文章很长,建议收藏起来,慢慢读! 疯狂创客圈总目录 地址2 为您奉上以下珍贵的学习资源:
-
免费赠送 经典图书:《Java高并发核心编程(卷1)》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
-
免费赠送 经典图书:《Java高并发核心编程(卷2)》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
-
免费赠送 经典图书:《Netty Zookeeper Redis 高并发实战》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
-
免费赠送 经典图书:《SpringCloud Nginx高并发核心编程》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
-
免费赠送 资源宝库: Java 必备 百度网盘资源大合集 价值>10000元 加尼恩领取
推荐:入大厂 、做架构、大力提升Java 内功 的 精彩博文
| 入大厂 、做架构、大力提升Java 内功 必备的精彩博文 | 2021 秋招涨薪1W + 必备的精彩博文 |
|---|---|
| 1:Redis 分布式锁 (图解-秒懂-史上最全) | 2:Zookeeper 分布式锁 (图解-秒懂-史上最全) |
| 3: Redis与MySQL双写一致性如何保证? (面试必备) | 4: 面试必备:秒杀超卖 解决方案 (史上最全) |
| 5:面试必备之:Reactor模式 | 6: 10分钟看懂, Java NIO 底层原理 |
| 7:TCP/IP(图解+秒懂+史上最全) | 8:Feign原理 (图解) |
| 9:DNS图解(秒懂 + 史上最全 + 高薪必备) | 10:CDN图解(秒懂 + 史上最全 + 高薪必备) |
| 11: 分布式事务( 图解 + 史上最全 + 吐血推荐 ) | 12:限流:计数器、漏桶、令牌桶 三大算法的原理与实战(图解+史上最全) |
| 13:架构必看:12306抢票系统亿级流量架构 (图解+秒懂+史上最全) |
14:seata AT模式实战(图解+秒懂+史上最全) |
| 15:seata 源码解读(图解+秒懂+史上最全) | 16:seata TCC模式实战(图解+秒懂+史上最全) |
| Java 面试题 30个专题 , 史上最全 , 面试必刷 | 阿里、京东、美团... 随意挑、横着走!!! |
|---|---|
| 1: JVM面试题(史上最强、持续更新、吐血推荐) | 2:Java基础面试题(史上最全、持续更新、吐血推荐 |
| 3:架构设计面试题 (史上最全、持续更新、吐血推荐) | 4:设计模式面试题 (史上最全、持续更新、吐血推荐) |
| 17、分布式事务面试题 (史上最全、持续更新、吐血推荐) | 一致性协议 (史上最全) |
