了,
额,就算会的,也会嫌麻烦。比如me( ̄︶ ̄)↗
那么我们本章同样是学习解析,只不过这个解析的方式不需要特别的一个学习功底。
能够分析一个网页的结构就行了
φ(* ̄0 ̄)
本次的流程:
- 学习BeautifulSoup的基本语法
- 开始分析爬取
一、BeautifulSoup的基本语法
建议直接看官方文档
如果有什么进阶性的需求这章内容不能解决的话,就可以看官方文档:https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
下载lxml模块
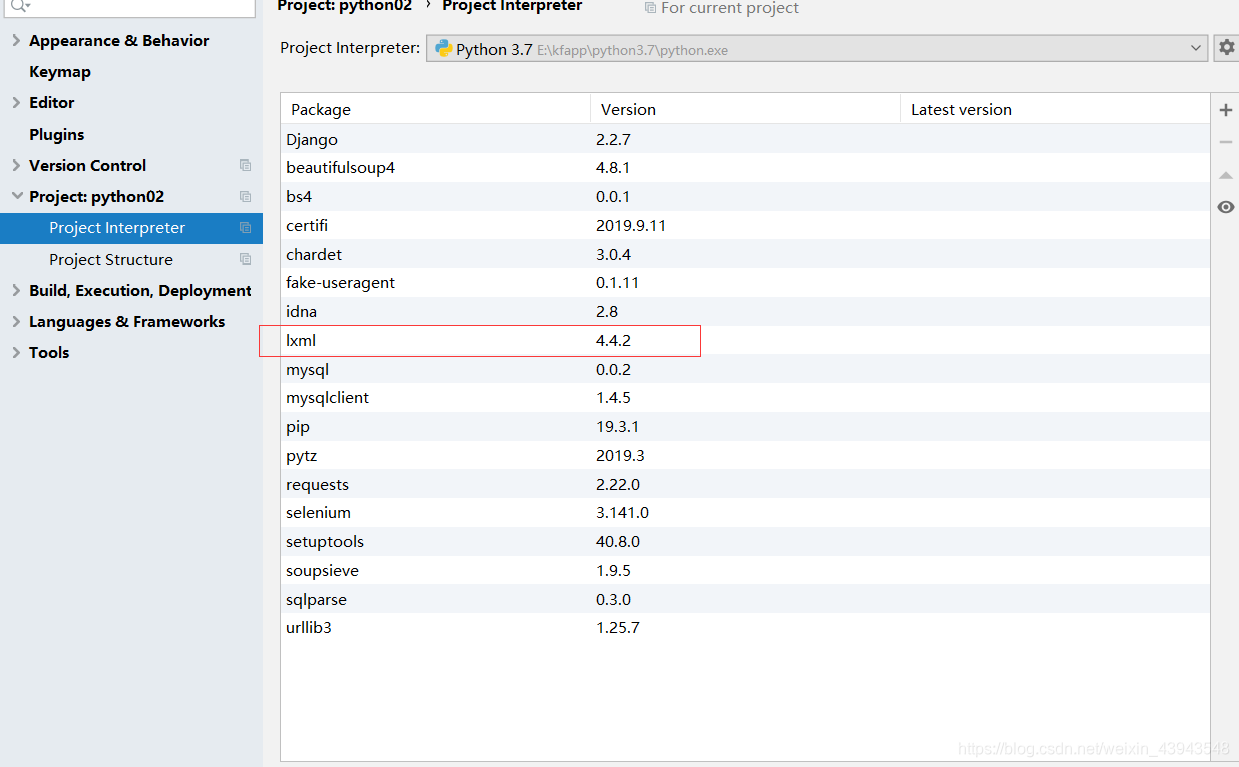
解析器的区别可以参考文档上面的资料。
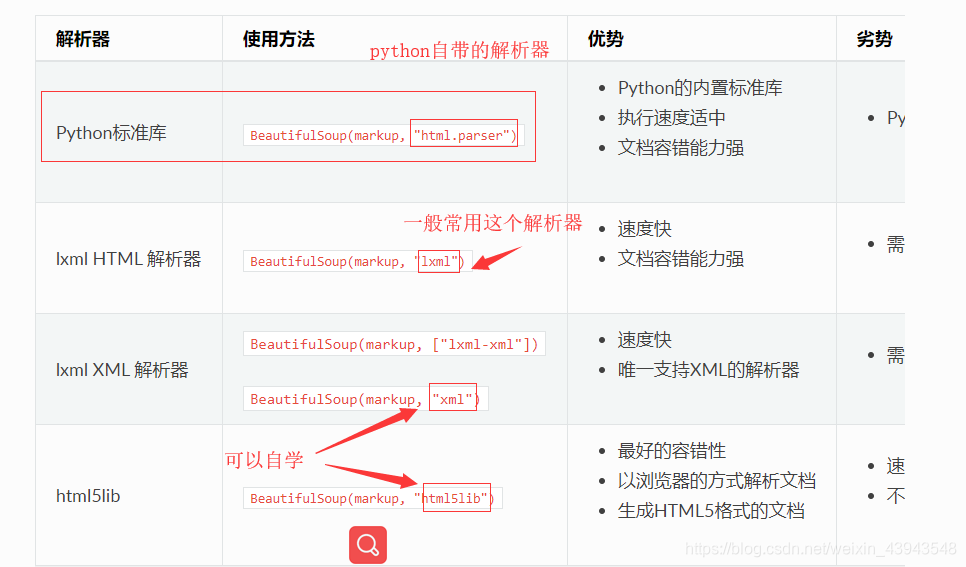
下好之后就可以测试了:
先给大家解析一波: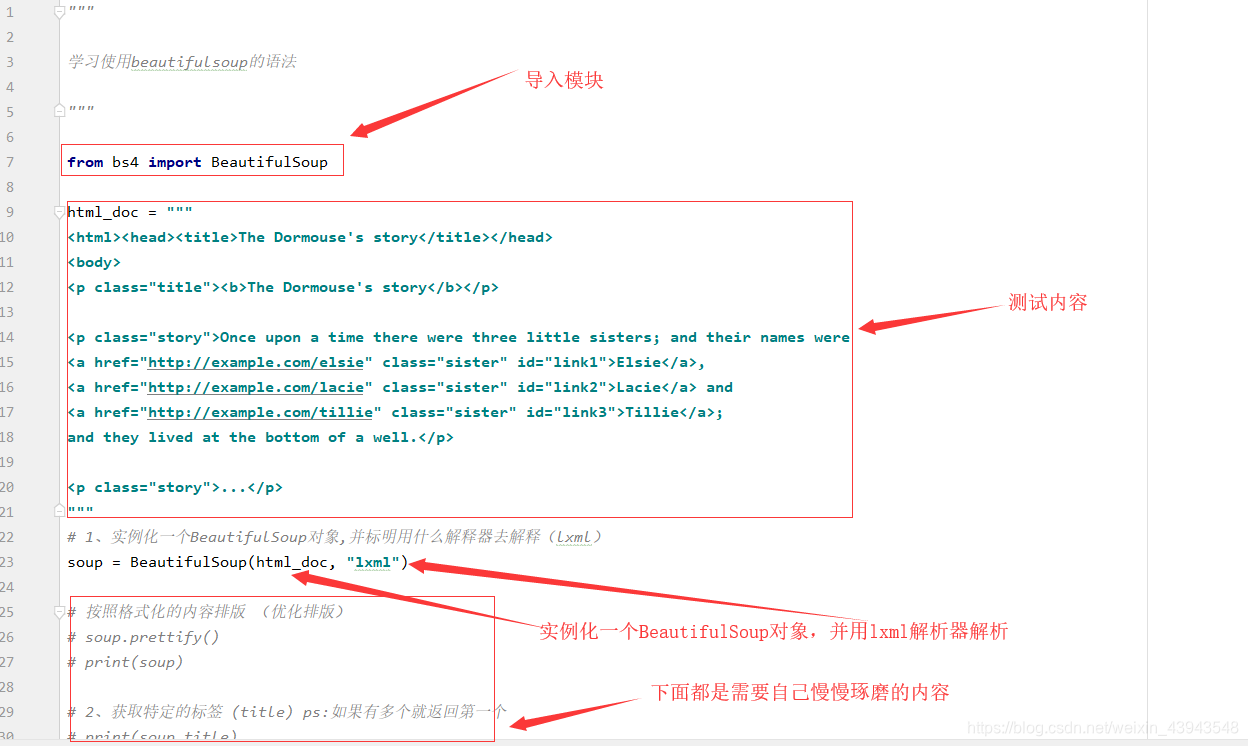
全部代码
""" 学习使用beautifulsoup的语法 """ from bs4 import BeautifulSoup html_doc = """ <html><head><title>The Dormouse's story</title></head> <body> <p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """ # 1、实例化一个BeautifulSoup对象,并标明用什么解释器去解释(lxml) soup = BeautifulSoup(html_doc, "lxml") # 按照格式化的内容排版 (优化排版) soup.prettify() print(soup)
# 2、获取特定的标签 (title) ps:如果有多个就返回第一个 print(soup.title)
# 3、获取特定的标签 (title) 里面的值 print(soup.title.string)
# 4、查询特定的标签 里面的值 print(soup.find("a"))
# 5、查询全部标签 以ResultSet的形式 print(soup.find_all("a")) # 查询所有标签为a的 print(soup.find_all("a", attrs={"id": "link2"})) # 查询所有标签为a的,并且属性为id,属性值为link2 