需求分析之数据收集
·[519]|1000天行动计划 读书笔记/热点追踪/论文研读/教程手册
继续项目流程,本节则主要说需求分析——有关数据的事情,我们知道数据对于模型来说是像食物对于人类,没有数据可以说就是没有模型。广义的数据不仅仅包括数字的资料,还包括其他诸如图像、文字等形式,这些最终都需要转化为模型能吃的数据融合到模型体系中去。
说起数据,简直就是模型工程师的梦魇,一肚子苦水,每次做项目的时候,数据这关可以说是头大,由于数据是不直接产生效益的(但是其非常重要,也可以理解嘛,发展过程如果收集一堆数据,理论上对于未来是好事,但是确实没有对当地产生实际影响,所以不重视数据也是正常的发展过程),我们现阶段的发展对基础数据的轻视,宁可多上点工程好歹有个效果,也不会去关注什么数据的事情。常见的情况就是没有数据,这也没有那也没有,好不容易听到有相关数据,你可别高兴太早,能不能获取到还是另一回事呢。不过随着国家的投入,数据之殇渐渐有了好转,有些地方逐渐建立起了数据体系,有时候甚至会由一些幸福的烦恼,数据好像有点多,哈哈,这时候呢,虽然大量的数据分析和处理工作需要做,但是比起没有数据的苦,作为模型工程师也会痛并快乐着吧。
闲话不说了,你看一提起数据来,我就有这么多感悟,足以说明数据对于模型的重要性了吧。数据这块先要进行的是与相关部门对接历史数据,如果模型研究周期涉及未来的,也有在对接过程中协调未来数据的对接方式。然后呢,就是实地调研了(实际上初步的数据获取到之后,模型的建模工作也会同步开始了,会进行模型的初步建模,也就是调研发生在模型初步建模之后),实地调研过程需要带着需求和建模时候的问题,建模的问题我后面讨论,现在简单说就是需求分析阶段的那些特殊问题要去现场确认。最后,对于没有的数据但是非常重要的数据进行补充监测,对于解决工程类项目,还需要进行同步的监测方案。
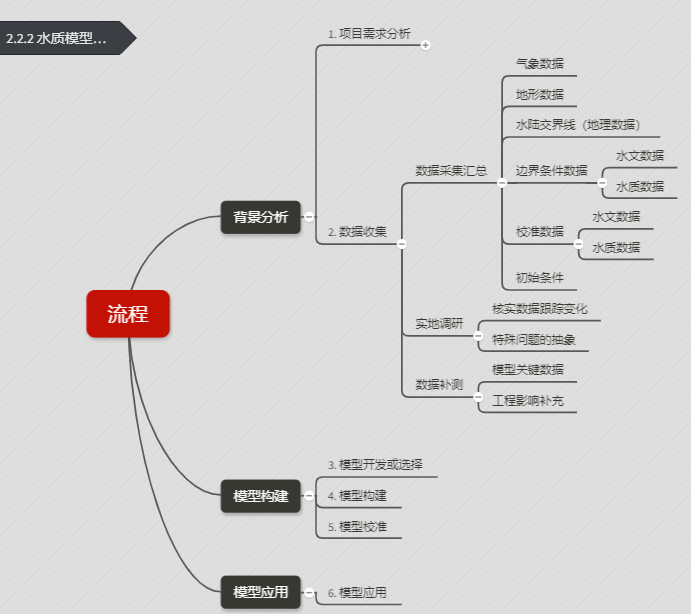
数据收集
需要收集的数据与需求紧密相连,前面也提到过一般问题和特殊问题,由于不同的研究对象特殊问题不尽相同,所以数据的收集工作就从一般问题开始,特殊问题的只能从自己有限的经验中,简单的列几条,同时也准备建立一个数据清单库,会不断更新遇到的案例,可以随时来关注本文。
前面说过,数据是广义上的数据,只要是相关的数据都应该尽可能的收集到,就连新闻都不放过。为什么呢?越多的数据则对水体的表达越好,举个简单的例子,如果想将富营养化的湖泊的磷模拟准确,单有磷的数据是不行的,其只能粗略的建模,必须有藻类、氮等其他指标综合,才能足够模拟富营养化的湖泊的磷。同时,因为目前数据的基础薄弱,数据往往很难有模型对应的数据,这时候就不同的数据综合分析判断。
模型都需要什么数据呢,这里从建模角度分析来说先说说为什么需要这些数据会更容易表达,所以我决定在后续内容详述,这里就简述。
模型建模需要的数据一般包括:
- 气象数据,这个比较易懂,就是所说的天气数据,当然需要的指标比较多,气象的数据包括气温、气压、湿度等,数据从气象部门获取。
- 水体地形数据,这个数据在前面网格的文件中已有详述,网格地形,这个数据由于其特殊性,之前很难获取到,一般没有什么部门测量,但是最近环保工程较多,使得比之前容易。小的河道建议自己去测量就好了,大的河道数据来源有以下几种,如果是河道的,航道管理局,当地的河道管理局;如果是黑臭河道治理,可能住建局或相关的市政工程部门,另外还有一个渠道,如果有清淤工程的,施工单位可能会有,但是其数据会提交相关建设部门,注意清淤前后的变化,需要模拟时期对应的地形。很多人都会去测绘部门,实际上测绘部门更多的集中在陆地上,水下地形不太会有,还有DEM数据也不是水下的,这点也要注意。
- 水陆交界线(地理数据),这个数据用于描述水体与陆域的边界,一般如果对绝对位置要求不高(比如你不需要说具体的模拟桥墩受力分析这种),影像图就够了,要求高的需要高精度的加密水系数据,也需要注意时效性,这个可能在水利部门或国土部门,环保部门。
