redis:
遇到什么问题?
当我们的系统引入了传统的缓存框架,比如(ehcache),因为ehcache等框架只是一个内置的缓存框架,所以前端的缓存和后台的(每一个webserver)的缓存都是独立存在的,加入一个缓存的数据发生了更新,其他缓存是不可能知道的,正阳对于乐观锁,总会提示失败;
在分布式环境下,缓存不能同步;
解决方案?
让缓存集中处理(大家使用同一个缓存服务),我们需要一个类似于MYSQL这样可以通过服务来提供第三方的缓存工具(缓存服务器),流行的第三方缓存服务器有:memcache、redis。
理解:
redis可以堪称一个Map(key-value),在redis中,所有的key都可以理解为byte[](string),
VALUE?在memcache中,value也只能是byte[](string); ----------------> Map<String,String> 。
在redis中,value的可选类型很多,string,list,set,orderset,hash,Map<String,String>,Map<String,Set>,Map<String,String>,Map<String,Map<>>
redis的优势:
性能极高 ---- Redis能支持超过10w美妙的读写频率
丰富的数据类型 ---- Redis支持二进制案例的Strings,Lists,Hashes,Sets及OrderedSets数据类型操作。
原子 ---- Redis的所有操作都是原子性的,同事Redis还支持对几个操作合并后的源自性执行(简单的事务)。
丰富的特性 ---- Redis还支持publish/subscribe(发布/订阅),通知,key过期等等特性。
Redis的理念:
我们常用的数据库:关系型数据库,面向对象数据库,NoSQL(Not only SQL) --> (key-value)内存数据库;
redis是一个key-value的内存存储应用(使用redis主要还是吧数据存在内存中,这个可以最大的使用redis的性能优势);
redis可以把数据存储在内存中,也可以持久化到磁盘上;
redis不是一个适用于任何场景的存储应用;
redis不光可以作为一个缓存,还是一个搞笑的额内存数据库;可以在某些情况下,高效的替换到传统的关系型数据库,非常好的处理高并发高请求的场景;
学redis:
redis在线入门:http://try.redis.io/
redis中文资料站:http://www.redis.cn
redis命令手册:http://www.redisdoc.com
redis入门
两个最基本的redis命令:
SET KEY VALUE : 把VALUE保存到redis中KEY对应的值;
GET KEY : 取出redis中KEY对应的值。
关于redis中的key:
在示例中,key的值为server:name ,代表server的name,这是redis中key取名的一个规范;
我们之前说到redis不光是一个缓存,还可以看作一个数据库,这种数据库和传统的关系型数据库最大的区别就在于,传统的关系型数据库,再保存数据库之前,都已经有一个固定的schema;内容是保存在一个schema中不同行的数据;所欲的数据都存在一张指定的表中,所有的内容都对应表里的一个指定行,每一个行都有固定的数据类型;
所以,当我们在使用关系型数据表表现一个对象(数据结构的时候),我们能够事前通过schema规范好这个对象的结构;
比如,要表现User这个对象,只需要创建一个user表,在表里面创建id、name、password桑额咧,在保存数据时。就是直接把数据保存到这个表中对应的列中,要查询id为1的user,可以通过select语句去表的内容中进行结构化的筛选;
但是,对于redis来说,整个数据库就是一个Map,没有任何结构而言,所有通过set等方法扔到redis中的数据,可以简单理解为就是所有的数据乱七八糟的放在一个map中;
问题:在redis中,怎么存储一个user?怎么检索?(Map能不能通过value查询???不能,换那句话说,在redis中,要能够支持查询的属性,都必须反映在key上)
即redis的作用:1、反映数据的结构;2、反映查询的内容。
redis的版本:
目前稳定的最新版时3.2;
redis时*Unix的一个用,我们在开发中使用的windows版本不是官方的,时微软开源提供的,每一个版本都对应一个linux版本的redis;
注意32位和64位版本的区别。
redis的基本概念
1、redis也有数据库的概念,一个数据库中可以保存一组数据;
2、哥哥数据之间时相互隔离的,当然也可以在不同数据库之间复制数据
3、一般一个应用会单独使用一个数据库;
4、每一个数据库都有一个id号,默认的数据id为0;
5、可以使用select命令选择当前使用的数据库;
6、redis 默认为我们创建16个数据库,这个参数可以在redis配置文件中使用databases来修改.