print(soup.find_all(attrs={"id":"link3"})) # 查询所有属性为id,属性值为link3的 print(soup.find_all(id="link1")) # 查询所有属性为id,属性值为link1的
# 6、获取父节点 print(soup.find_all(id="link1")[0].parent.name) # 它的属性为ResultSet print(soup.find("a").parent.name)
# 7、获取子节点 print(soup.find("p",attrs={"class":"story"}).contents) # 遍历了所有内容 print(soup.find("p",attrs={"class":"story"}).clidren) # 有格式的遍历 print(soup.find("p",attrs={"class":"story"}).descendants) # 遍历子孙节点
# 8、获取筒节点的上下节点 print(soup.find("p", attrs={"class", "story"})) print(soup.find(id="link2").next_sibling) # 下一个节点 print(soup.find(id="link2").previous_sibling.previous_sibling) # 上一个节点 print(soup.find(id="link2").previous_siblings) # 下面所有节点 print(soup.find(id="link2").previous_siblings) # 上面所有节点
# 9、获取一个标签中的属性值 print(soup.find("a")["id"]) # 第一种方式 print(soup.find("a").get("id"))# 第二种方式
# 10、获取一个标签中的所有属性值 print(soup.find("a").attrs) # 全部属性 print(soup.find("a").attrs["class"]) # 获取全部属性中的class属性的值 print(soup.find("a").attrs.get("id"))# 获取全部属性中的id属性的值
二、爬取网页图片