| 29、多线程面试题(史上最全) | 30、HR面经,过五关斩六将后,小心阴沟翻船! |
| 9.网络协议面试题(史上最全、持续更新、吐血推荐) | 更多专题, 请参见【 疯狂创客圈 高并发 总目录 】 |
| SpringCloud 微服务 精彩博文 | |
|---|---|
| nacos 实战(史上最全) | sentinel (史上最全+入门教程) |
| SpringCloud gateway (史上最全) | 更多专题, 请参见【 疯狂创客圈 高并发 总目录 】 |
背景:
下一个视频版本,从架构师视角,尼恩为大家打造史上最强kafka源码视频。
并且,进一步,带大家实现一个超高质量的项目实操:10WQPS超高并发消息队列架构与实操
why kafka:
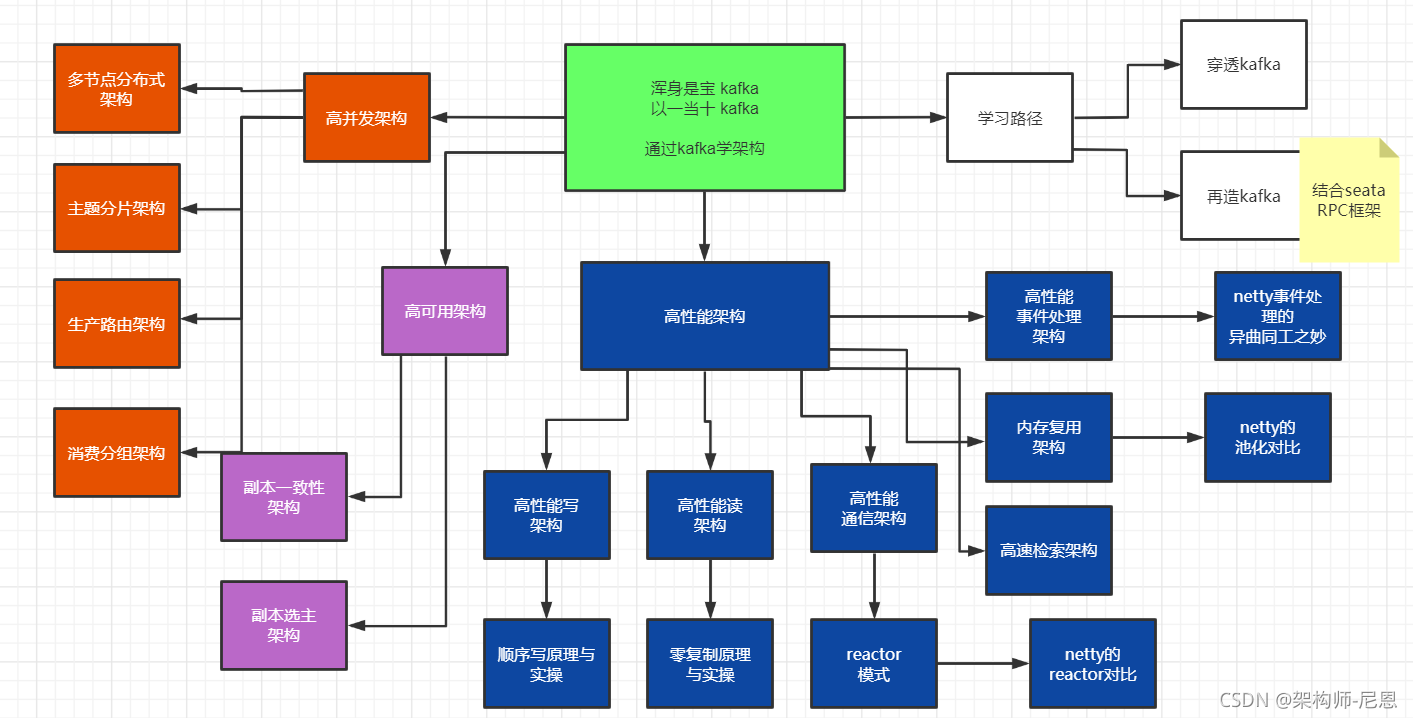
kafka 是高性能、高并发应用的经典案例,从技术学习、架构学习的角度来讲,浑身是宝。 netty 仅仅是通讯架构,kafka还有存储架构、高并发架构、高可用架构等等,都是经典中的经典。
但是,kafka很难,大家要做好思想准备。不过,跟着尼恩一起学架构,估计大家也不难了。
最终的目标,带大家穿透kafka, 掌握其存储架构、高并发架构、高可用架构的精髓。
最后,结合netty高性能架构,最终手写一个10WQPS超高并发消息队列。
此视频版本的整体的次序:
- 首先,开始Kafka源码分析,对kafka来一次彻底穿透
- 然后,10WQPS超高并发消息队列架构与实操,结合牛逼的Seata 源码中的RPC框架
此文为Kafka源码分析之11.
本系列博客的具体内容,请参见 Java 高并发 发烧友社群:疯狂创客圈
其实,很多小伙伴,想学kafka,只是,其太难了

尼恩带大家学架构的目标: 把kafka中的所有高并发、高性能、高可用架构,完全消化,完全吸收,最终再造kafka, 大大提升自己的架构能力, 向架构师前进一大步。
Kafka源码分析9:Controller控制器的原理
Controller,是Apache Kafka的核心组件非常重要。它的主要作用是在Apache Zookeeper的帮助下管理和协调控制整个Kafka集群。
在整个Kafka集群中,如果Controller故障异常,有可能会影响到生产和消费。所以,我们需要对其状态、选举、日志等做全面的监控。
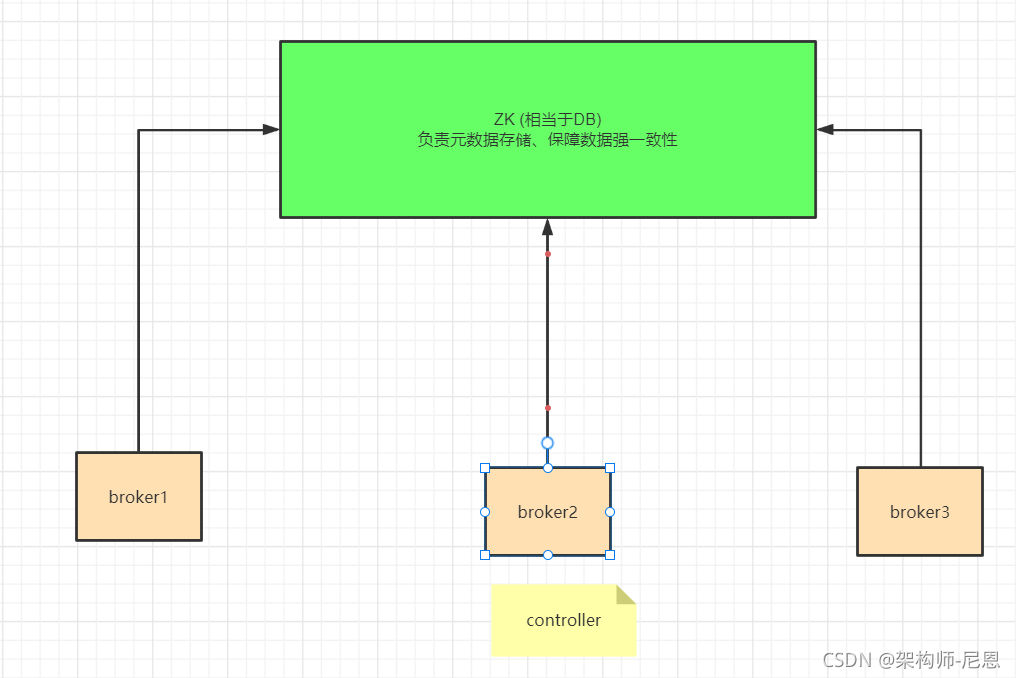
集群中任意一台 Broker 都能充当控制器的角色,但是,在运行过程中,只能有一个 Broker 成为控制器,行使其管理和协调的职责。换句话说,每个正常运转的 Kafka 集群,在任意时刻都有且只有一个控制器。
要宏观的了解controller的位置,咱们还是先从分布式系统的集群架构说起
分布式的系统的集群架构分类
分布式系统中,由谁来管理集群的元数据信息和状态信息呢?