- 边界条件数据,水文数据和水质数据。边界条件则为驱动模拟进行的输入数据,这些数据输入模型之后,模型从而能够运行起来。如果是模拟的河流,其的边界条件主要有上游支流数据,下游数据,点源污染数据,面源污染数据,而对于湖泊而言,则是入湖河流数据,出湖数据,取水数据,其他同河流。这些数据包括水位和水质,水文主要是流量和水位(流速也有用,但资料较少),水质则为污染物浓度。数据的频率越高越好,对接的部门水质数据一般在环保部门,而水文数据则在水文部门,水文部门也会有一些水质的数据,而点源污染则可能是住建部门,面源数据一般没有直接的,只能间接获取,从当地农业部门的资料推求,甚至需要流域模型来计算获取。
- 校准数据,水文数据和水质数据。这个数据用于校准模型,虽然也是水文数据和水质数据,但是与边界条件有所不同,其功能不同:边界条件用于驱动模型运行的数据,作为输入数据来使用的,而驱动模型计算之后得到结果数据,在用校准数据和这些模拟结果比较,从而进行调参的方向。位置不同:校准数据对于河流而言,则是研究范围内的断面水文和水质数据(区分边界条件是其上游支流的断面);湖泊则是湖体中的水文和水质数据(区分与入湖河流)。数据的来源则和边界数据类似。
- 初始条件数据,模型启动时刻的初始条件,这个数据和校准数据的内容是一致的,只不过其用途是用于作为模型启动初始值。
上述就是模型普遍需要的数据清单,为了看起来更加清晰,列表如下:
.png)
上述清单当然不全,只是非常的基础的数据让大家了解下。另外,针对湖泊特征及研究的问题,还有一些数据也非常重要,没有列上去的有:底泥数据、水生植被数据、干湿沉降数据和闸坝的调度数据等。
另外需要说明的是,随着信息化的建设,目前很多地方已经进行了部分数据的公开,除了与部门进行对接外,互联网上也能够下载到不少数据,可以去当地的省水利官网,生态环境厅官网,数据中心,湖泊河流管理部门去寻寻宝,本号也会收集一些网址后续放在公众号中,未来数据一定会越来越丰富的。
实地调研
实践的重要性不多说了,模型之所以能够反映实际,就是建模中考虑实际,贴合实际情况建模。对于实践的重点,目前自己的经验还不足以全面阐述,仅谈两个调研的重要任务,核实数据跟踪变化和特殊问题的抽象。
所谓的核实数据跟踪变化,主要是由于数据由采集到汇总发布,需要一段时间,这个时间内水体及周边是不断的再变化的,所以数据能否反映当前的实际情况需要去确认核实数据是否准确,同时对于收集到的数据中的监测断面,入流、出流位置,取水口等等都一定要去看看,这些对于后面的建模非常重要,只有心中有实地,模型才能做好。当然,调研看什么,不同的人有不同的视角,行家可能一眼参透一切,我可能需要蹲个一周。另外,建模过程肯定会遇到问题,那么可能需要多次跑,所以提前与熟悉当地的人建立比较紧密的联系,可以先询问下,其也可能解决你60%的疑问,剩下的就需要你亲自跑了。
另外,则是对特殊问题的抽象了,说的太玄乎,实际就是一些问题你只有在现场感受之后才可能有一些灵感,在头脑中想象如何去解决,我觉得实地调研最重要的就是所谓的感觉,对研究对象的了解,具体的感觉,可以给你建模过程带来很多信息。比如有些闸控问题,可能想象起来很难办,现场发现其压根是常年闸死的,这时候你直接不用考虑了,说了太巧了,不过就是实际发生的事情。
数据的补测
数据的补测,这块内容,实际也算数据收集的一部分,这部分内容是在数据收集之后会有个初步的补充清单,这个清单包括了一些建模必须要的关键但是确实无历史的数据。那可能就是同步建模和监测了,相关的监测方案又是另外一门技术了。还有一种情况就是建模之后,发现模型中有很多不确定性,这些需要数据来消除,那么就可能需要进行额外的数据补充。另外,对于工程类项目,长期的项目会使得其边界发生变化,这时候需要我们同步更新模型。
小结
本小结主要是聊数据,数据环节在模型项目中该如何进行,这里只是个人有限的经验,很多地方未必完全准确,不过数据的整个过程,包括数据的对接,监测等,后面的数据处理,均是模型项目最为花费时间的地方,这点也是整个项目的难点。
由于教程系列文章需要花费很多时间,难免出错,而这里不能进行后续完善,所以推荐大家关注我的博客,获取最新的修正和补充。 公众号的社群同步开启,感兴趣可在公众号对话框回复“社群”,获取群号和加入方式。

微信公众号 | 水环境编Cheng长 网 站 | comieswater.com

2019-9-14
folder=/微信公众号/水环境编Cheng长/
参考文献: 1 使用3EWATER需准备哪些数据?.三易思创.
{kind=link}