一、基本介绍
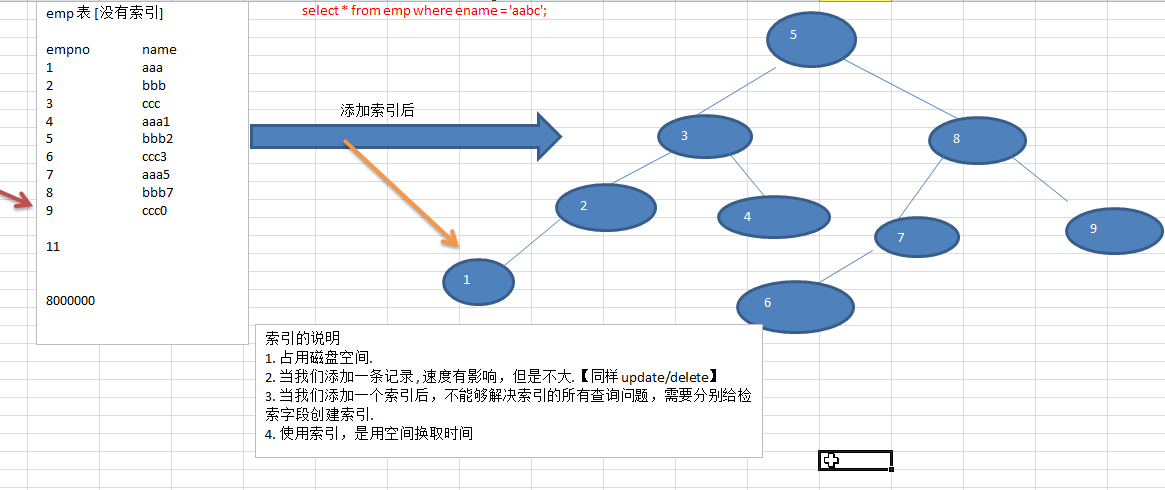
索引是数据的目录,能快速定位行数据的位置。加速查询速度,但作为代价会降低增删改的速度。
同一个表中索引名不能重复ERROR 1061 (42000): Duplicate key name 'xxx '
索引的价值,在于提高一个海量表的检索速度,索引的算法有btree 二叉树的算法.还有一种就是hash算法(只适用于=或!=, 不能查范围)。
只有memory/heap 引擎支持hash算法,hash算法适用于key-value查询
支持前缀索引,即对索引字段的前N个字符创建索引。前缀索引的长度跟存储引擎相关,MyISAM索引前缀可达1000字节长,而innodb前缀长度最长是767字节;前缀的限制应以字节为单位,而create table语句中的前缀长度解释为字符数;
根据存储引擎可以定义每个表的最大索引数和最大索引长度,每个表至少支持16个索引,总索引长度至少为256字节;
Create index cityname on city(name(10)); ##10个字节的前缀索引
注意:前缀索引在排序和分组操作的时候无法使用。
二、索引的分类
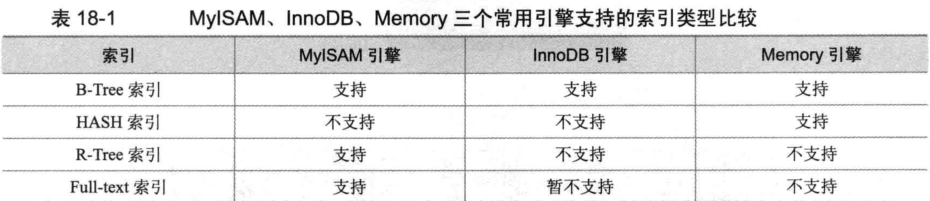
索引有如下: 主键索引 (primary key), 唯一索引(unique)、普通索引(index),全文索引(fulltext)




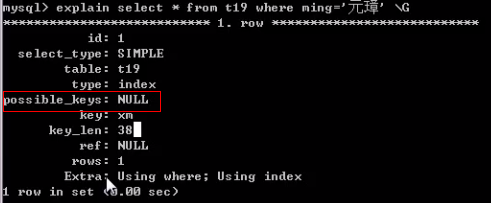
上图在查询时没有用到索引,而是从索引直接返回数据,不再经过.MYD查找数据
组合键使用索引时 遵循 最左前缀规则
比如:col1 + col2 + col3 字段上的联合索引能被包含 col1,(col1+col2),(col1 + col3),(col1+col2+col3)的等值查询利用到,不能被col2,(col2+col3)的等值利用到。