两种架构模式:
-
中心化架构(主从架构)
-
去中心话架构(p2p架构)
主从(或者说Leader-Follower)架构
主从架构模式中,Leader来管理集群的元数据信息和状态信息。
Leader可以是固定的,也可以是通过选举出来的。
Leader-Follower架构,也叫Master-Slave架构。
细数主流的开源分布式系统,你会发现四处都是Master-Slave架构的影子,是最常用的设计套路之一,深入理解了Master-Slave架构对于理解这些系统有很大的帮助
下面来简单介绍一下有哪些著名的分布式框架采用了Master-Slave架构:
1.HDFS
NameNode和DataNode实际上是Master-Slave模式,NameNode作为Master进行集群和元数据管理,DataNode负责实际的数据存储。

2.Elasticsearch
Master-Slave模式,Master进行集群和元数据管理,Data Node作为Slave节点,负责实际数据的索引和搜索操作。

3.Hbase
HMastet和HRegionServer也是Master-Slave架构,HMaster负责Region分配,协调HRegionServer,提供管理功能,而HRegionServer负责维护HRegion。

4.Flink

Flink的架构模式也是类似Master-Slave模式,JobManager相当于Master,负责集群任务调度和资源管理,TaskManager相当于Slave负责具体节点的资源申请和管理。
5.kafka
Kafka作为一个高效的分布式消息系统,也采用了主从(或者说Leader-Follower)的设计思路
kafka通过选举的方式,进行Leader角色的选举,从所有的节点中,选出一个broker节点,作为leader角色,或者说master角色。
选出的角色,叫做controller 。
controller 负责元数据的管理和状态信息的管理。
P2P的模式
采用了P2P的模式,完全去中心化,如果 Redis Cluster集群。
Redis Cluster是一种服务器Sharding技术(分片和路由都是在服务端实现),采用多主多从,每一个分区都是由一个Redis主机和多个从机组成,片区和片区之间是相互平行的。

Redis Cluster如何管理集群的状态信息呢? 通过Gossip协议。
Gossip算法如其名,灵感来自办公室八卦,只要一个人八卦一下,在有限的时间内所有的人都会知道该八卦的信息,这种方式也与病毒传播类似,因此Gossip有众多的别名“闲话算法”、“疫情传播算法”、“病毒感染算法”、“谣言传播算法”。
但Gossip并不是一个新东西,之前的泛洪查找、路由算法都归属于这个范畴,不同的是Gossip给这类算法提供了明确的语义、具体实施方法及收敛性证明。
Gossip 过程是由种子节点发起,当一个种子节点有状态需要更新到网络中的其他节点时,它会随机的选择周围几个节点散播消息,收到消息的节点也会重复该过程,直至最终网络中所有的节点都收到了消息。这个过程可能需要一定的时间,由于不能保证某个时刻所有节点都收到消息,但是理论上最终所有节点都会收到消息,因此它是一个最终一致性协议。
这里一共有 16 个节点,节点 1 为初始被感染节点,通过 Gossip 过程,最终所有节点都被感染:

Controller是什么
Controller,是Apache Kafka的核心组件。
Controller的主要作用是在Apache Zookeeper的帮助下管理和协调控制整个Kafka集群,管理元数据,管理集群状态。
集群中的任意一台Broker都能充当Controller的角色.
