读取一张图片
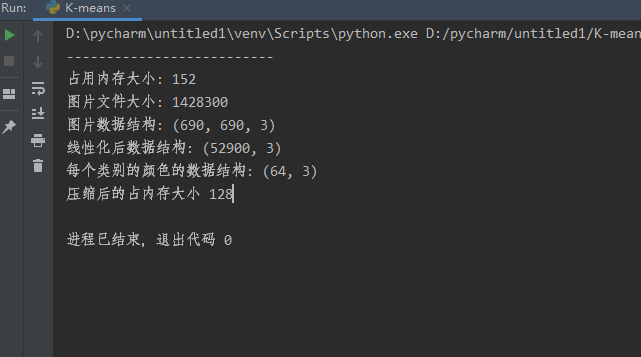
观察图片文件大小,占内存大小,图片数据结构,线性化
用kmeans对图片像素颜色进行聚类
获取每个像素的颜色类别,每个类别的颜色
压缩图片生成:以聚类中收替代原像素颜色,还原为二维
观察压缩图片的文件大小,占内存大小
答
源代码:
from sklearn.datasets import load_sample_image from sklearn.cluster import KMeans import matplotlib.image as mpimg import matplotlib.pyplot as plt import imageio #读取图片 #china = load_sample_image("china.jpg") #由于出现故障无法读取load_sample_image中的图片,所以这里用了自己准备的。 jcr = imageio.imread('D:/Camera Roll/微信图片_20191108205855.jpg') plt.imshow(jcr) plt.show() #检查占用内存大小 和 文件大小 import sys print("--------------------------") print("占用内存大小:", sys.getsizeof(jcr)) print("图片文件大小:", jcr.size) #检查图片数据结构 print("图片数据结构:", jcr.shape) #用k均值聚类,对图片进行压缩 image = jcr[::3, ::3] #降低图片尺寸 #线性化预处理————将图片拉平 x = image.reshape(-1, 3) #将图片的每一行,按顺序都排成一排,3为颜色参数 print("线性化后数据结构:", x.shape) plt.imshow(image) plt.show() #开始聚类 n_colors = 64 model = KMeans(n_colors)#以聚类中心为64类进行聚类 labels = model.fit_predict(x)#进行聚类,并输出每个颜色类别 colors = model.cluster_centers_ print("每个类别的颜色的数据结构:", colors.shape) #替换原颜色 new_image = colors[labels].reshape(image.shape) #还原为二维 #new_image = new_image.reshape(jcr.shape) print("压缩后的占内存大小", sys.getsizeof(new_image)) #显示压缩后的图片 import numpy as np new_image = new_image.astype(np.uint8) plt.imshow(new_image) plt.show() mpimg.imsave('D:/Camera Roll/444.jpg', new_image)
原图片:

压缩后的图片:

各项数据:
保存图片:

2. 观察学习与生活中可以用K均值解决的问题。
从数据-模型训练-测试-预测完整地完成一个应用案例。
这个案例会作为课程成果之一,单独进行评分。
答:本次是一个链家网房源的低、中、高、面积预测评估,数据是事先从链家网上爬去的1300条,结果可能稍有误差。
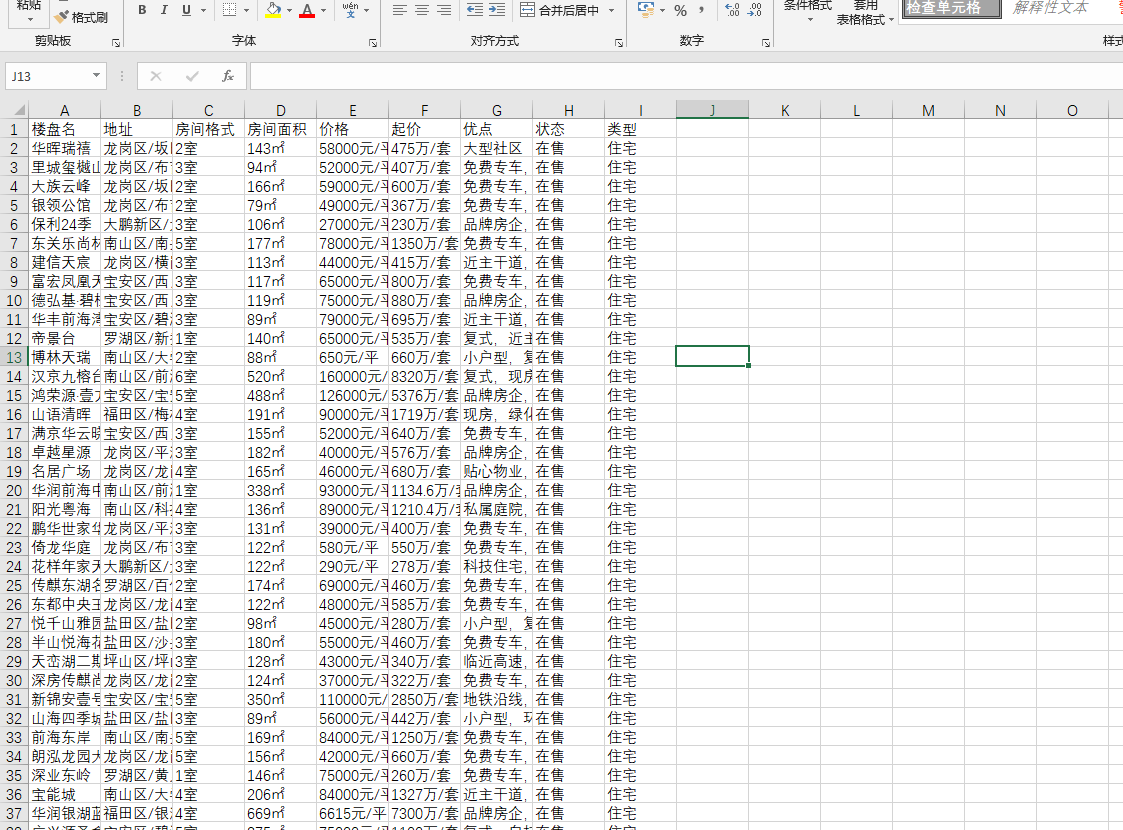
数据:

源代码:
print("201706120037 贾昌润 软件工程一班") #导入基础的库 from sklearn.cluster import KMeans import pandas as pd import numpy as np import matplotlib.pyplot as plt #画图 #%matplotlib inline #为了让画图直接在jupyter中显示 data = pd.read_csv(r'D:lianjiashujvallll.csv', encoding='utf-8') #读取csv数据 #data.head(3) #查看前3前行的数据 #data.describe() #基本统计量 【只能针对数值类型】 #包含:count数量;mean均值;std标准差;min最小值;25%下四分位;50%中位数;75%上四分位;max最大值 #data.info() #查看每列的数据类型('楼盘名', '地址', '房间格式', '房间面积', '价格', '起价', '优点', '状态', '类型') # 数据预处理!!!!!!! data=data[['房间格式', '房间面积', '价格']] #引入需要的数据属性 #data.head(3) #data.info() (data.isnull()).sum() #检验有几个缺失值 data=data.dropna() (data.duplicated()).sum() #检验有几个重复值 #data=data.drop_duplicates() #去除重复值 data.head(3) data.info() data.describe() (~data.房间面积.str.contains('㎡')).sum() #查看有几个没有㎡单位 #一下都是预处理各种方式,绘图前记得选择运行。(我没有将预处理数据存入表格,因为我觉得根据不同图选择需要的预处理方式更加灵活多变) data=data.assign(房间面积=data.房间面积.map(lambda x:round(float(x.replace('㎡','')),1))) #去除房间面积的单位 data.head(3) #data.房间格式.unique() data=data.assign(房间格式=data.房间格式.map(lambda x:round(float(x.replace('室','')),1))) #去除房间格式的单位 (~data.价格.str.contains('元/平')).sum() data=data.assign(价格=data.价格.map(lambda x:round(float(x.replace('元/平','')),1))) #去除价格的单位 from sklearn.cluster import KMeans import numpy as np
#开始聚类 x = data.iloc[:, [1, 2]].astype('int') x = np.array(x) km_model = KMeans(n_clusters=3) km_model.fit(x) y_Kmeans = km_model.predict(x) #预测模型 heshi = np.array(data[y_Kmeans==0]['房间面积']) pd.set_option('display.max_rows',100)#设置最大可见100行 pd.set_option('display.width', 1000) pd.set_option('display.max_columns',1000) pd.set_option('display.max_colwidth',1000) print("heshi: ", heshi) yiban = np.array(data[y_Kmeans==1]['房间面积']) buheshi = np.array(data[y_Kmeans==2]['房间面积']) print("yiban: ", yiban) print("buheshi: ", buheshi)
结果:
一般

不合适


合适