这个仅仅就是用来学习的一个内容,学会了就可以自己去爬自己刚兴趣的东西
爬取的对象:https://maoyan.com/board/4
分析:
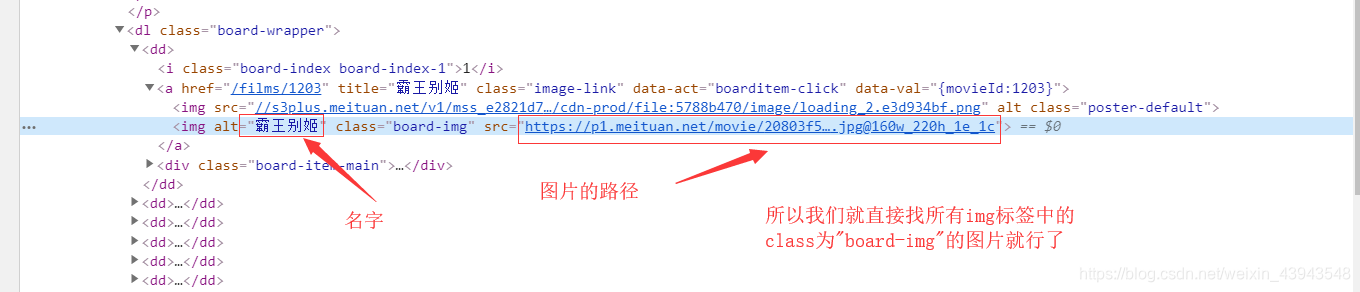
代码解读:
全部代码
""" BeautifulSoup综合案例:爬取“猫眼电影的排行榜” """ import requests from bs4 import BeautifulSoup import os headers = { "Cookie":"__mta=55342740.1575370883618.1575371366305.1575371383145.4; uuid_n_v=v1; uuid=3DACA12015BC11EABE1E1379EFD48C6B2BC02A509AA141CD821BF91F9AF4D24A; _csrf=0f7d373e4f690e2a84b3d5383f941f44faa7316e764ded1cf46f088e34b40614; Hm_lvt_703e94591e87be68cc8da0da7cbd0be2=1575370883; _lxsdk_cuid=16ecb6c014ec8-059803946267d8-2393f61-144000-16ecb6c014ec8; _lxsdk=3DACA12015BC11EABE1E1379EFD48C6B2BC02A509AA141CD821BF91F9AF4D24A; Hm_lpvt_703e94591e87be68cc8da0da7cbd0be2=1575371383; _lxsdk_s=16ecb6c014e-d7d-844-f5b%7C%7C15", "User-Agent": "Opera/9.80 (Windows NT 6.0) Presto/2.12.388 Version/12.14" } response = requests.get("https://maoyan.com/board/4", headers=headers) # 获取当前根目录 root = os.getcwd() # 在根目录中创建文件夹"第1页" os.mkdir("第1页") # 改变当前目录 os.chdir("第1页") if response.status_code == 200: # 解析网页 soup = BeautifulSoup(response.text, "lxml") imgTags = soup.find_all("img", attrs={"class": "board-img"}) print(imgTags) for imgTag in imgTags: name = imgTag.get("alt") src = imgTag.get("data-src") resp = requests.get(src, headers=headers) with open(f"{name}.png", "wb") as f: f.write(resp.content) print(f"{name} {src} 保存成功")
扩展学习
""" BeautifulSoup综合案例: 爬取“最好大学网”排行 """ import requests from bs4 import BeautifulSoup headers = { "User-Agent": "Opera/9.80 (Windows NT 6.0) Presto/2.12.388 Version/12.14" } response = requests.get("http://www.zuihaodaxue.com/zuihaodaxuepaiming2019.html", headers=headers) response.encoding = "utf-8" if response.status_code == 200: soup = BeautifulSoup(response.text, "lxml") trTags = soup.find_all("tr", attrs={"class": "alt"}) for trTag in trTags: id = trTag.contents[0].string name = trTag.contents[1].string addr = trTag.contents[2].string sco = trTag.contents[3].string print(f"{id} {name} {addr} {sco}")
后记
本章的内容也是解析数据,但是对于正则表达式来说的话实在是方便太多了,
下一章的内容还是解析,不过是使用xpath解析
如果感觉本章写的还不错的话,不如。。。。。(~ ̄▽ ̄)~ ,(´▽`ʃ♡ƪ)