但是,在整个集群运行过程中,只能有一个Broker成为Controller。
Controller的位置
也就是说,每个正常运行的Kafka集群,在任何时刻都有且只有一个Controller。

controller的两大职能
controller的两大职能
- 集群元数据的管理
- 集群节点的协调职能
图解:controller的集群元数据的管理职能
controller的元数据缓存架构
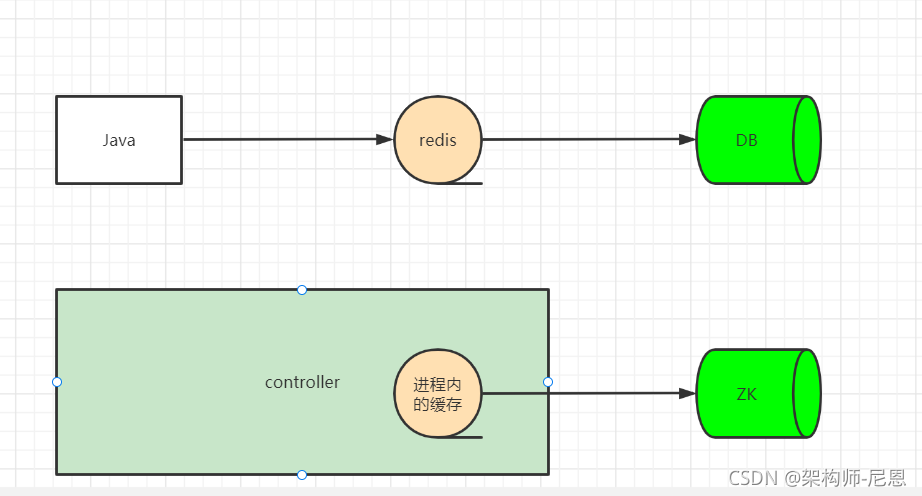
kafka的元数据信息,持久化在ZK中,具体如下图:

每一次元数据的使用,都去访问zk,性能比较低。
与java程序提升性能的策略类似,controller也使用了缓存的架构。
只不过,使用的是进程内的缓存,具体如下图:
Controller缓存的元数据

其中比较重要的数据有:
所有主题信息。
包括具体的分区信息,比如领导者副本是谁,ISR集合中有哪些副本等。
所有Broker信息。
包括当前都有哪些运行中的Broker,哪些正在关闭中的Broker等。
所有涉及运维任务的分区。
包括当前正在进行Preferred领导者选举以及分区重分配的分区列表。
这些数据其实在ZooKeeper中也保存了一份。
缓存的作用
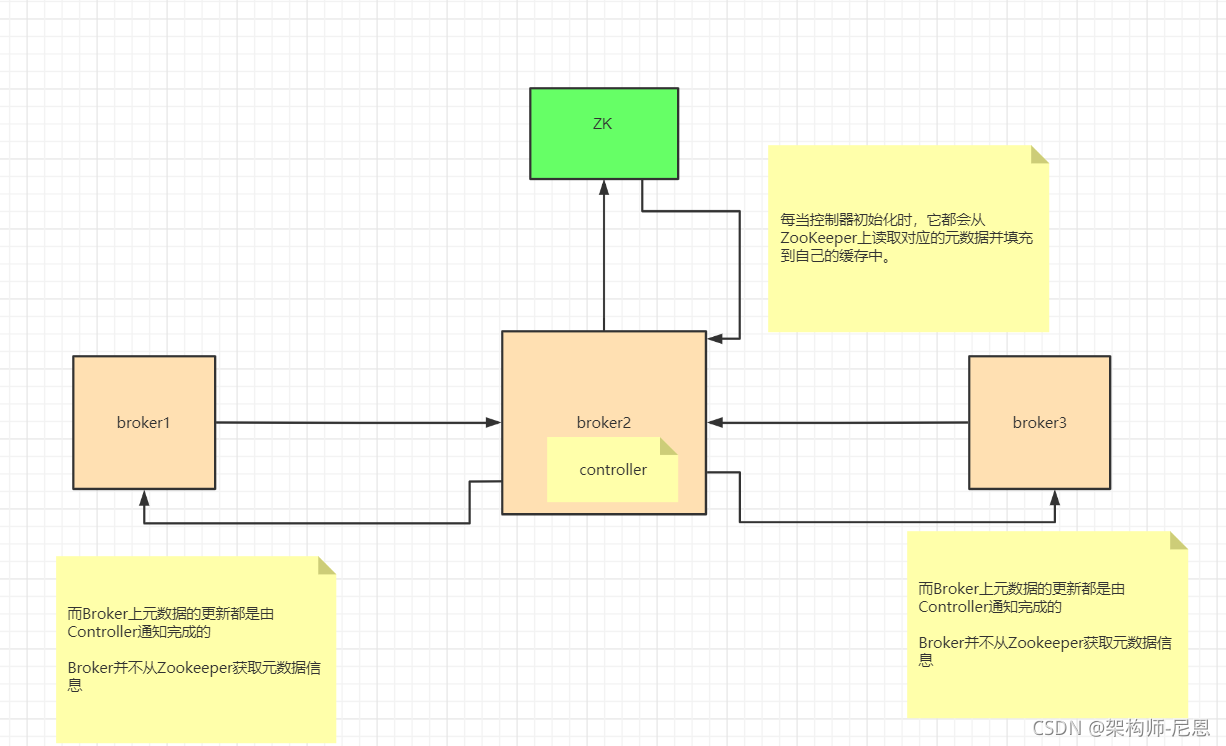
每当控制器初始化时,它都会从ZooKeeper上读取对应的元数据并填充到自己的缓存中。
而Broker上元数据的更新都是由Controller通知完成的,Broker并不从Zookeeper获取元数据信息。
Controller的集群节点的协调职能
9项细致的协调工作
下面以文字形式列举Controller需要做些什么集群节点的协调职能,大致9项:
- 当Producer或Consumer通过MetadataRequest请求查询Partition元数据(如Leader和ISR信息)时,将发生变化的Partition元数据广播给各个Broker。
- 处理ControlledShudownRequest请求,该请求用于优雅地关闭一个Broker(主要是会主动删除ZK中对应的Broker节点,减少对应Partition不可用的时间)。
- 启动并管理Partition状态机组件(PartitionStateMachine)和Replica状态机组件(ReplicaStateMachine)。
- 注册TopicChangeListener监听器,监听ZK的
/brokers/topics节点,处理Topic的增删操作;注册TopicDeletionListener监听器,监听ZK的/admin/delete_topics节点,用来实际执行删除Topic的动作。 - 注册PartitionModificationsListener监听器,监听ZK中各个
/brokers/topics/<topic>节点,处理Topic的Partition扩容和缩容操作。 - 注册PreferredReplicaElectionListener监听器,监听ZK的
/admin/preferred_replica_election节点,处理最优Replica的重选举。 - 注册IsrChangeNotificetionListener监听器,监听ZK的