Command(命令)
1、redis中提供了非常大量和的命令来方便二点操作数据库中的数据,还可以使用redis中的一些特性;
2、redis的命令可以简单理解为mysql的SQL命令;
3、redis命令分为
- 数据库的操作;
- 发布/订阅相关操作;
- 失误操作;
- 脚本命令;
- 连接服务器命令;
- 数据库服务相关命令;

KEY-VALUE
1、key用来标记一个数据;一般在key中需要尽量标明数据的名字(还可以用key来表明数据所属类型),比如用于标示一个对象的额时候,可以使用user:1000来作为key,代表id为1000的用过户对象;
2、value用来表示一个key对应的值;在redis中,数据可以是任何内容,redis把所有的value都作为byte来处理;所以可以用来保存任何内容;
例子:像redis中存储一个json字符串;
set user:1'{"id":1,"name":"stef","age":18}'
获得这个值:
get user:1
3、redis最突出的特点是提供了5中常用的数据存储类型(value的类型),深刻理解这5种数据结构和各自的使用场景,对redis的使用有很大帮助;
Query(检索)
1、在redis中,不支持对value进行任何形式的查询;
例如:保存一个user:
set user:1'{name:"hello",id:1}'
是无法通过redis去查询name为hello的user要查询的内容,只能反映在key值上,所以如果要按照用户的name查询,只能再添加一条数据;
set user:name:stef 1
2、redis不是一个适用于任何场景的存储方案,考虑使用redis需要对业务进行考评,用redis的思想去重新涉及数据结构;
存储
1、redis可以作为内存数据库,也可以把数据持久化到磁盘上;大部分情况下,都是把redis作为内存数据库。
2、默认情况下,redis每60秒/1000数据修改或者15分钟/9个以下key修改;
在redis配置文件中:
save 500 1
save 300 10
save 60 10000
3、数据默认存储在安装目录下,rdb文件中(可以在配置文件中dbfilenamedump.rdb配置);
4、redis也可以设置为append模式,每次key的修改都会append到文件中,这种方式有可能丢失60秒的数据;
- 通过配置:appendonly yes 开启
- appendfilename "appendonlyaof"设置append文件;
- 可以设置append模式(类似于mysql的事务文件同步机制);
- appendfsync always:每次更新key及时同步到append文件;
- appendfsync everysec:每一秒同步一次jkey的更新
- appendfsync no:不管理append文件的更新,根据操作系统去定。
- appendfsync always:每次更新key及时同步到append文件;
redis中的数据结构:
redis中丰富的数据机构是redis区别memecache等其他NOSQL的一个重要优势;学习redis中的5种数据结构对使用redis有非常大的帮助;
怎么学习redis中的数据结构和相关的额操作;
1、熟悉数据结构的意义,最简单的方法和c++/java的数据类型对比;
2、了解数据结构常用的一些命令(看文档,学会看懂文档中命令的意思和使用方式)
3、尝试使用这些命令,做简单的实验(可以不需要场景,就只是看结果);
4、了解该数据结构的使用场景(文档/网上资料),设计一个具体的场景,使用有效的命令完成场景操作;
5、了解该数据结构的实现原理,了解二数据结构的执行效率(进阶)
Redis中的string:
1、redis中最常见的数据类型;内容可以是任何值(因为string对应着byte[]);
2、可以通过set key value添加一个值;
3、常见的字符串操作:
- strlen key: : 返回key的value的值长度;
- getrange key X Y : 返回key对应value的一个子字符串,位置从x到y;
- append key value : 给key对应的value追加值,如果key不存在,相当于set一个新的值;
4、如果字符串的内容是数值(integer,在redis中,数值也是string)
- incr key : 给定key的value上增加1;(常用于id);redis中的一个源自操作,支持并发;如果key不存在,则相当于设置1;
- incrby key value:给定key的value上增加value值;相当于key=key.value+value;也是一个原子操作;
- decr : 给定key的value上减1;
- decrby key value : 给定key的value上减value值;

5、string最常见的使用场景:
存储json类型对象
incr user:id
set user:1 {id:1,name:alex}
incr user:id
set user:2 {id:2,name:cthon}
作为计数器,
incr count;
优酷视频点赞
incr vedio:100:goodcount (id为100的视频点赞数加1)
decr vedio:100:goodcount(id为100的视频点赞数减1)
redis中的list
1、redi的list结构,是一个双向链表,可以用来存储一组数据;从这个列表的前端和后端取数据效率非常高;
2、list的常用操作:
- RPUSH:在一个list最后面添加一个元素
- RPUSH friends "stef"