查询的列都在索引的字段中,查询的效率高,原因是,直接访问索引就能获取所需的数据,不需要通过索引回表,(覆盖索引扫描)。
三、先看看一个海量表,在查询的时候会有什么问题?
先构建一个海量表(8000000)
这样,我们构建的海量表,需要数据有差异性,我们使用存储过程(体检)来构建.
#模拟一个雇员管理系统
CREATE TABLE dept( /*部门表*/
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
dname VARCHAR(20) NOT NULL DEFAULT "",
loc VARCHAR(13) NOT NULL DEFAULT ""
) ENGINE=MyISAM DEFAULT CHARSET=utf8 ;
#创建表EMP雇员
CREATE TABLE emp
(empno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, /*编号*/
ename VARCHAR(20) NOT NULL DEFAULT "", /*名字*/
job VARCHAR(9) NOT NULL DEFAULT "",/*工作*/
mgr MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,/*上级编号*/
hiredate DATE NOT NULL,/*入职时间*/
sal DECIMAL(7,2) NOT NULL,/*薪水*/
comm DECIMAL(7,2) NOT NULL,/*红利*/
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 /*部门编号*/
)ENGINE=MyISAM DEFAULT CHARSET=utf8 ;
#工资级别表
CREATE TABLE salgrade
(
grade MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
losal DECIMAL(17,2) NOT NULL,
hisal DECIMAL(17,2) NOT NULL
)ENGINE=MyISAM DEFAULT CHARSET=utf8;
#测试数据
INSERT INTO salgrade VALUES (1,700,1200);
INSERT INTO salgrade VALUES (2,1201,1400);
INSERT INTO salgrade VALUES (3,1401,2000);
INSERT INTO salgrade VALUES (4,2001,3000);
INSERT INTO salgrade VALUES (5,3001,9999);
#创建一个函数,名字 rand_string,可以随机返回我指定的个数字符串
create function rand_string(n INT)
returns varchar(255) #该函数会返回一个字符串
begin
#定义了一个变量 chars_str, 类型 varchar(100)
#默认给 chars_str 初始值 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ'
declare chars_str varchar(100) default
'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
declare return_str varchar(255) default '';
declare i int default 0;
while i < n do
# concat 函数 : 连接函数mysql函数
set return_str =concat(return_str,substring(chars_str,floor(1+rand()*52),1));
set i = i + 1;
end while;
return return_str;
end $$
#这里我们又自定了一个函数,返回一个随机的部门号
create function rand_num( )
returns int(5)
begin
declare i int default 0;
set i = floor(10+rand()*500);
return i;
end $$
创建一个存储过程, 可以添加雇员
create procedure insert_emp(in start int(10),in max_num int(10))
begin
declare i int default 0;
#set autocommit =0 把autocommit设置成0
#autocommit = 0 含义: 不要自动提交
set autocommit = 0; #默认不提交sql语句
repeat
set i = i + 1;
#通过前面写的函数随机产生字符串和部门编号,然后加入到emp表
insert into emp values ((start+i) ,rand_string(6),'SALESMAN',0001,curdate(),2000,400,rand_num());
until i = max_num
end repeat;
#commit整体提交所有sql语句,提高效率
commit;
end $$
添加8000000数据
call insert_emp(100001,8000000)$$
四、当数据海量时,问题和解决方法
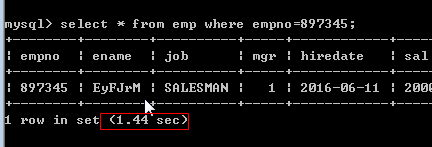
当查询这个海量表, 速度很慢了.
初步的解决方法是,创建索引:
alter table emp add index (empno);
测试看看效果怎么样