/isr_change_notification节点,处理ISR(in-sync replicas)集合发生变化的Partition。 - 注册PartitionReassignmentListener监听器,监听ZK的
/admin/reassign_partitions节点,用于重新分配各Partition的Leader和Follower。 - 注册BrokerChangeListener监听器,监听ZK的
/brokers/ids节点,触发Broker的上下线操作。
如果上面的9项,还比较抽象,还请不要捉急,容我慢慢道来。
5类协调职能梳理
归类一下,相对就简单一下,Controller职责大致分为5类:
- 主题管理
- 分区重分配
- Preferred leader选举
- 集群成员管理(Broker上下线)
- 数据服务(向其他Broker提供数据服务) 。
它们分别是:
UpdateMetadataRequest:更新元数据请求。
topic分区状态经常会发生变更(比如leader重新选举了或副本集合变化了等)。
由于当前clients只能与分区的leader Broker进行交互,那么一旦发生变更,controller会将最新的元数据广播给所有存活的Broker。
具体方式就是给所有Broker发送UpdateMetadataRequest请求。
CreateTopics: 创建topic请求。
当前不管是通过API方式、脚本方式抑或是CreateTopics请求方式来创建topic,做法几乎都是在Zookeeper的/brokers/topics下创建znode来触发创建逻辑,而controller会监听该path下的变更来执行真正的“创建topic”逻辑。
DeleteTopics:删除topic请求。
和CreateTopics类似,也是通过创建Zookeeper下的/admin/delete_topics/
分区重分配:
即kafka-reassign-partitions脚本做的事情。
同样是与Zookeeper结合使用,脚本写入/admin/reassign_partitions节点来触 发,controller负责按照方案分配分区。
Preferred leader分配:
preferred leader选举当前有两种触发方式:自动触发(auto.leader.rebalance.enable=true)和kafka-preferred-replica-election脚本触发。
两者“玩法”相同,向Zookeeper的/admin/preferred_replica_election写数据,controller提取数据执行preferred leader分配。
分区扩展:即增加topic分区数。
标准做法也是通过kafka-reassign-partitions脚本完成,不过用户可直接往Zookeeper中写数据来实现,比如直接把新增分区的副本集合写入到/brokers/topics/
集群扩展:
新增broker时Zookeeper中/brokers/ids下会新增znode,controller自动完成服务发现的工作。