- LPUSH:在一个list最前面添加一个元素
- LPUSH friends "stea"
- LTRIM key start stop:剪裁一个列表,剩下的内容从start到stop;
- LTRIM friends 0,3 => 只剩下前4个数据
- LRANGE :获取列表中的一部分数据,两个参数,第一个参数代表第一个获取元素的位置<0>开始,第二个值代表截至的元素位置,如果第二个参数为-1,戒指到列表尾部;
- LRANGE friends 0 -1
- LLEN:返回一个列表当前长度
- LLEN friends
- LPOP:移除list中第一个元素,并返回这个元素
- LPOP friends
- RPOP:移除list中最后一个元素,并返回这个元素
- RPOP friends

3、list使用场景
场景一:可以使用list模拟队列,堆,栈
场景二:微博/微信朋友圈点赞
规定:朋友圈内容的格式
1、内容:user:x:post:x content 来存储
2、点赞:post:x:good list 来存储
- 创建一条微博内容:set user:1:post:91 "hello redis"
- 点赞:
- lpush post:91:good '{id:1,name:stef,img:xxx.jpg}'
-
lpush post:91:good '{id:1,name:x1,img:xxx.jpg}'
- lpush post:91:good '{id:1,name:xm,img:xxx.jpg}'
- 查看有多少人点赞:llen post:91:good
- 查看有哪些人点赞:lrange post:91:good 0 -1
思考:如果用数据库实现这个功能,SQL会多复杂?
场景三:回帖
- 创建一个帖子:set user:1:post:90 'wohenshuai'
- 创建一个回帖:set postreply:1 'nonono'
- 把回帖和帖子关联:lpush post:90:replies 1
- 再来一条回帖:set postreply:2 'hehe'
-
- lpush post:90:replies 2
-
- 查询帖子的回帖:lrange post:90:replies 0 -1
-
- get postreply:1
-
redis中的set
1、结构和java中差不多,数据没有顺序,并且每一个值不能重复;
2、set结构的常见操作:
- SADD:给set添加一个元素
- SADD language 'java'
- SREM:从set中移除一个给定元素
- SREM language 'php'
- SISMEMBER:怕那段给定的一个元素是否在set中,如果存在,返回1,如果不存在,返回0;
- sismember language 'php'
- SMEMBERS:返回指定set内所有的元素,以一个list形式返回
- smembers language
- SCARD:返回set的元素个数
- scard language
- SRANDMEMBER key count:返回指定set中随机的count个元素
- srandmember friends 3 //随机推荐3个用户(典型场景,抽奖)
- SUNION:综合多个set的内容,并返回一个list的列表,包含综合后的所有元素;
- safdd language 'php'
- sadd pg 'c'
- sadd pg 'c++'
- sadd pgs 'java'
- sadd pgs 'swift'
- sunion language pg pgs
- SINTER key [key ...]:获取多个key对应的key之间的交集
- SINTER friends:user:100 friends:user:1001 friends:user:1002 => 获取1000,1001,1002三个用户的共同好友列表;
- SINTERSTORE destination key [key ... ] :获取多个key对应的set之间的交集,并保存为新的key值;目标也是一个set;
- SINTER groupfriends friends:user:1000 friends:user:1001 friends:user:1002 => 获取三个用户共同的好友列表并保持存为组好友列表;

3、set的使用场景
- 去重
- 抽奖
- 准备一个抽奖池:
- sadd luckdraws 1 2 3 4 5 6 7 8 9 10 11 12 13
- 抽三个三等奖:
- srandmember luckdraws 3
- srem luckdraws 11 1 10
- 抽2个二等奖:
- 准备一个抽奖池:
- 做set运算(好友推荐)
- 初始化好友圈
- sadd user:1:friends 'user:2' 'user:3' 'user:5'
- sadd user:2:friends 'user:1' 'user:3' 'user:6'
- sadd user:3:friends 'user:1' 'user:7' 'user:8'
- 把user:1的好友的好友集合做并集;
- user:1 user:3 user:6 user :7 user:8
- sunionstore user:1:maybe:group user:2:friends user:3:friends
- smembers user:1:maybe:group
- 让这个并集和user:1的好友集合和这个并集做差集;
- user:1 user:6 user:7 user:8