五、索引的原理
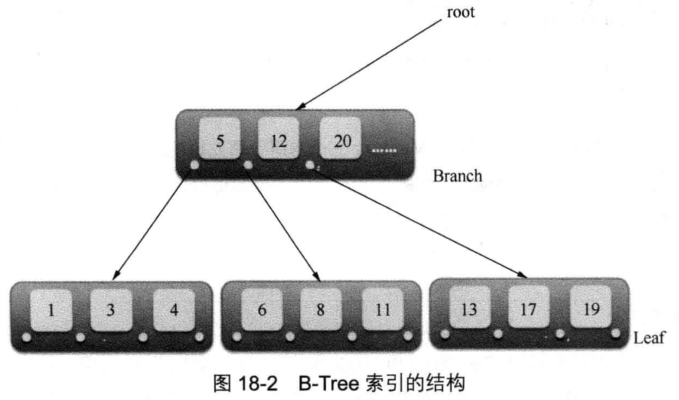
这里,我们讲解一个索引的基本原理。画图.
B-tree B不是代表二叉树(binary),而是代表(balanced)。B-tree索引并不是一颗二叉树。
六、不能使用索引的场景
- %开头的like查询
- 数据类型出现隐式转换的时候,如字符串类型必须在where子句中必须是字符串类型,即用单引号引起来,不能使用数字
- 复合索引下,查询条件不包含索引列最左部分,即不满足最左原则的,不会使用符合组件
- 如果mysql 估计使用索引比全表扫描更慢,则不使用
- 用or分割开的条件,如果or之前的条件中的列有索引,而后面的列没有,那么涉及的索引都不会被用到。因为后面的没有索引肯定是要全盘扫描的,那就没有必要多进行一次索引扫描增加I/O访问。
七、查看索引使用情况
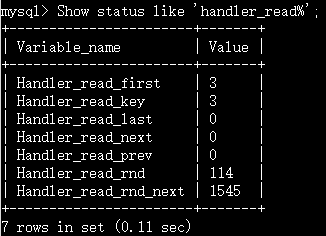
Handler_read_key 值代表了一个行被索引值读的次数,很低说明增加索引得到的性能改善不高,因为索引并不经常使用。如果索引在工作,值将很高。
Handler_read_rnd_next 值高以为这查询运行低效,应该建立索引。含义是在数据文件中读取下一行的请求数。如果正在进行大量的表扫描,handler_read_rnd_next的值很高,则通常说明表索引不正确或者写入的查询没有利用索引。
Show status like ‘handler_read%’;
八、创建索引
Create [ unique | fulltext | spatlal ] index index_name [ using index_type ] on tbl_name( index_col_name,…);
Alter table 表名 add index /unique/fulltext [索引名] (列名)
Alter table 表名 add primary key (列名) // 不要加索引名,因为主键只有一个
主键索引的创建:
第一种方式:

说明:在创建表时,直接在字段名后面指定 primary key
第二种方式:

说明:在创建表最后,指定某列,某几列为主键索引, 这里也可能是复合主键索引primary key(id,name);
第三种方式:

主键索引的特点:
一个表中,最多有一个主键索引,当然可以是复合主键.
主键索引的效率高
创建主键索引的列,它的值不能为null, 而且不能重复.
主键索引的列,基本上是int。
主键尽量选择较短的数据类型
唯一索引的创建:
第一种方式:

说明:在表定义时,某列后直接指定 unique 即可.
第二方式:

说明: 我们可以在表的定义后面指定某列,或者某几列为unique
第三种方式:

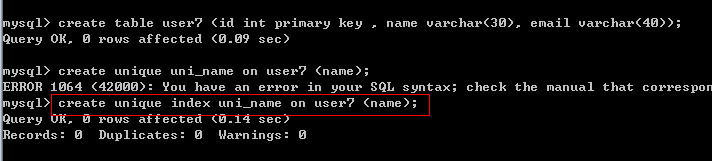
说明:上面两个方法,都是在创建表后,再指定唯一索引的.
唯一索引的特点:
一个表中,可以有多个唯一索引.
查询的效率很高.
如果你在某个字段上要创建唯一索引,必须保证这列的值不重复.
如果我们在唯一索引上在指定了 not null 约束,等价于一个主键索引.
普通索引的创建:
第一方式:

说明:在表的定义的最后指定某列为索引.
第二方式:


Create index mem_hash USING HASH on table_name(字段名);
Create index men_hash USING BTREE on table_name(字段名);
普通索引的特点:
一个表中可以有多个普通索引, 普通索引在实际开发中,使用的很多.
如果某列需要创建索引,但是该列有重复的值,那么我们就应该使用普通索引来搞定.
全文索引的创建:
基本介绍: 当我们对文章字段或者有大量文字的字段进行检索时,会使用到全文索引.mysql 提供全文索引的机制,但是要求 表的存储引擎是 MyISAM(5.6开始innodb支持), 而且默认全文索引支持英文,不支持中文,并且只限于char、varchar、text列。
如果对中文进行全文检索,可以使用 mysql的插件 mysqlcft, 或是使用sphinx 的中文版(coreseek).
快速入门案例
CREATE TABLE articles (
id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
title VARCHAR(200),
body TEXT,
FULLTEXT (title,body)
)engine = Myisam;

如何使用到我们创建的全文索引:
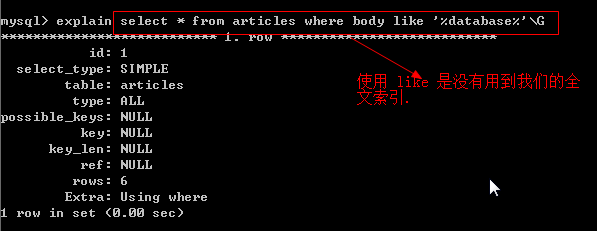
应该这样使用:
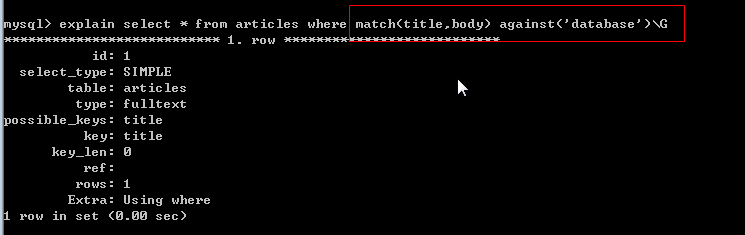
全文索引有几个概念[停止词、匹配度]
停止词: 全文索引不会对一般意义的单词建索引.

匹配度: mysql提供的全文索引机制,是以匹配度来返回结果.
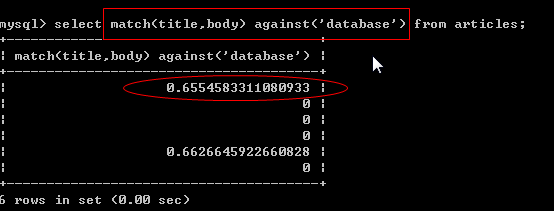
九、查询索引
show keys from 表名G
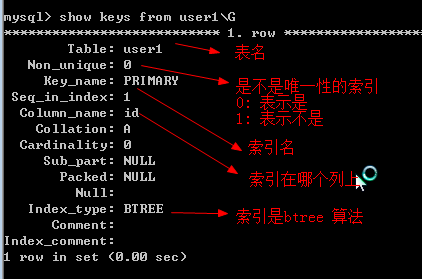
show index from 表名G
show indexes from 表名G
desc 表名;
show create table 表名;
十、 删除索引
删除主键
alter table 表名 drop primary key;
删除非主键索引
alter table 表名 drop index 索引名
说明:在删除索引前,先使用查看索引的指令,看key_name 是什么,然后再删除.
DROP INDEX index_name ON table_name;
重点是,先查找到要删除的索引的名字,然后再删除.
十一、修改索引
先删除,再创建.
十二、创建索引的基本原则

- 索引列的基数越大,索引的效果越好。
- 通过创建索引,可以大大的提高检索速度.
- 使用短索引
- 利用左前缀
在创建一个N列的索引时,实际是创建了MySQL可利用的n个索引,多列索引可起几个索引的作用,因为可以利用索引最左边的列集合来匹配行。
5. 不要过度索引,降低写操作的性能
6. Innodb 记录默认会按照一定的顺序保存,有主键按主键顺序保存,没有主键有唯一键,按唯一保存,既没有主键也没有唯一键,自动生成一个内部列。
主键或内部列进行的访问最快
Innodb表的普通索引会保存主键的键值,所以主键要尽可能选择较短的数据类型,减少索引磁盘占用,提高索引缓存效果