broker崩溃:
同样地,controller通过Zookeeper可实时侦测broker状态。一旦有broker挂掉了,controller可立即感知并为受影响分区选举新的leader。
ControlledShutdown:
broker除了崩溃,还能“优雅”地退出。
broker一旦自行终止,controller会接收到一个 ControlledShudownRequest请求,然后controller会妥善处理该请求并执行各种收尾工作。
Controller leader选举:
controller必然要提供自己的leader选举以防这个全局唯一的组件崩溃宕机导致服务中断。
这个功能是通过 Zookeeper的帮助实现的。
Controller内部结构
最后来看看Controller的内部结构简图,如下所示。

由图可见,Controller内部结构主要由以下5部分组成。
-
ZK监听器:
已经说过了,不再废话。
-
定时任务:
举个例子,假设我们将
auto.leader.rebalance.enable参数设为true,那么就会启动名为auto-leader-rebalance-task的定时任务来自动维护最优Replica的平衡。 -
Controller上下文:
元数据的本地缓存,就集中在此上下文对象中。
在Controller初始化阶段,从ZK中已存储的数据建立,并在Controller的生命周期中一直维护。包含集群Broker可达性信息,与所有Topic、Partition、Replica的状态信息。
-
事件队列:
本质上为FIFO的阻塞队列(LinkedBlockingQueue),承载各个监听器、定时任务投递过来的状态变更信息,这些信息都包装为事件。
Controller 端有多个线程向事件队列写入不同种类的事件,比如,ZooKeeper 端注册的 Watcher 线程、KafkaRequestHandler 线程、Kafka 定时任务线程,等等。而在事件队列的另一端,只有一个名为 ControllerEventThread 的线程专门负责“消费”或处理队列中的事件。这就是所谓的单线程事件队列模型。
-
事件处理线程:
顾名思义,只有单线程,用来处理各个事件,并将它们的结果反映到Controller上下文,以及异步地propagate到各个Broker中。使用单线程的好处是无需关心多线程的同步,无锁机制可以提升性能。
Broker如何成为Controller
非常简单:
通过竞争创建zk的znode节点完成,最先在Zookeeper上创建临时节点/controller成功的Broker就是Controller。
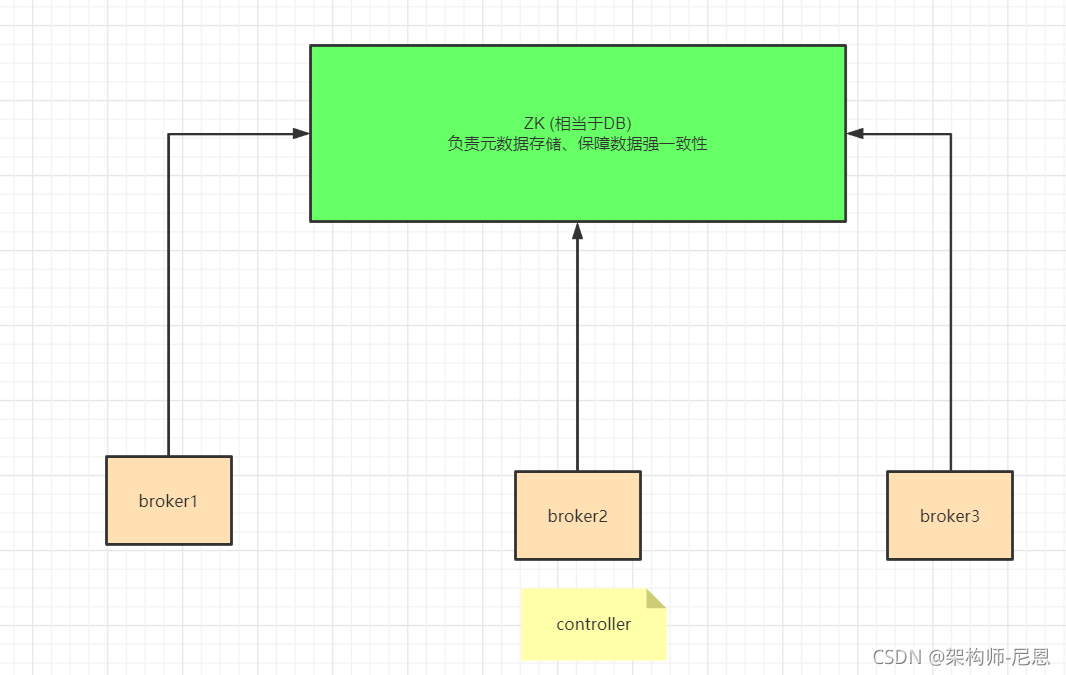
对应的znode的路径为/controller
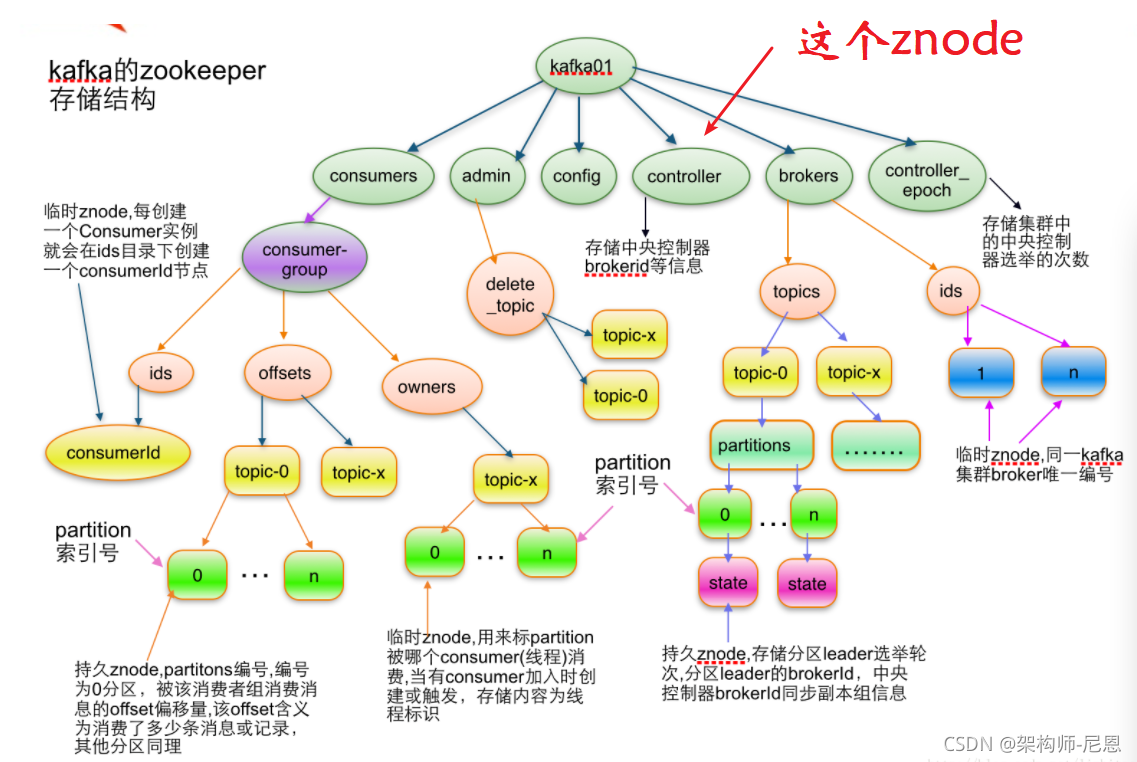
znode的路径的代码如下:

Controller如何监控其他的broker
当broker节点因故障离开Kafka集群时,broker中存在的leader分区将不可用(因为客户端只对leader分区进行读写)。