- sdiffstore user:1:maybe:group user:1:maybe:group user:1:friends
-
- smembers user:1:maybe:group
- 从差集中去掉自己
- user:6 user:7 user:8
- srem user:1:maybe:group user:1
- 随机选取推荐好友
- srandmember user:1:maybe:group 2
- 初始化好友圈
redis中的sorted-set(又叫zset)
1、set是一种非常方便的结构,但是数据无序,redis提供了一个sorted set,每一个添加的值都有一个对应的分数,可以通过这个分数进行排序
2、sortedset的常用操作:
- ZADD:添加一个带分数的元素,也可以同事添加多个:
- ZADD hackers 1940 "Alan Kay"
- ZADD hackers 1906 "Grace Hopper"
- ZADD hackers 1969 “Linux Torvalds”
- ZADDhackers 1940 "Alan kay" 1960 "Grace Hopper" 1969 "Linux Torvalds"
- ZCOUNT key min max : 给定范围分数的元素个数
- ZCOUNT hackers 1940 1960 => 1940到1960的hacker个数
- ZRANK key member : 查询指定元素的分数在整个列表中的排名(从0开始)
- ZRANK hackers “Alan Kay" => alan kay 的年龄在所有hacker中的排名;
- zrange hacke 0 -1 =>
- "Grace Hopper"
- "Alan Kay"
- "Linus Torvald"
- ZREVERANGE key start stop :按照分数从小到大排序

3、sorted set 的使用场景:sorted set算是redis中最有用的一种结构,非常适合用于做海量数据的排行(比如一个巨型游戏的用户排名);sorted set中所有的方法都建议学一下;sortedset的速度非常快;
示例1:
- 天梯排名:
- 添加初始排名和分数;
- 查询fat在当前adder中的排名;
- 查询ladder中的前3名;
- steb增加了20ladder score;
示例2:FIFO LIFO
- LRU淘汰最长时间没使用;
- LFU淘汰最低使用频率;
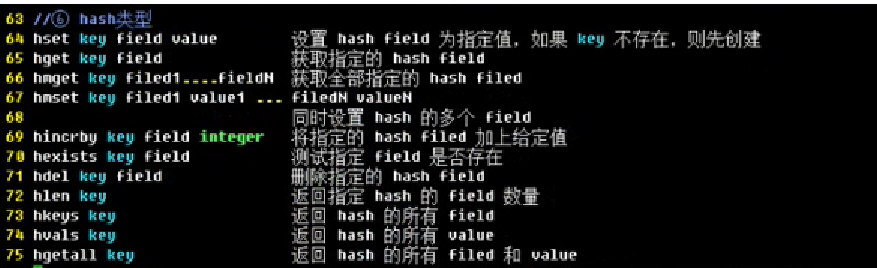
redis中的hash
1、hashes可以理解为一个map,这个map有一对一对的字段和值组成,所以,可以用hashes来保存一个对象;
2、hashes的常见操作:
- HSET : 给一个hasheds添加一个field和value;
- HSET user:1000 name "John Smith"
- HSET user:1000 email "john.smith@example.com"
- HSET user:1000 password "s3cret"
- HGET : 可以得到一个hashes中的某一个属性的值;
- HGET user:1000 password "s3cret"
- HGETALL : 一次性取出一个hashes中所有的field和value,使用list输出,一个filed,一个calue有序输出;
- HGETALL user:1000 =>
- "name"
- "John Smith"
- "email"
- "john.smith@example.com"
- "password"
- "s3cret"
- HGETALL user:1000 =>
- HMSET : 一次习惯的设置多个值(hashes multiple set)
- HMSET user:1001 name "Mary Hones" password "hidden" email "mjones@example.com"
- HMGET : 一次性得到多个字段值(hashes multiple get),列表形式返回;
- HMGET user:1001 name email =>
- "Mary Jones"
- "mjones@example.com"
- HMGET user:1001 name email =>
- HINCRBY : 给hashes的一个field的value值增加一个值(integer),这个增加操作时原子操作
- HSET user:1000 visits 10
- HINCRBY user:1000 visits 1 =>11
- HINCRBY user:1000 visits 10 => 21
- HKEYS : 得到一个key的所有fields字段,以list返回:
- "name"
- "password"
- "email"
- HDEL : 删除hashes一个指定的field;
- HDEL user:1000 visits
hash的使用场景:
1、使用hash来保存一个对象更直观;(建议不适用hash来保存)
2、分组
- set user:id 1
- set dept:id 1
- HMSET ids user:id 1 dept:id 1 orderbill:id 1
- HINCRBY ids user:id
- HINCRBY ids dept:id
- HMSET users user:1 "{id:1,name:xx}" user:2"{id:2,name:xx}"
JAVA中对redis进行操作----jedis