参考:https://blog.csdn.net/roymno2/article/details/71628128ou(感谢大佬)
【问题背景】
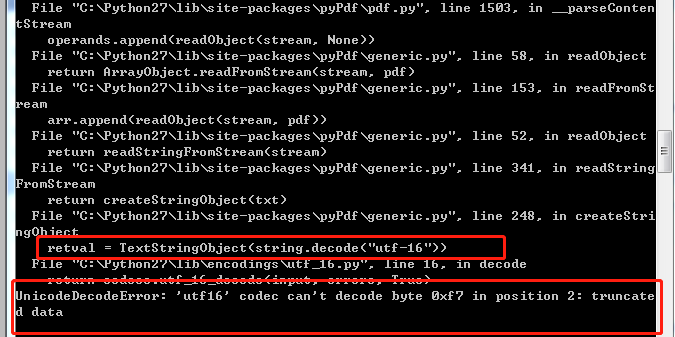
最近有一个任务,需要使用python2.7去读取pdf文件内容。使用的模块是pypdf。当我获取到pdf其中的一页page时,调用page.mergeScaledTranslatedPage()这个函数处理时,报了下面的错误:
【问题原因】:
这个错误是什么意思呢?咋一看跟解码和utf16有关。
这个python错误的意思是,decode("utf-16") 这个操作,碰到了一个单个字节的回车(0x0A),utf-16中每个字符应该是2个字节,如果是UTF-16大端,就是 00 0A,如果是UTF-16 小端(也叫UCS-2小端)的编码就是0A 00。
这个错误就是在UTF-16 小端的情况下,少了后半个字符。即图中红色字符所指的位置,有个0A,它后面缺少了00。

【解决办法】:
解决方法是在decode时,用 decode("utf-16","ignore") 即加上ignore这个选项,把这个错误忽略掉。