为了最大限度地减少停机时间,需要快速找到替代的领导分区。Controller可以从zookeeper watch获取通知信息。Zookeeper给了客户端监听znode变化的能力,也就是所谓的watch通知功能。
一旦znode节点创建、删除、子节点数量发生变化,或者znode中存储的数据本身发生变化,Zookeeper会通过节点变化处理程序显式通知客户端。
当Broker宕机或主动关闭时,Broker与Zookeeper的会话结束,znode会被自动删除。同样的,Zookeeper的watch机制把这个变化推送给Controller,让Controller知道有Broker down或者up,这样Controller就可以进行后续的协调操作。
Controller将收到通知并对其采取行动,以确定Broker上的哪些分区将成为Leader partition。然后,它会通知每个相关的Broker,或者Broker上的topic partition将成为leader partition,或者LeaderAndIsrRequest从新的leader分区复制数据。
总之:
Controller重度依赖Zookeeper,依赖zookeepr保存元数据,依赖zookeeper进行服务发现。Controller大量使用Watch功能实现对集群的协调管理。
controller脑裂(多个controller)问题
脑裂问题出现的可能情况:
情况一:创建topic成功,但是produce的时候,却报unknown partition的错误,但zk上却显示了每个partition的leader信息;
情况二: 给某个topic增加分区,zk显示已有增加的分区信息,但是依旧报找不到新增加的分区信息错误
原因:多个controller,导致元数据不一致;
解决办法:
- zk上找到最新的controller
- 将其余几个过期的controller重启 原因分析:controller进行Full GC停顿时间太长超过zookeeper session timeout,导致kafka误以为controller已经挂掉,于是进行新一轮的controller选举。 当旧的controller重新恢复后,还在进行controller的逻辑。因此会出现多个controller的情况
如何避免Controller出现裂脑
如果Controller所在的Broker故障,Kafka集群必须有新的Controller,否则集群将无法正常工作。这儿存在一个问题。很难确定Broker是宕机还是只是暂时的故障。但是,为了使集群正常运行,必须选择新的Controller。如果之前更换的Controller又正常了,不知道自己已经更换了,那么集群中就会出现两个Controller。
其实这种情况是很容易发生的。
例如,由于垃圾回收(fullGC),一个Controller被认为是死的,并选择了一个新的控制器。在fullGC的情况下,在原Controller眼里没有任何变化,Broker甚至不知道自己已经被暂停了。因此,它将继续充当当前Controller,这在分布式系统中很常见,称为裂脑。
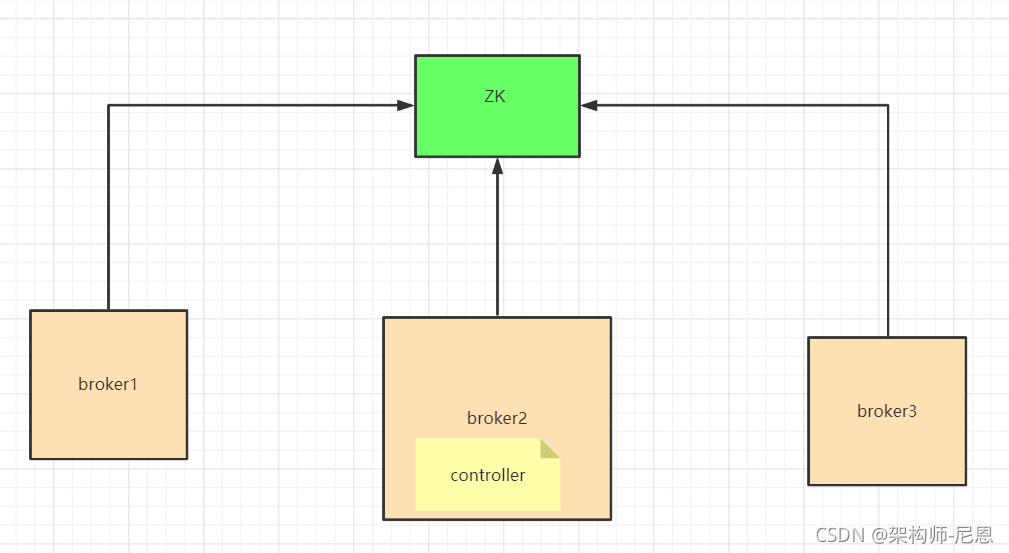
在fullGC的情况下,在原Controller眼里没有任何变化,Broker甚至不知道自己已经被暂停了。
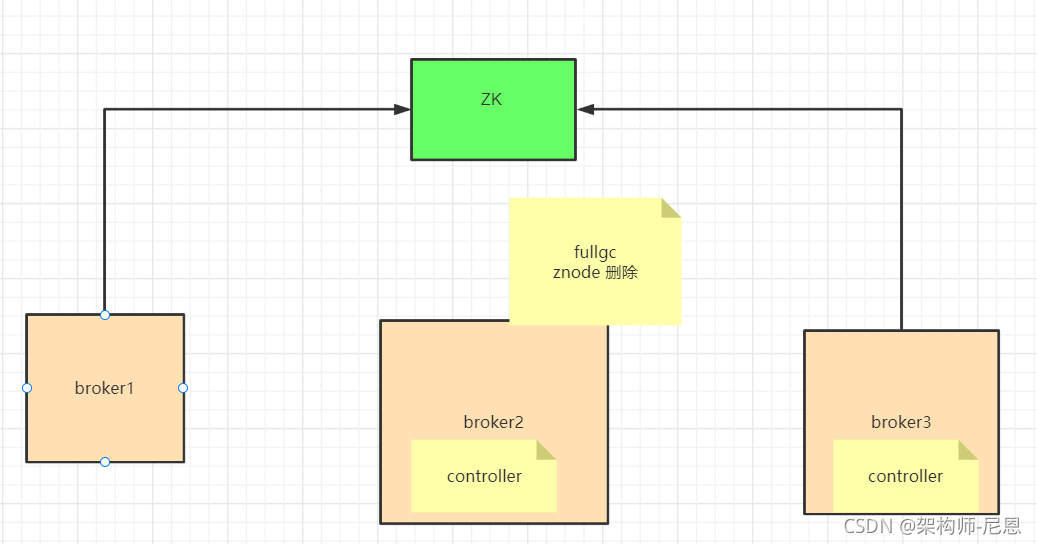
现在,集群中有两个Controller,可能会一起发出相互冲突的事件,这会导致脑裂。
脑裂之后,可能会导致严重的不一致。所以需要一种方法来区分谁是集群的最新Controller。
脑裂的解决方案:
Kafka是通过使用epoch number来处理,epoch number只是一个单调递增的数。第一次选择控制器时,epoch number值为1。如果再次选择新控制器,epoch number为2,依次单调递增。
重点是:epoch number记录在Zookeepr的一个永久节点controller_epoch。
每个新选择的Controller通过zookeeper的条件递增操作获得一个新的、更大的epoch number。
当其他Broker知道当前的epoch number时,如果他们从Controller收到包含旧(较小)epoch number的消息,则它们将被忽略。
即Broker根据最大的epoch number来区分最新的Controller。
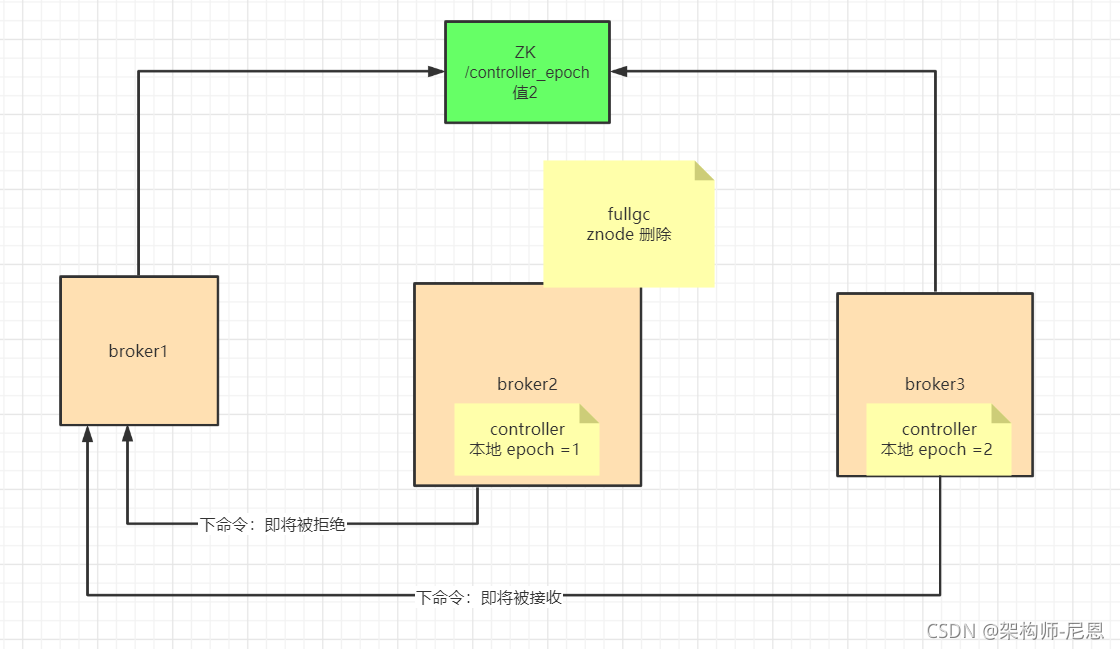
上图中,Broker2向Broker1下发命令:
将Broker1上的partitionA做为leader,消息的epoch number值为1;
假设,同时Broker3也向Broker1发送同样的命令。
不同的是,Broker3消息的epoch number值为2,此时broker1只监听broker3的命令(由于其epoch号大),而会忽略broker3的命令,以免发生脑裂。
Controller控制器的监控
官网上有个名为 activeController 的 JMX 指标,可以帮助我们实时监控控制器的存活状态。这个 JMX 指标非常关键,你在实际运维操作过程中,一定要实时查看这个指标的值。
参考文献
https://blog.csdn.net/weixin_39025362/article/details/108420492
https://www.cnblogs.com/boanxin/p/13618431.html
https://www.jianshu.com/p/7a61a2aa09fc
https://www.cnblogs.com/boanxin/p/13696136.html
https://www.cnblogs.com/listenfwind/p/12465409.html
https://www.shangmayuan.com/a/5e15939288954d3cb3ad613e.html
https://my.oschina.net/u/3070368/blog/4338739
https://www.cnblogs.com/shimingjie/p/10374451.html
https://www.bbsmax.com/A/VGzlAONYJb/
https://baijiahao.baidu.com/s?id=1707530675869255847&wfr=spider&for=pc